 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideoWeave: A Data-Centric Approach for Efficient Video Understanding
Jan 09, 2026Training video-language models is often prohibitively expensive due to the high cost of processing long frame sequences and the limited availability of annotated long videos. We present VideoWeave, a simple yet effective approach to improve data efficiency by constructing synthetic long-context training samples that splice together short, captioned videos from existing datasets. Rather than modifying model architectures or optimization objectives, VideoWeave reorganizes available video-text pairs to expand temporal diversity within fixed compute. We systematically study how different data composition strategies like random versus visually clustered splicing and caption enrichment affect downstream performance on downstream video question answering. Under identical compute constraints, models trained with VideoWeave achieve higher accuracy than conventional video finetuning. Our results highlight that reorganizing training data, rather than altering architectures, may offer a simple and scalable path for training video-language models. We link our code for all experiments here.
ReEdit: Multimodal Exemplar-Based Image Editing with Diffusion Models
Nov 06, 2024



Modern Text-to-Image (T2I) Diffusion models have revolutionized image editing by enabling the generation of high-quality photorealistic images. While the de facto method for performing edits with T2I models is through text instructions, this approach non-trivial due to the complex many-to-many mapping between natural language and images. In this work, we address exemplar-based image editing -- the task of transferring an edit from an exemplar pair to a content image(s). We propose ReEdit, a modular and efficient end-to-end framework that captures edits in both text and image modalities while ensuring the fidelity of the edited image. We validate the effectiveness of ReEdit through extensive comparisons with state-of-the-art baselines and sensitivity analyses of key design choices. Our results demonstrate that ReEdit consistently outperforms contemporary approaches both qualitatively and quantitatively. Additionally, ReEdit boasts high practical applicability, as it does not require any task-specific optimization and is four times faster than the next best baseline.
LEAST: "Local" text-conditioned image style transfer
May 25, 2024Text-conditioned style transfer enables users to communicate their desired artistic styles through text descriptions, offering a new and expressive means of achieving stylization. In this work, we evaluate the text-conditioned image editing and style transfer techniques on their fine-grained understanding of user prompts for precise "local" style transfer. We find that current methods fail to accomplish localized style transfers effectively, either failing to localize style transfer to certain regions in the image, or distorting the content and structure of the input image. To this end, we carefully design an end-to-end pipeline that guarantees local style transfer according to users' intent. Further, we substantiate the effectiveness of our approach through quantitative and qualitative analysis. The project code is available at: https://github.com/silky1708/local-style-transfer.
LOCATE: Self-supervised Object Discovery via Flow-guided Graph-cut and Bootstrapped Self-training
Aug 22, 2023Learning object segmentation in image and video datasets without human supervision is a challenging problem. Humans easily identify moving salient objects in videos using the gestalt principle of common fate, which suggests that what moves together belongs together. Building upon this idea, we propose a self-supervised object discovery approach that leverages motion and appearance information to produce high-quality object segmentation masks. Specifically, we redesign the traditional graph cut on images to include motion information in a linear combination with appearance information to produce edge weights. Remarkably, this step produces object segmentation masks comparable to the current state-of-the-art on multiple benchmarks. To further improve performance, we bootstrap a segmentation network trained on these preliminary masks as pseudo-ground truths to learn from its own outputs via self-training. We demonstrate the effectiveness of our approach, named LOCATE, on multiple standard video object segmentation, image saliency detection, and object segmentation benchmarks, achieving results on par with and, in many cases surpassing state-of-the-art methods. We also demonstrate the transferability of our approach to novel domains through a qualitative study on in-the-wild images. Additionally, we present extensive ablation analysis to support our design choices and highlight the contribution of each component of our proposed method.
FODVid: Flow-guided Object Discovery in Videos
Jul 10, 2023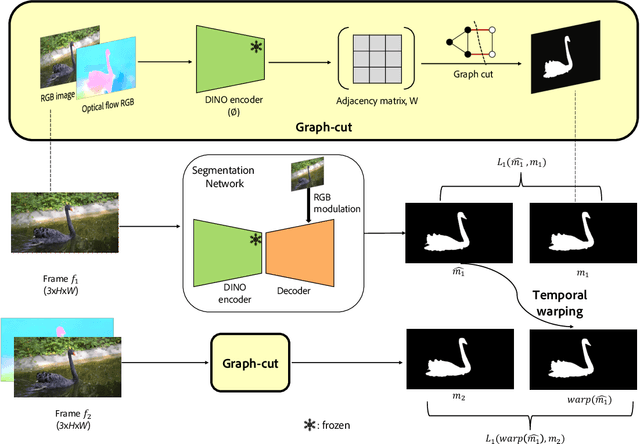
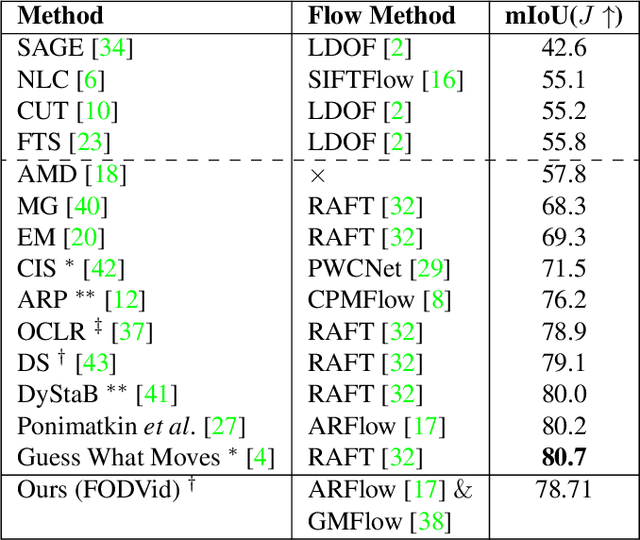
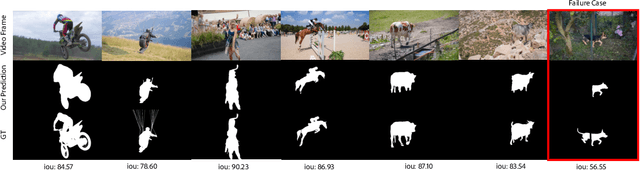
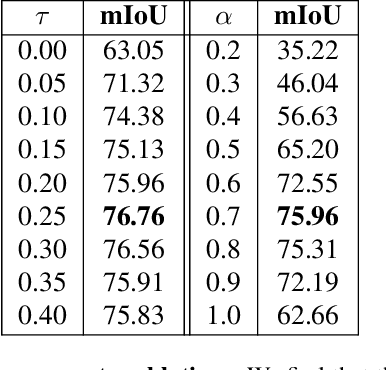
Segmentation of objects in a video is challenging due to the nuances such as motion blurring, parallax, occlusions, changes in illumination, etc. Instead of addressing these nuances separately, we focus on building a generalizable solution that avoids overfitting to the individual intricacies. Such a solution would also help us save enormous resources involved in human annotation of video corpora. To solve Video Object Segmentation (VOS) in an unsupervised setting, we propose a new pipeline (FODVid) based on the idea of guiding segmentation outputs using flow-guided graph-cut and temporal consistency. Basically, we design a segmentation model incorporating intra-frame appearance and flow similarities, and inter-frame temporal continuation of the objects under consideration. We perform an extensive experimental analysis of our straightforward methodology on the standard DAVIS16 video benchmark. Though simple, our approach produces results comparable (within a range of ~2 mIoU) to the existing top approaches in unsupervised VOS. The simplicity and effectiveness of our technique opens up new avenues for research in the video domain.