 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLOCATE: Self-supervised Object Discovery via Flow-guided Graph-cut and Bootstrapped Self-training
Aug 22, 2023Learning object segmentation in image and video datasets without human supervision is a challenging problem. Humans easily identify moving salient objects in videos using the gestalt principle of common fate, which suggests that what moves together belongs together. Building upon this idea, we propose a self-supervised object discovery approach that leverages motion and appearance information to produce high-quality object segmentation masks. Specifically, we redesign the traditional graph cut on images to include motion information in a linear combination with appearance information to produce edge weights. Remarkably, this step produces object segmentation masks comparable to the current state-of-the-art on multiple benchmarks. To further improve performance, we bootstrap a segmentation network trained on these preliminary masks as pseudo-ground truths to learn from its own outputs via self-training. We demonstrate the effectiveness of our approach, named LOCATE, on multiple standard video object segmentation, image saliency detection, and object segmentation benchmarks, achieving results on par with and, in many cases surpassing state-of-the-art methods. We also demonstrate the transferability of our approach to novel domains through a qualitative study on in-the-wild images. Additionally, we present extensive ablation analysis to support our design choices and highlight the contribution of each component of our proposed method.
FODVid: Flow-guided Object Discovery in Videos
Jul 10, 2023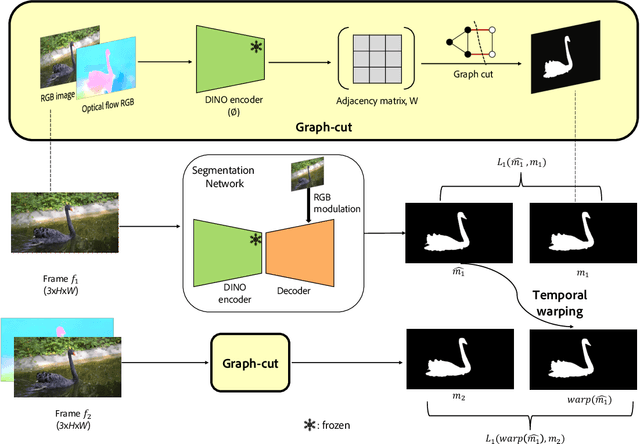
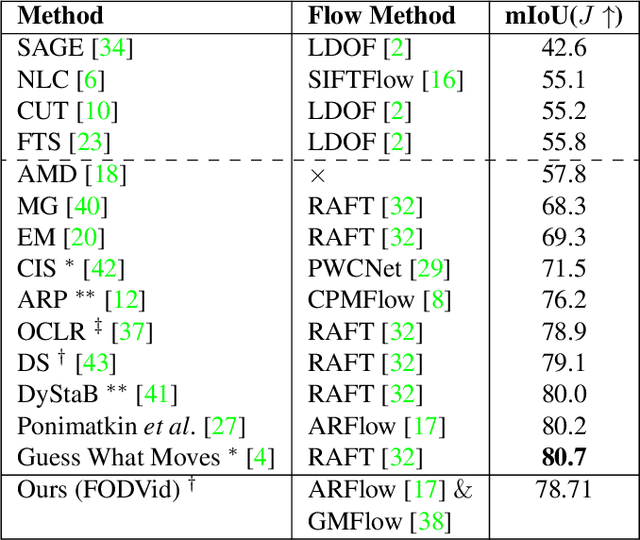
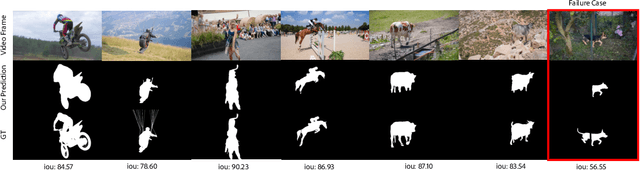
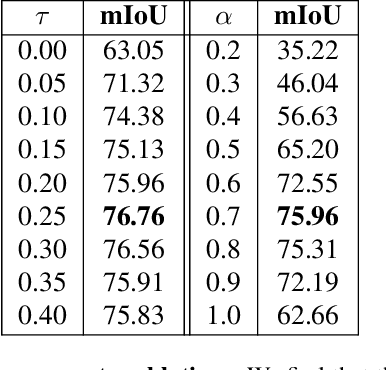
Segmentation of objects in a video is challenging due to the nuances such as motion blurring, parallax, occlusions, changes in illumination, etc. Instead of addressing these nuances separately, we focus on building a generalizable solution that avoids overfitting to the individual intricacies. Such a solution would also help us save enormous resources involved in human annotation of video corpora. To solve Video Object Segmentation (VOS) in an unsupervised setting, we propose a new pipeline (FODVid) based on the idea of guiding segmentation outputs using flow-guided graph-cut and temporal consistency. Basically, we design a segmentation model incorporating intra-frame appearance and flow similarities, and inter-frame temporal continuation of the objects under consideration. We perform an extensive experimental analysis of our straightforward methodology on the standard DAVIS16 video benchmark. Though simple, our approach produces results comparable (within a range of ~2 mIoU) to the existing top approaches in unsupervised VOS. The simplicity and effectiveness of our technique opens up new avenues for research in the video domain.
One-Shot Doc Snippet Detection: Powering Search in Document Beyond Text
Sep 12, 2022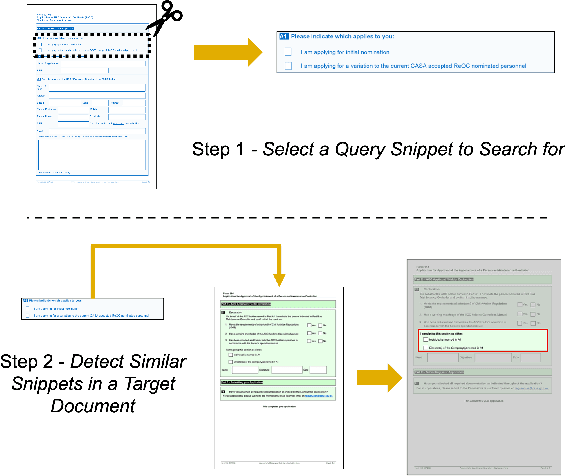


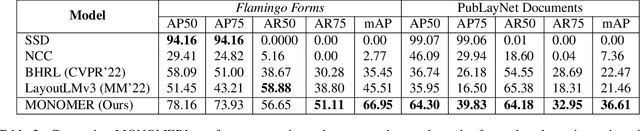
Active consumption of digital documents has yielded scope for research in various applications, including search. Traditionally, searching within a document has been cast as a text matching problem ignoring the rich layout and visual cues commonly present in structured documents, forms, etc. To that end, we ask a mostly unexplored question: "Can we search for other similar snippets present in a target document page given a single query instance of a document snippet?". We propose MONOMER to solve this as a one-shot snippet detection task. MONOMER fuses context from visual, textual, and spatial modalities of snippets and documents to find query snippet in target documents. We conduct extensive ablations and experiments showing MONOMER outperforms several baselines from one-shot object detection (BHRL), template matching, and document understanding (LayoutLMv3). Due to the scarcity of relevant data for the task at hand, we train MONOMER on programmatically generated data having many visually similar query snippets and target document pairs from two datasets - Flamingo Forms and PubLayNet. We also do a human study to validate the generated data.
Explain Your Move: Understanding Agent Actions Using Focused Feature Saliency
Dec 31, 2019

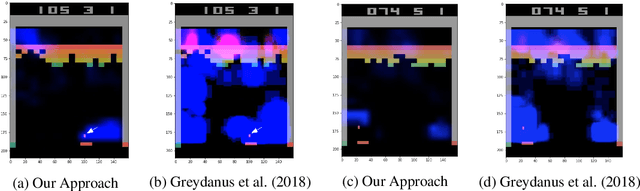
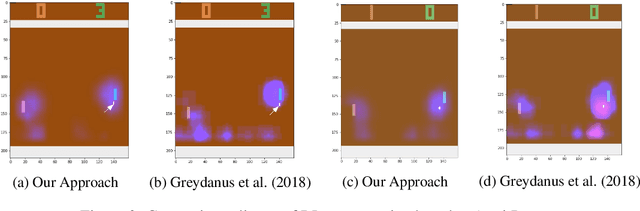
As deep reinforcement learning (RL) is applied to more tasks, there is a need to visualize and understand the behavior of learned agents. Saliency maps explain agent behavior by highlighting the features of the input state that are most relevant for the agent in taking an action. Existing perturbation-based approaches to compute saliency often highlight regions of the input that are not relevant to the action taken by the agent. Our approach generates more focused saliency maps by balancing two aspects (specificity and relevance) that capture different desiderata of saliency. The first captures the impact of perturbation on the relative expected reward of the action to be explained. The second downweights irrelevant features that alter the relative expected rewards of actions other than the action to be explained. We compare our approach with existing approaches on agents trained to play board games (Chess and Go) and Atari games (Breakout, Pong and Space Invaders). We show through illustrative examples (Chess, Atari, Go), human studies (Chess), and automated evaluation methods (Chess) that our approach generates saliency maps that are more interpretable for humans than existing approaches.