 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFODVid: Flow-guided Object Discovery in Videos
Paper and Code
Jul 10, 2023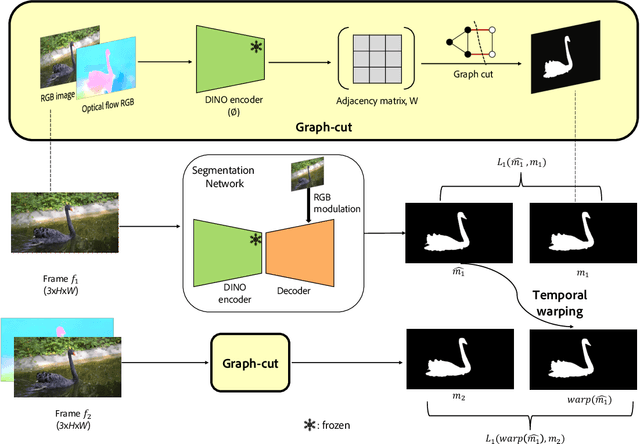
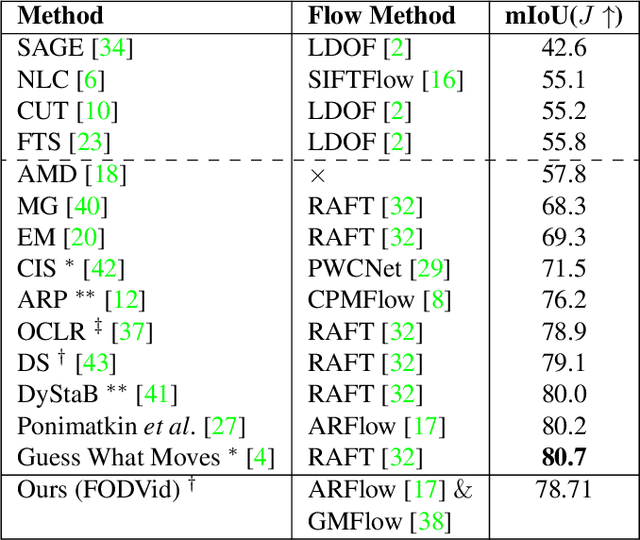
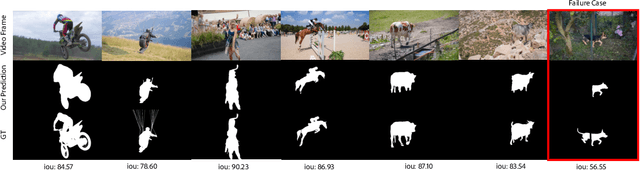
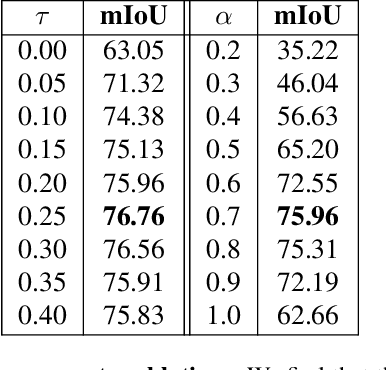
Segmentation of objects in a video is challenging due to the nuances such as motion blurring, parallax, occlusions, changes in illumination, etc. Instead of addressing these nuances separately, we focus on building a generalizable solution that avoids overfitting to the individual intricacies. Such a solution would also help us save enormous resources involved in human annotation of video corpora. To solve Video Object Segmentation (VOS) in an unsupervised setting, we propose a new pipeline (FODVid) based on the idea of guiding segmentation outputs using flow-guided graph-cut and temporal consistency. Basically, we design a segmentation model incorporating intra-frame appearance and flow similarities, and inter-frame temporal continuation of the objects under consideration. We perform an extensive experimental analysis of our straightforward methodology on the standard DAVIS16 video benchmark. Though simple, our approach produces results comparable (within a range of ~2 mIoU) to the existing top approaches in unsupervised VOS. The simplicity and effectiveness of our technique opens up new avenues for research in the video domain.