 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Conditioning the Input Noise for Controlled Image Generation with Diffusion Models
May 08, 2022
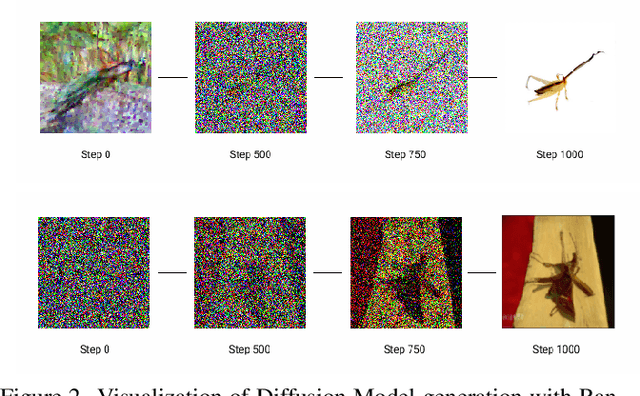


Conditional image generation has paved the way for several breakthroughs in image editing, generating stock photos and 3-D object generation. This continues to be a significant area of interest with the rise of new state-of-the-art methods that are based on diffusion models. However, diffusion models provide very little control over the generated image, which led to subsequent works exploring techniques like classifier guidance, that provides a way to trade off diversity with fidelity. In this work, we explore techniques to condition diffusion models with carefully crafted input noise artifacts. This allows generation of images conditioned on semantic attributes. This is different from existing approaches that input Gaussian noise and further introduce conditioning at the diffusion model's inference step. Our experiments over several examples and conditional settings show the potential of our approach.
On Saliency Maps and Adversarial Robustness
Jul 13, 2020
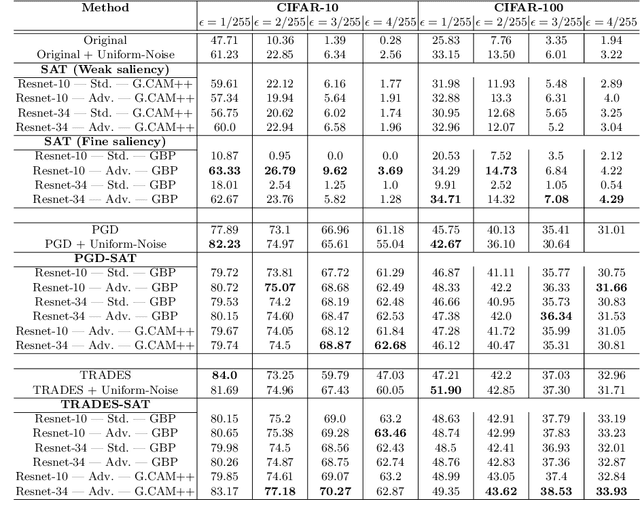
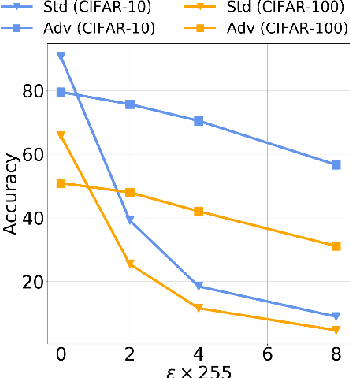
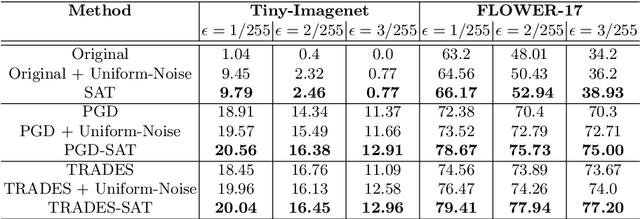
A Very recent trend has emerged to couple the notion of interpretability and adversarial robustness, unlike earlier efforts which solely focused on good interpretations or robustness against adversaries. Works have shown that adversarially trained models exhibit more interpretable saliency maps than their non-robust counterparts, and that this behavior can be quantified by considering the alignment between input image and saliency map. In this work, we provide a different perspective to this coupling, and provide a method, Saliency based Adversarial training (SAT), to use saliency maps to improve adversarial robustness of a model. In particular, we show that using annotations such as bounding boxes and segmentation masks, already provided with a dataset, as weak saliency maps, suffices to improve adversarial robustness with no additional effort to generate the perturbations themselves. Our empirical results on CIFAR-10, CIFAR-100, Tiny ImageNet and Flower-17 datasets consistently corroborate our claim, by showing improved adversarial robustness using our method. saliency maps. We also show how using finer and stronger saliency maps leads to more robust models, and how integrating SAT with existing adversarial training methods, further boosts performance of these existing methods.
VarMixup: Exploiting the Latent Space for Robust Training and Inference
Mar 14, 2020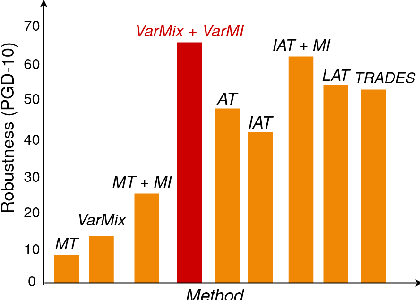

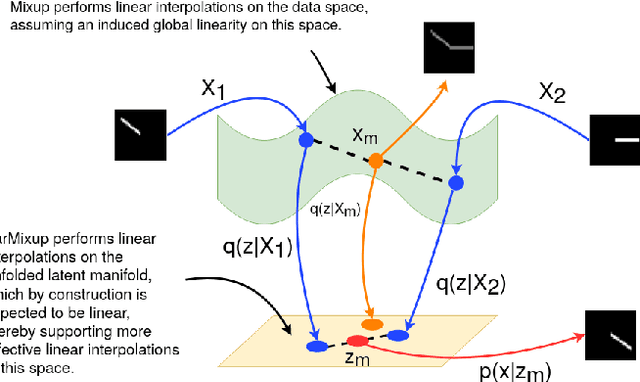
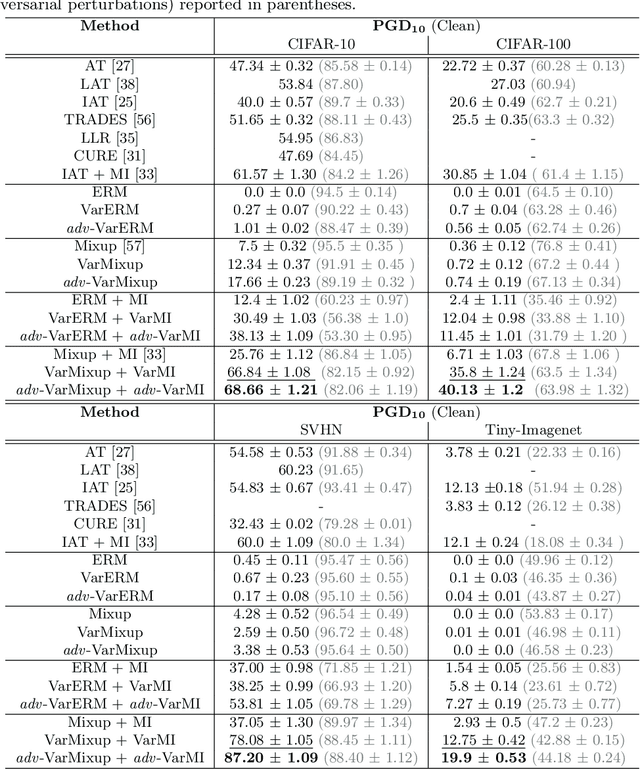
The vulnerability of Deep Neural Networks (DNNs) to adversarial attacks has led to the development of many defense approaches. Among them, Adversarial Training (AT) is a popular and widely used approach for training adversarially robust models. Mixup Training (MT), a recent popular training algorithm, improves the generalization performance of models by introducing globally linear behavior in between training examples. Although still in its early phase, we observe a shift in trend of exploiting Mixup from perspectives of generalisation to that of adversarial robustness. It has been shown that the Mixup trained models improves the robustness of models but only passively. A recent approach, Mixup Inference (MI), proposes an inference principle for Mixup trained models to counter adversarial examples at inference time by mixing the input with other random clean samples. In this work, we propose a new approach - \textit{VarMixup (Variational Mixup)} - to better sample mixup images by using the latent manifold underlying the data. Our experiments on CIFAR-10, CIFAR-100, SVHN and Tiny-Imagenet demonstrate that \textit{VarMixup} beats state-of-the-art AT techniques without training the model adversarially. Additionally, we also conduct ablations that show that models trained on \textit{VarMixup} samples are also robust to various input corruptions/perturbations, have low calibration error and are transferable.
Auto-Encoding Progressive Generative Adversarial Networks For 3D Multi Object Scenes
Mar 08, 2019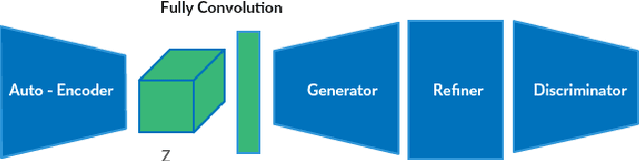
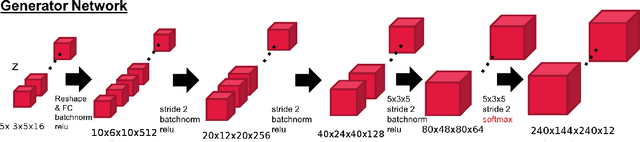
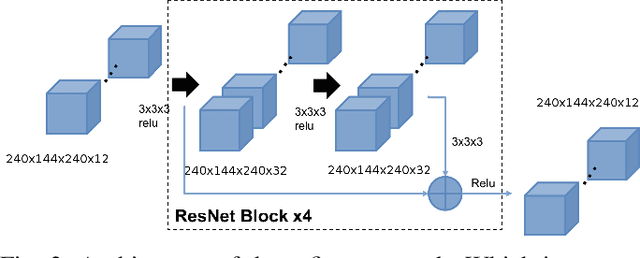

3D multi object generative models allow us to synthesize a large range of novel 3D multi object scenes and also identify objects, shapes, layouts and their positions. But multi object scenes are difficult to create because of the dataset being multimodal in nature. The conventional 3D generative adversarial models are not efficient in generating multi object scenes, they usually tend to generate either one object or generate fuzzy results of multiple objects. Auto-encoder models have much scope in feature extraction and representation learning using the unsupervised paradigm in probabilistic spaces. We try to make use of this property in our proposed model. In this paper we propose a novel architecture using 3DConvNets trained with the progressive training paradigm that has been able to generate realistic high resolution 3D scenes of rooms, bedrooms, offices etc. with various pieces of furniture and objects. We make use of the adversarial auto-encoder along with the WGAN-GP loss parameter in our discriminator loss function. Finally this new approach to multi object scene generation has also been able to generate more number of objects per scene.