 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS2H-DPO: Hardness-Aware Preference Optimization for Vision-Language Models
Apr 20, 2026Vision-Language Models (VLMs) have demonstrated remarkable progress in single-image understanding, yet effective reasoning across multiple images remains challenging. We identify a critical capability gap in existing multi-image alignment approaches: current methods focus primarily on localized reasoning with pre-specified image indices (``Look at Image 3 and...''), bypassing the essential skills of global visual search and autonomous cross-image comparison. To address this limitation, we introduce a Simple-to-Hard (S2H) learning framework that systematically constructs multi-image preference data across three hierarchical reasoning levels requiring an increasing level of capabilities: (1) single-image localized reasoning, (2) multi-image localized comparison, and (3) global visual search. Unlike prior work that relies on model-specific attributes, such as hallucinations or attention heuristics, to generate preference pairs, our approach leverages prompt-driven complexity to create chosen/rejected pairs that are applicable across different models. Through extensive evaluations on LLaVA and Qwen-VL models, we show that our diverse multi-image reasoning data significantly enhances multi-image reasoning performance, yielding significant improvements over baseline methods across benchmarks. Importantly, our approach maintains strong single-image reasoning performance while simultaneously strengthening multi-image understanding capabilities, thus advancing the state of the art for holistic visual preference alignment.
ReEdit: Multimodal Exemplar-Based Image Editing with Diffusion Models
Nov 06, 2024



Modern Text-to-Image (T2I) Diffusion models have revolutionized image editing by enabling the generation of high-quality photorealistic images. While the de facto method for performing edits with T2I models is through text instructions, this approach non-trivial due to the complex many-to-many mapping between natural language and images. In this work, we address exemplar-based image editing -- the task of transferring an edit from an exemplar pair to a content image(s). We propose ReEdit, a modular and efficient end-to-end framework that captures edits in both text and image modalities while ensuring the fidelity of the edited image. We validate the effectiveness of ReEdit through extensive comparisons with state-of-the-art baselines and sensitivity analyses of key design choices. Our results demonstrate that ReEdit consistently outperforms contemporary approaches both qualitatively and quantitatively. Additionally, ReEdit boasts high practical applicability, as it does not require any task-specific optimization and is four times faster than the next best baseline.
LEAST: "Local" text-conditioned image style transfer
May 25, 2024Text-conditioned style transfer enables users to communicate their desired artistic styles through text descriptions, offering a new and expressive means of achieving stylization. In this work, we evaluate the text-conditioned image editing and style transfer techniques on their fine-grained understanding of user prompts for precise "local" style transfer. We find that current methods fail to accomplish localized style transfers effectively, either failing to localize style transfer to certain regions in the image, or distorting the content and structure of the input image. To this end, we carefully design an end-to-end pipeline that guarantees local style transfer according to users' intent. Further, we substantiate the effectiveness of our approach through quantitative and qualitative analysis. The project code is available at: https://github.com/silky1708/local-style-transfer.
Thinking Fair and Slow: On the Efficacy of Structured Prompts for Debiasing Language Models
May 16, 2024
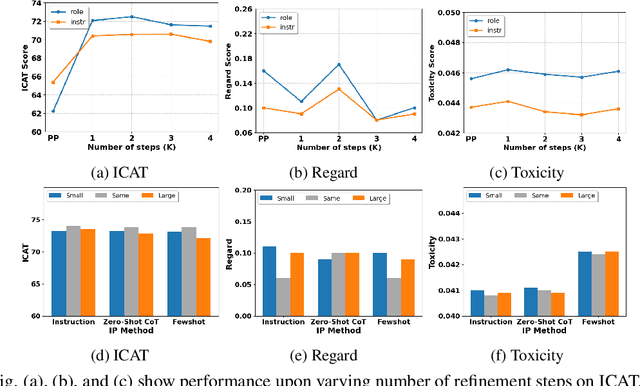
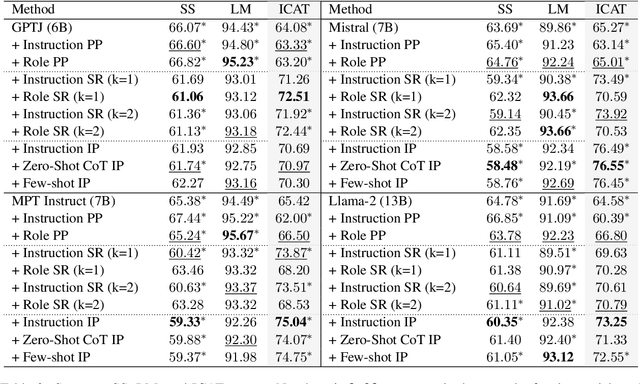
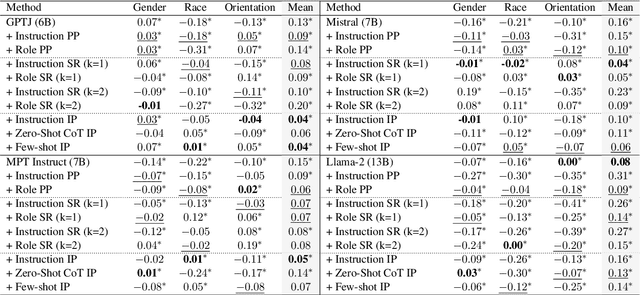
Existing debiasing techniques are typically training-based or require access to the model's internals and output distributions, so they are inaccessible to end-users looking to adapt LLM outputs for their particular needs. In this study, we examine whether structured prompting techniques can offer opportunities for fair text generation. We evaluate a comprehensive end-user-focused iterative framework of debiasing that applies System 2 thinking processes for prompts to induce logical, reflective, and critical text generation, with single, multi-step, instruction, and role-based variants. By systematically evaluating many LLMs across many datasets and different prompting strategies, we show that the more complex System 2-based Implicative Prompts significantly improve over other techniques demonstrating lower mean bias in the outputs with competitive performance on the downstream tasks. Our work offers research directions for the design and the potential of end-user-focused evaluative frameworks for LLM use.
Introducing v0.5 of the AI Safety Benchmark from MLCommons
Apr 18, 2024



This paper introduces v0.5 of the AI Safety Benchmark, which has been created by the MLCommons AI Safety Working Group. The AI Safety Benchmark has been designed to assess the safety risks of AI systems that use chat-tuned language models. We introduce a principled approach to specifying and constructing the benchmark, which for v0.5 covers only a single use case (an adult chatting to a general-purpose assistant in English), and a limited set of personas (i.e., typical users, malicious users, and vulnerable users). We created a new taxonomy of 13 hazard categories, of which 7 have tests in the v0.5 benchmark. We plan to release version 1.0 of the AI Safety Benchmark by the end of 2024. The v1.0 benchmark will provide meaningful insights into the safety of AI systems. However, the v0.5 benchmark should not be used to assess the safety of AI systems. We have sought to fully document the limitations, flaws, and challenges of v0.5. This release of v0.5 of the AI Safety Benchmark includes (1) a principled approach to specifying and constructing the benchmark, which comprises use cases, types of systems under test (SUTs), language and context, personas, tests, and test items; (2) a taxonomy of 13 hazard categories with definitions and subcategories; (3) tests for seven of the hazard categories, each comprising a unique set of test items, i.e., prompts. There are 43,090 test items in total, which we created with templates; (4) a grading system for AI systems against the benchmark; (5) an openly available platform, and downloadable tool, called ModelBench that can be used to evaluate the safety of AI systems on the benchmark; (6) an example evaluation report which benchmarks the performance of over a dozen openly available chat-tuned language models; (7) a test specification for the benchmark.
All Should Be Equal in the Eyes of Language Models: Counterfactually Aware Fair Text Generation
Nov 09, 2023Fairness in Language Models (LMs) remains a longstanding challenge, given the inherent biases in training data that can be perpetuated by models and affect the downstream tasks. Recent methods employ expensive retraining or attempt debiasing during inference by constraining model outputs to contrast from a reference set of biased templates or exemplars. Regardless, they dont address the primary goal of fairness to maintain equitability across different demographic groups. In this work, we posit that inferencing LMs to generate unbiased output for one demographic under a context ensues from being aware of outputs for other demographics under the same context. To this end, we propose Counterfactually Aware Fair InferencE (CAFIE), a framework that dynamically compares the model understanding of diverse demographics to generate more equitable sentences. We conduct an extensive empirical evaluation using base LMs of varying sizes and across three diverse datasets and found that CAFIE outperforms strong baselines. CAFIE produces fairer text and strikes the best balance between fairness and language modeling capability
Towards Estimating Transferability using Hard Subsets
Jan 17, 2023
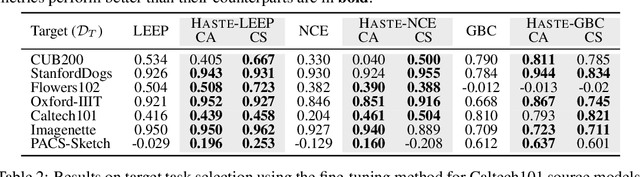
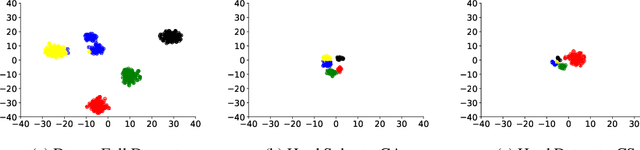
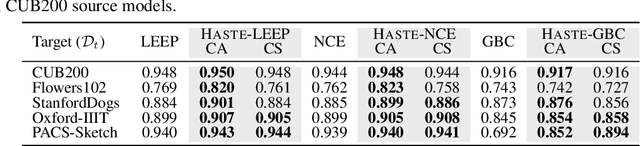
As transfer learning techniques are increasingly used to transfer knowledge from the source model to the target task, it becomes important to quantify which source models are suitable for a given target task without performing computationally expensive fine tuning. In this work, we propose HASTE (HArd Subset TransfErability), a new strategy to estimate the transferability of a source model to a particular target task using only a harder subset of target data. By leveraging the internal and output representations of model, we introduce two techniques, one class agnostic and another class specific, to identify harder subsets and show that HASTE can be used with any existing transferability metric to improve their reliability. We further analyze the relation between HASTE and the optimal average log likelihood as well as negative conditional entropy and empirically validate our theoretical bounds. Our experimental results across multiple source model architectures, target datasets, and transfer learning tasks show that HASTE modified metrics are consistently better or on par with the state of the art transferability metrics.
One-Shot Doc Snippet Detection: Powering Search in Document Beyond Text
Sep 12, 2022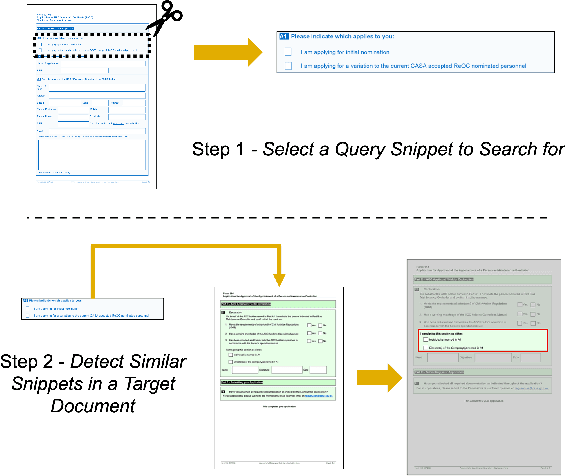


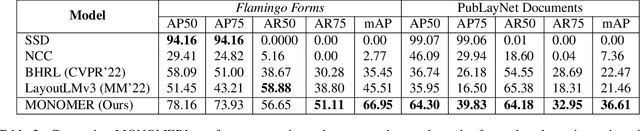
Active consumption of digital documents has yielded scope for research in various applications, including search. Traditionally, searching within a document has been cast as a text matching problem ignoring the rich layout and visual cues commonly present in structured documents, forms, etc. To that end, we ask a mostly unexplored question: "Can we search for other similar snippets present in a target document page given a single query instance of a document snippet?". We propose MONOMER to solve this as a one-shot snippet detection task. MONOMER fuses context from visual, textual, and spatial modalities of snippets and documents to find query snippet in target documents. We conduct extensive ablations and experiments showing MONOMER outperforms several baselines from one-shot object detection (BHRL), template matching, and document understanding (LayoutLMv3). Due to the scarcity of relevant data for the task at hand, we train MONOMER on programmatically generated data having many visually similar query snippets and target document pairs from two datasets - Flamingo Forms and PubLayNet. We also do a human study to validate the generated data.
On Conditioning the Input Noise for Controlled Image Generation with Diffusion Models
May 08, 2022
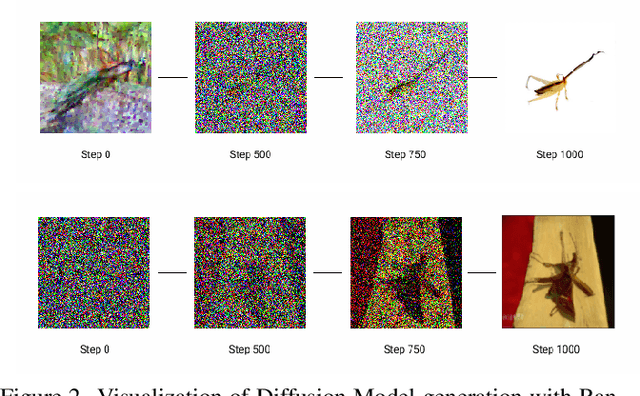


Conditional image generation has paved the way for several breakthroughs in image editing, generating stock photos and 3-D object generation. This continues to be a significant area of interest with the rise of new state-of-the-art methods that are based on diffusion models. However, diffusion models provide very little control over the generated image, which led to subsequent works exploring techniques like classifier guidance, that provides a way to trade off diversity with fidelity. In this work, we explore techniques to condition diffusion models with carefully crafted input noise artifacts. This allows generation of images conditioned on semantic attributes. This is different from existing approaches that input Gaussian noise and further introduce conditioning at the diffusion model's inference step. Our experiments over several examples and conditional settings show the potential of our approach.
TRACE: Transform Aggregate and Compose Visiolinguistic Representations for Image Search with Text Feedback
Sep 03, 2020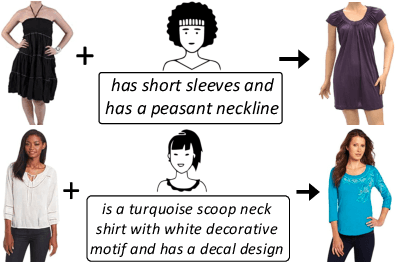
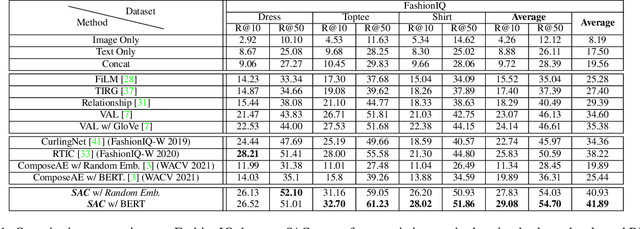
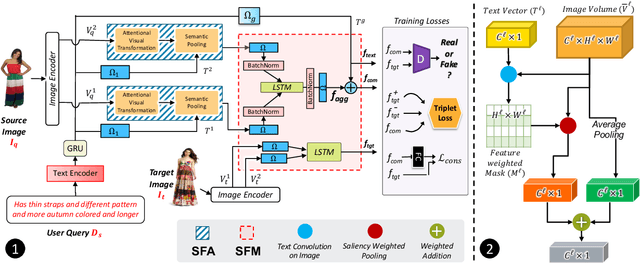
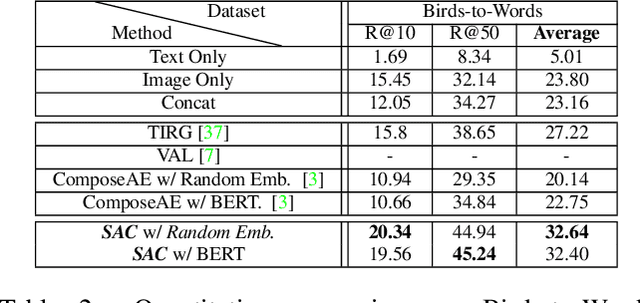
The ability to efficiently search for images over an indexed database is the cornerstone for several user experiences. Incorporating user feedback, through multi-modal inputs provide flexible and interaction to serve fine-grained specificity in requirements. We specifically focus on text feedback, through descriptive natural language queries. Given a reference image and textual user feedback, our goal is to retrieve images that satisfy constraints specified by both of these input modalities. The task is challenging as it requires understanding the textual semantics from the text feedback and then applying these changes to the visual representation. To address these challenges, we propose a novel architecture TRACE which contains a hierarchical feature aggregation module to learn the composite visio-linguistic representations. TRACE achieves the SOTA performance on 3 benchmark datasets: FashionIQ, Shoes, and Birds-to-Words, with an average improvement of at least ~5.7%, ~3%, and ~5% respectively in R@K metric. Our extensive experiments and ablation studies show that TRACE consistently outperforms the existing techniques by significant margins both quantitatively and qualitatively.