 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Conditioning the Input Noise for Controlled Image Generation with Diffusion Models
Paper and Code
May 08, 2022
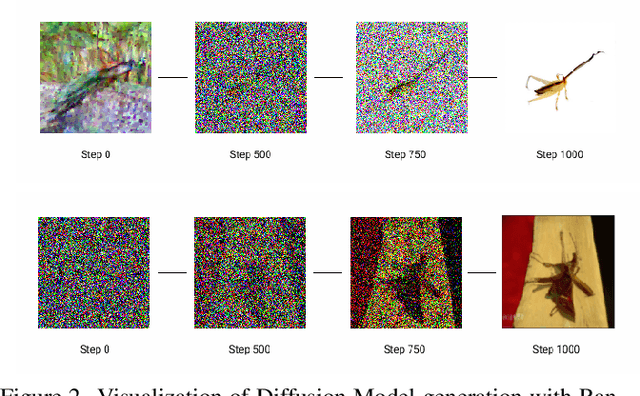


Conditional image generation has paved the way for several breakthroughs in image editing, generating stock photos and 3-D object generation. This continues to be a significant area of interest with the rise of new state-of-the-art methods that are based on diffusion models. However, diffusion models provide very little control over the generated image, which led to subsequent works exploring techniques like classifier guidance, that provides a way to trade off diversity with fidelity. In this work, we explore techniques to condition diffusion models with carefully crafted input noise artifacts. This allows generation of images conditioned on semantic attributes. This is different from existing approaches that input Gaussian noise and further introduce conditioning at the diffusion model's inference step. Our experiments over several examples and conditional settings show the potential of our approach.