 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUpgrade or Switch: Do We Need a New Registry Architecture for the Internet of AI Agents?
Jun 13, 2025The emerging Internet of AI Agents challenges existing web infrastructure designed for human-scale, reactive interactions. Unlike traditional web resources, autonomous AI agents initiate actions, maintain persistent state, spawn sub-agents, and negotiate directly with peers: demanding millisecond-level discovery, instant credential revocation, and cryptographic behavioral proofs that exceed current DNS/PKI capabilities. This paper analyzes whether to upgrade existing infrastructure or implement purpose-built registry architectures for autonomous agents. We identify critical failure points: DNS propagation (24-48 hours vs. required milliseconds), certificate revocation unable to scale to trillions of entities, and IPv4/IPv6 addressing inadequate for agent-scale routing. We evaluate three approaches: (1) Upgrade paths, (2) Switch options, (3) Hybrid registries. Drawing parallels to dialup-to-broadband transitions, we find that agent requirements constitute qualitative, and not incremental, changes. While upgrades offer compatibility and faster deployment, clean-slate solutions provide better performance but require longer for adoption. Our analysis suggests hybrid approaches will emerge, with centralized registries for critical agents and federated meshes for specialized use cases.
On the limits of agency in agent-based models
Sep 14, 2024Agent-based modeling (ABM) seeks to understand the behavior of complex systems by simulating a collection of agents that act and interact within an environment. Their practical utility requires capturing realistic environment dynamics and adaptive agent behavior while efficiently simulating million-size populations. Recent advancements in large language models (LLMs) present an opportunity to enhance ABMs by using LLMs as agents with further potential to capture adaptive behavior. However, the computational infeasibility of using LLMs for large populations has hindered their widespread adoption. In this paper, we introduce AgentTorch -- a framework that scales ABMs to millions of agents while capturing high-resolution agent behavior using LLMs. We benchmark the utility of LLMs as ABM agents, exploring the trade-off between simulation scale and individual agency. Using the COVID-19 pandemic as a case study, we demonstrate how AgentTorch can simulate 8.4 million agents representing New York City, capturing the impact of isolation and employment behavior on health and economic outcomes. We compare the performance of different agent architectures based on heuristic and LLM agents in predicting disease waves and unemployment rates. Furthermore, we showcase AgentTorch's capabilities for retrospective, counterfactual, and prospective analyses, highlighting how adaptive agent behavior can help overcome the limitations of historical data in policy design. AgentTorch is an open-source project actively being used for policy-making and scientific discovery around the world. The framework is available here: github.com/AgentTorch/AgentTorch.
First 100 days of pandemic; an interplay of pharmaceutical, behavioral and digital interventions -- A study using agent based modeling
Jan 09, 2024



Pandemics, notably the recent COVID-19 outbreak, have impacted both public health and the global economy. A profound understanding of disease progression and efficient response strategies is thus needed to prepare for potential future outbreaks. In this paper, we emphasize the potential of Agent-Based Models (ABM) in capturing complex infection dynamics and understanding the impact of interventions. We simulate realistic pharmaceutical, behavioral, and digital interventions that mirror challenges in real-world policy adoption and suggest a holistic combination of these interventions for pandemic response. Using these simulations, we study the trends of emergent behavior on a large-scale population based on real-world socio-demographic and geo-census data from Kings County in Washington. Our analysis reveals the pivotal role of the initial 100 days in dictating a pandemic's course, emphasizing the importance of quick decision-making and efficient policy development. Further, we highlight that investing in behavioral and digital interventions can reduce the burden on pharmaceutical interventions by reducing the total number of infections and hospitalizations, and by delaying the pandemic's peak. We also infer that allocating the same amount of dollars towards extensive testing with contact tracing and self-quarantine offers greater cost efficiency compared to spending the entire budget on vaccinations.
SARC: Soft Actor Retrospective Critic
Jun 28, 2023


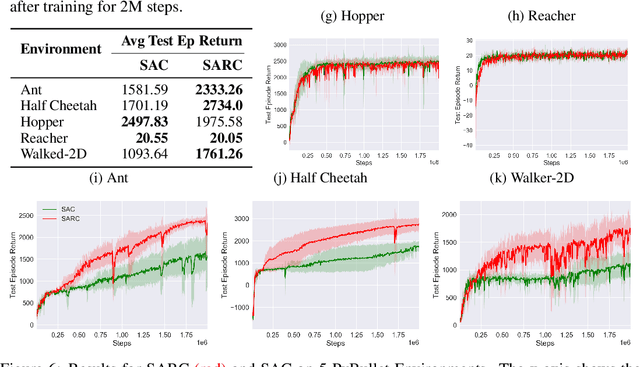
The two-time scale nature of SAC, which is an actor-critic algorithm, is characterised by the fact that the critic estimate has not converged for the actor at any given time, but since the critic learns faster than the actor, it ensures eventual consistency between the two. Various strategies have been introduced in literature to learn better gradient estimates to help achieve better convergence. Since gradient estimates depend upon the critic, we posit that improving the critic can provide a better gradient estimate for the actor at each time. Utilizing this, we propose Soft Actor Retrospective Critic (SARC), where we augment the SAC critic loss with another loss term - retrospective loss - leading to faster critic convergence and consequently, better policy gradient estimates for the actor. An existing implementation of SAC can be easily adapted to SARC with minimal modifications. Through extensive experimentation and analysis, we show that SARC provides consistent improvement over SAC on benchmark environments. We plan to open-source the code and all experiment data at: https://github.com/sukritiverma1996/SARC.
Bayesian calibration of differentiable agent-based models
May 24, 2023Agent-based modelling (ABMing) is a powerful and intuitive approach to modelling complex systems; however, the intractability of ABMs' likelihood functions and the non-differentiability of the mathematical operations comprising these models present a challenge to their use in the real world. These difficulties have in turn generated research on approximate Bayesian inference methods for ABMs and on constructing differentiable approximations to arbitrary ABMs, but little work has been directed towards designing approximate Bayesian inference techniques for the specific case of differentiable ABMs. In this work, we aim to address this gap and discuss how generalised variational inference procedures may be employed to provide misspecification-robust Bayesian parameter inferences for differentiable ABMs. We demonstrate with experiments on a differentiable ABM of the COVID-19 pandemic that our approach can result in accurate inferences, and discuss avenues for future work.
Differentiable Agent-based Epidemiology
Jul 20, 2022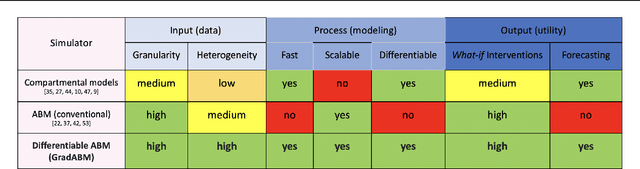
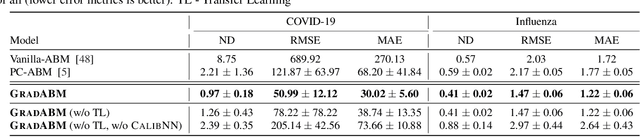
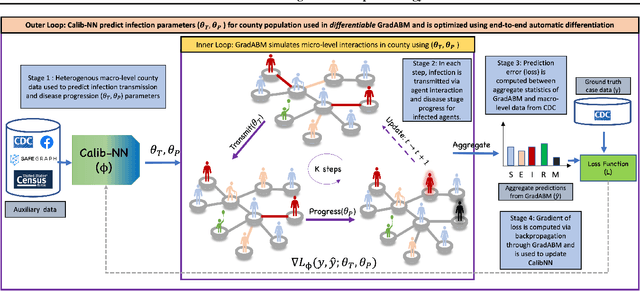

Mechanistic simulators are an indispensable tool for epidemiology to explore the behavior of complex, dynamic infections under varying conditions and navigate uncertain environments. ODE-based models are the dominant paradigm that enable fast simulations and are tractable to gradient-based optimization, but make simplifying assumptions about population homogeneity. Agent-based models (ABMs) are an increasingly popular alternative paradigm that can represent the heterogeneity of contact interactions with granular detail and agency of individual behavior. However, conventional ABM frameworks are not differentiable and present challenges in scalability; due to which it is non-trivial to connect them to auxiliary data sources easily. In this paper we introduce GradABM which is a new scalable, fast and differentiable design for ABMs. GradABM runs simulations in few seconds on commodity hardware and enables fast forward and differentiable inverse simulations. This makes it amenable to be merged with deep neural networks and seamlessly integrate heterogeneous data sources to help with calibration, forecasting and policy evaluation. We demonstrate the efficacy of GradABM via extensive experiments with real COVID-19 and influenza datasets. We are optimistic this work will bring ABM and AI communities closer together.
On Conditioning the Input Noise for Controlled Image Generation with Diffusion Models
May 08, 2022
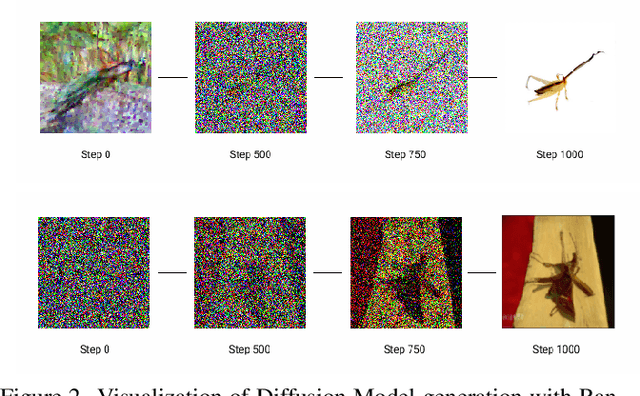


Conditional image generation has paved the way for several breakthroughs in image editing, generating stock photos and 3-D object generation. This continues to be a significant area of interest with the rise of new state-of-the-art methods that are based on diffusion models. However, diffusion models provide very little control over the generated image, which led to subsequent works exploring techniques like classifier guidance, that provides a way to trade off diversity with fidelity. In this work, we explore techniques to condition diffusion models with carefully crafted input noise artifacts. This allows generation of images conditioned on semantic attributes. This is different from existing approaches that input Gaussian noise and further introduce conditioning at the diffusion model's inference step. Our experiments over several examples and conditional settings show the potential of our approach.
Learning to Censor by Noisy Sampling
Mar 23, 2022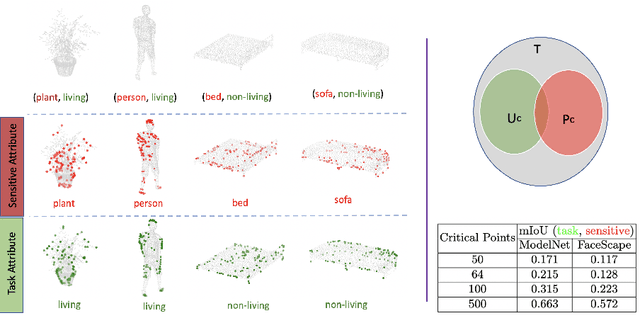
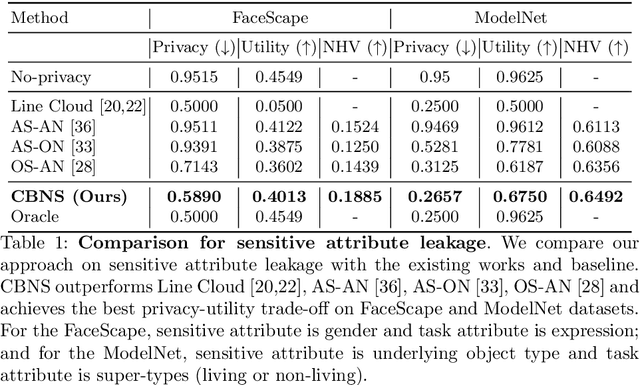

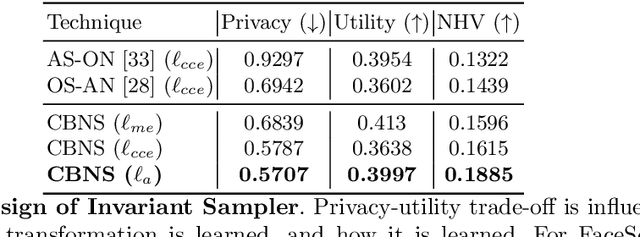
Point clouds are an increasingly ubiquitous input modality and the raw signal can be efficiently processed with recent progress in deep learning. This signal may, often inadvertently, capture sensitive information that can leak semantic and geometric properties of the scene which the data owner does not want to share. The goal of this work is to protect sensitive information when learning from point clouds; by censoring the sensitive information before the point cloud is released for downstream tasks. Specifically, we focus on preserving utility for perception tasks while mitigating attribute leakage attacks. The key motivating insight is to leverage the localized saliency of perception tasks on point clouds to provide good privacy-utility trade-offs. We realize this through a mechanism called Censoring by Noisy Sampling (CBNS), which is composed of two modules: i) Invariant Sampler: a differentiable point-cloud sampler which learns to remove points invariant to utility and ii) Noisy Distorter: which learns to distort sampled points to decouple the sensitive information from utility, and mitigate privacy leakage. We validate the effectiveness of CBNS through extensive comparisons with state-of-the-art baselines and sensitivity analyses of key design choices. Results show that CBNS achieves superior privacy-utility trade-offs on multiple datasets.
Decouple-and-Sample: Protecting sensitive information in task agnostic data release
Mar 17, 2022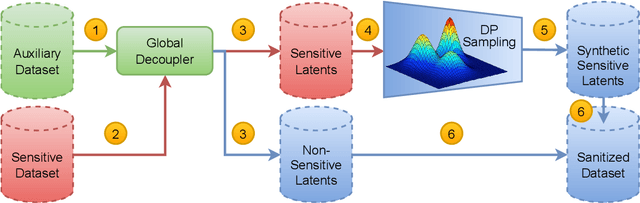
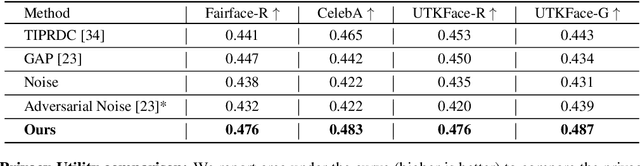
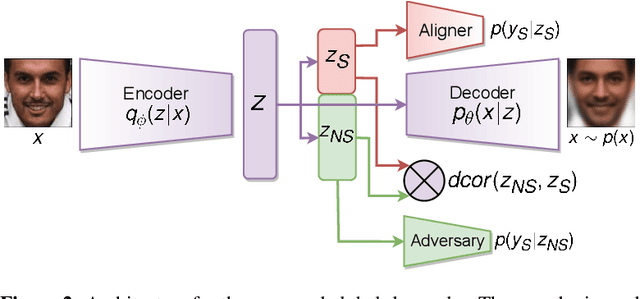

We propose sanitizer, a framework for secure and task-agnostic data release. While releasing datasets continues to make a big impact in various applications of computer vision, its impact is mostly realized when data sharing is not inhibited by privacy concerns. We alleviate these concerns by sanitizing datasets in a two-stage process. First, we introduce a global decoupling stage for decomposing raw data into sensitive and non-sensitive latent representations. Secondly, we design a local sampling stage to synthetically generate sensitive information with differential privacy and merge it with non-sensitive latent features to create a useful representation while preserving the privacy. This newly formed latent information is a task-agnostic representation of the original dataset with anonymized sensitive information. While most algorithms sanitize data in a task-dependent manner, a few task-agnostic sanitization techniques sanitize data by censoring sensitive information. In this work, we show that a better privacy-utility trade-off is achieved if sensitive information can be synthesized privately. We validate the effectiveness of the sanitizer by outperforming state-of-the-art baselines on the existing benchmark tasks and demonstrating tasks that are not possible using existing techniques.
AdaSplit: Adaptive Trade-offs for Resource-constrained Distributed Deep Learning
Dec 02, 2021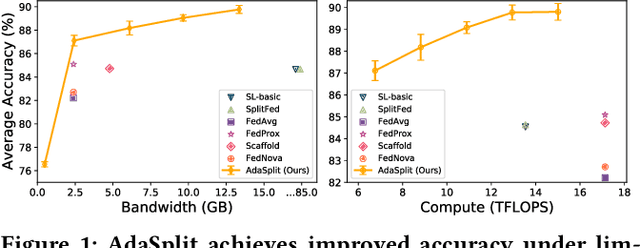
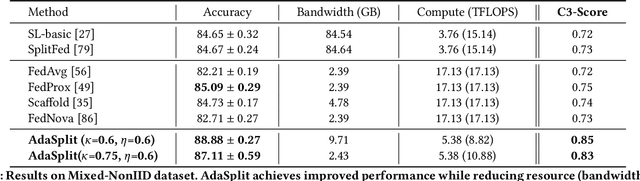
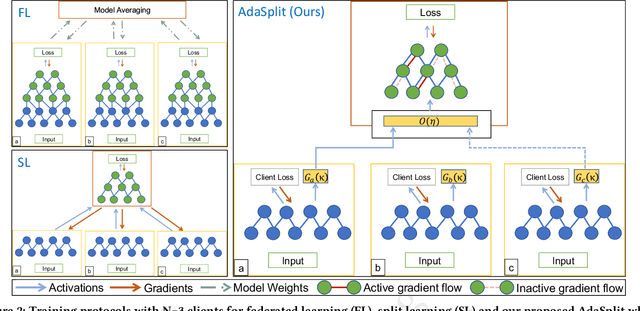
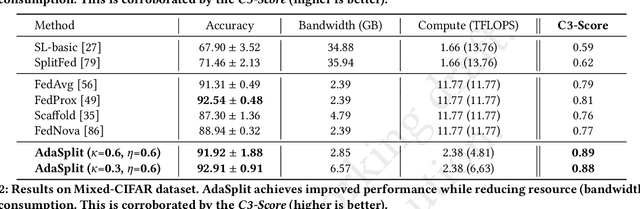
Distributed deep learning frameworks like federated learning (FL) and its variants are enabling personalized experiences across a wide range of web clients and mobile/IoT devices. However, FL-based frameworks are constrained by computational resources at clients due to the exploding growth of model parameters (eg. billion parameter model). Split learning (SL), a recent framework, reduces client compute load by splitting the model training between client and server. This flexibility is extremely useful for low-compute setups but is often achieved at cost of increase in bandwidth consumption and may result in sub-optimal convergence, especially when client data is heterogeneous. In this work, we introduce AdaSplit which enables efficiently scaling SL to low resource scenarios by reducing bandwidth consumption and improving performance across heterogeneous clients. To capture and benchmark this multi-dimensional nature of distributed deep learning, we also introduce C3-Score, a metric to evaluate performance under resource budgets. We validate the effectiveness of AdaSplit under limited resources through extensive experimental comparison with strong federated and split learning baselines. We also present a sensitivity analysis of key design choices in AdaSplit which validates the ability of AdaSplit to provide adaptive trade-offs across variable resource budgets.