 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEOPose : Exemplar-based object reposing using Generalized Pose Correspondences
May 06, 2025



Reposing objects in images has a myriad of applications, especially for e-commerce where several variants of product images need to be produced quickly. In this work, we leverage the recent advances in unsupervised keypoint correspondence detection between different object images of the same class to propose an end-to-end framework for generic object reposing. Our method, EOPose, takes a target pose-guidance image as input and uses its keypoint correspondence with the source object image to warp and re-render the latter into the target pose using a novel three-step approach. Unlike generative approaches, our method also preserves the fine-grained details of the object such as its exact colors, textures, and brand marks. We also prepare a new dataset of paired objects based on the Objaverse dataset to train and test our network. EOPose produces high-quality reposing output as evidenced by different image quality metrics (PSNR, SSIM and FID). Besides a description of the method and the dataset, the paper also includes detailed ablation and user studies to indicate the efficacy of the proposed method
FODVid: Flow-guided Object Discovery in Videos
Jul 10, 2023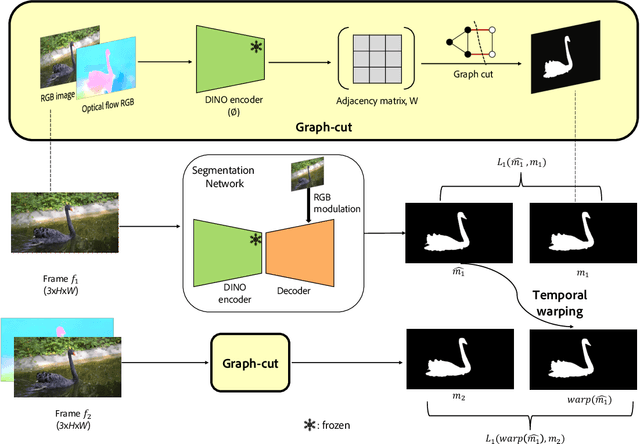
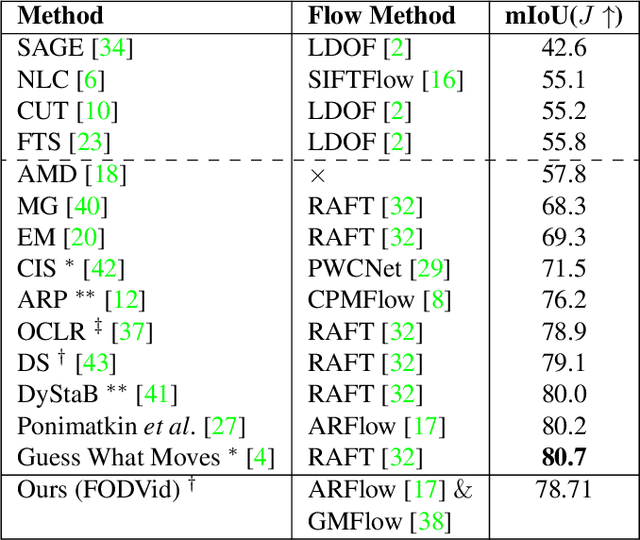
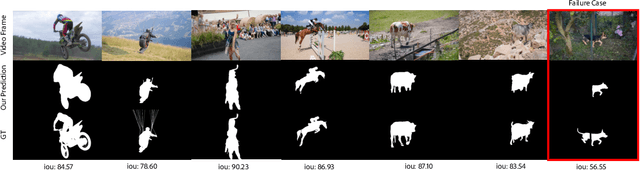
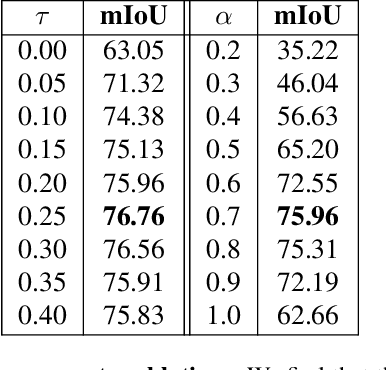
Segmentation of objects in a video is challenging due to the nuances such as motion blurring, parallax, occlusions, changes in illumination, etc. Instead of addressing these nuances separately, we focus on building a generalizable solution that avoids overfitting to the individual intricacies. Such a solution would also help us save enormous resources involved in human annotation of video corpora. To solve Video Object Segmentation (VOS) in an unsupervised setting, we propose a new pipeline (FODVid) based on the idea of guiding segmentation outputs using flow-guided graph-cut and temporal consistency. Basically, we design a segmentation model incorporating intra-frame appearance and flow similarities, and inter-frame temporal continuation of the objects under consideration. We perform an extensive experimental analysis of our straightforward methodology on the standard DAVIS16 video benchmark. Though simple, our approach produces results comparable (within a range of ~2 mIoU) to the existing top approaches in unsupervised VOS. The simplicity and effectiveness of our technique opens up new avenues for research in the video domain.
Parameter Efficient Local Implicit Image Function Network for Face Segmentation
Mar 27, 2023Face parsing is defined as the per-pixel labeling of images containing human faces. The labels are defined to identify key facial regions like eyes, lips, nose, hair, etc. In this work, we make use of the structural consistency of the human face to propose a lightweight face-parsing method using a Local Implicit Function network, FP-LIIF. We propose a simple architecture having a convolutional encoder and a pixel MLP decoder that uses 1/26th number of parameters compared to the state-of-the-art models and yet matches or outperforms state-of-the-art models on multiple datasets, like CelebAMask-HQ and LaPa. We do not use any pretraining, and compared to other works, our network can also generate segmentation at different resolutions without any changes in the input resolution. This work enables the use of facial segmentation on low-compute or low-bandwidth devices because of its higher FPS and smaller model size.
DeAR: Debiasing Vision-Language Models with Additive Residuals
Mar 18, 2023Large pre-trained vision-language models (VLMs) reduce the time for developing predictive models for various vision-grounded language downstream tasks by providing rich, adaptable image and text representations. However, these models suffer from societal biases owing to the skewed distribution of various identity groups in the training data. These biases manifest as the skewed similarity between the representations for specific text concepts and images of people of different identity groups and, therefore, limit the usefulness of such models in real-world high-stakes applications. In this work, we present DeAR (Debiasing with Additive Residuals), a novel debiasing method that learns additive residual image representations to offset the original representations, ensuring fair output representations. In doing so, it reduces the ability of the representations to distinguish between the different identity groups. Further, we observe that the current fairness tests are performed on limited face image datasets that fail to indicate why a specific text concept should/should not apply to them. To bridge this gap and better evaluate DeAR, we introduce the Protected Attribute Tag Association (PATA) dataset - a new context-based bias benchmarking dataset for evaluating the fairness of large pre-trained VLMs. Additionally, PATA provides visual context for a diverse human population in different scenarios with both positive and negative connotations. Experimental results for fairness and zero-shot performance preservation using multiple datasets demonstrate the efficacy of our framework.
UMFuse: Unified Multi View Fusion for Human Editing applications
Dec 01, 2022



The vision community has explored numerous pose guided human editing methods due to their extensive practical applications. Most of these methods still use an image-to-image formulation in which a single image is given as input to produce an edited image as output. However, the problem is ill-defined in cases when the target pose is significantly different from the input pose. Existing methods then resort to in-painting or style transfer to handle occlusions and preserve content. In this paper, we explore the utilization of multiple views to minimize the issue of missing information and generate an accurate representation of the underlying human model. To fuse the knowledge from multiple viewpoints, we design a selector network that takes the pose keypoints and texture from images and generates an interpretable per-pixel selection map. After that, the encodings from a separate network (trained on a single image human reposing task) are merged in the latent space. This enables us to generate accurate, precise, and visually coherent images for different editing tasks. We show the application of our network on 2 newly proposed tasks - Multi-view human reposing, and Mix-and-match human image generation. Additionally, we study the limitations of single-view editing and scenarios in which multi-view provides a much better alternative.
VGFlow: Visibility guided Flow Network for Human Reposing
Nov 13, 2022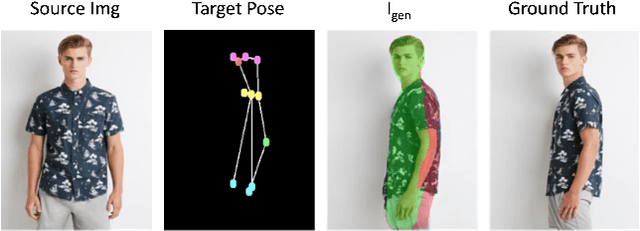



The task of human reposing involves generating a realistic image of a person standing in an arbitrary conceivable pose. There are multiple difficulties in generating perceptually accurate images, and existing methods suffer from limitations in preserving texture, maintaining pattern coherence, respecting cloth boundaries, handling occlusions, manipulating skin generation, etc. These difficulties are further exacerbated by the fact that the possible space of pose orientation for humans is large and variable, the nature of clothing items is highly non-rigid, and the diversity in body shape differs largely among the population. To alleviate these difficulties and synthesize perceptually accurate images, we propose VGFlow. Our model uses a visibility-guided flow module to disentangle the flow into visible and invisible parts of the target for simultaneous texture preservation and style manipulation. Furthermore, to tackle distinct body shapes and avoid network artifacts, we also incorporate a self-supervised patch-wise "realness" loss to improve the output. VGFlow achieves state-of-the-art results as observed qualitatively and quantitatively on different image quality metrics (SSIM, LPIPS, FID).
ZFlow: Gated Appearance Flow-based Virtual Try-on with 3D Priors
Sep 14, 2021
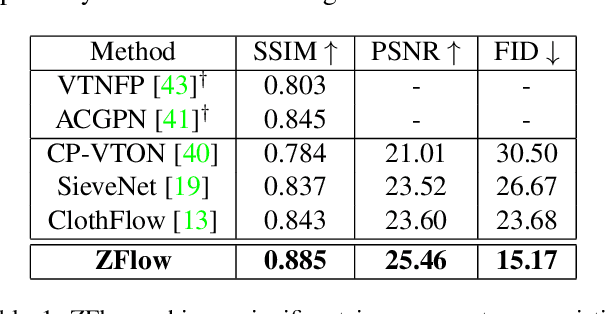
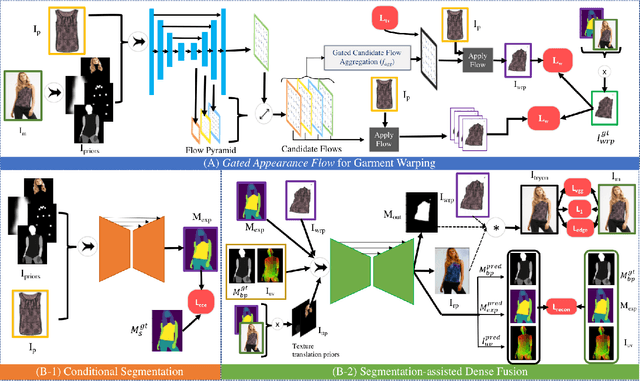
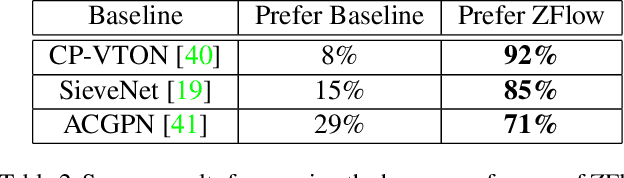
Image-based virtual try-on involves synthesizing perceptually convincing images of a model wearing a particular garment and has garnered significant research interest due to its immense practical applicability. Recent methods involve a two stage process: i) warping of the garment to align with the model ii) texture fusion of the warped garment and target model to generate the try-on output. Issues arise due to the non-rigid nature of garments and the lack of geometric information about the model or the garment. It often results in improper rendering of granular details. We propose ZFlow, an end-to-end framework, which seeks to alleviate these concerns regarding geometric and textural integrity (such as pose, depth-ordering, skin and neckline reproduction) through a combination of gated aggregation of hierarchical flow estimates termed Gated Appearance Flow, and dense structural priors at various stage of the network. ZFlow achieves state-of-the-art results as observed qualitatively, and on quantitative benchmarks of image quality (PSNR, SSIM, and FID). The paper presents extensive comparisons with other existing solutions including a detailed user study and ablation studies to gauge the effect of each of our contributions on multiple datasets.
SimPropNet: Improved Similarity Propagation for Few-shot Image Segmentation
May 02, 2020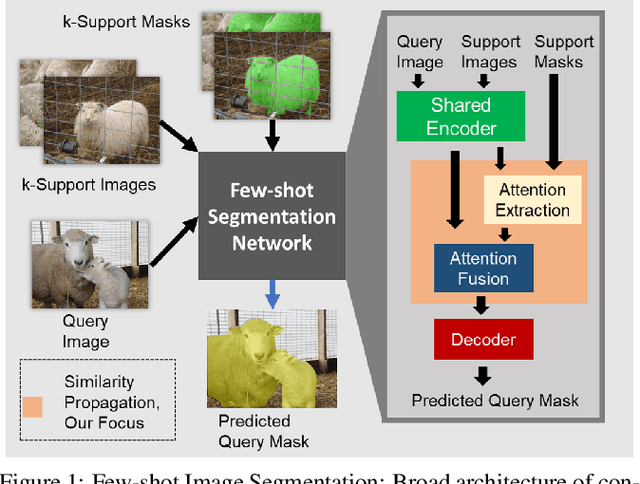

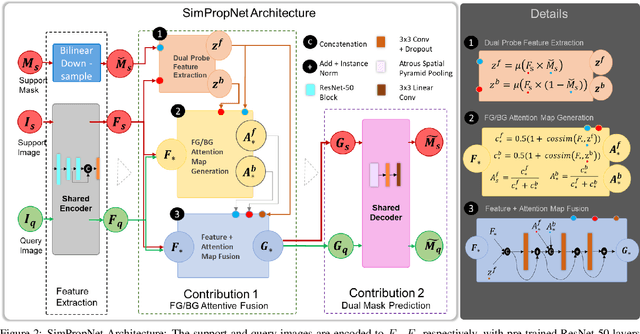

Few-shot segmentation (FSS) methods perform image segmentation for a particular object class in a target (query) image, using a small set of (support) image-mask pairs. Recent deep neural network based FSS methods leverage high-dimensional feature similarity between the foreground features of the support images and the query image features. In this work, we demonstrate gaps in the utilization of this similarity information in existing methods, and present a framework - SimPropNet, to bridge those gaps. We propose to jointly predict the support and query masks to force the support features to share characteristics with the query features. We also propose to utilize similarities in the background regions of the query and support images using a novel foreground-background attentive fusion mechanism. Our method achieves state-of-the-art results for one-shot and five-shot segmentation on the PASCAL-5i dataset. The paper includes detailed analysis and ablation studies for the proposed improvements and quantitative comparisons with contemporary methods.
SieveNet: A Unified Framework for Robust Image-Based Virtual Try-On
Jan 17, 2020
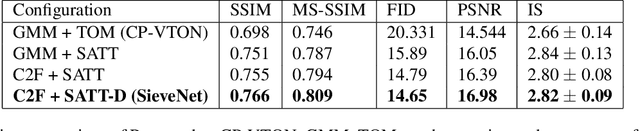
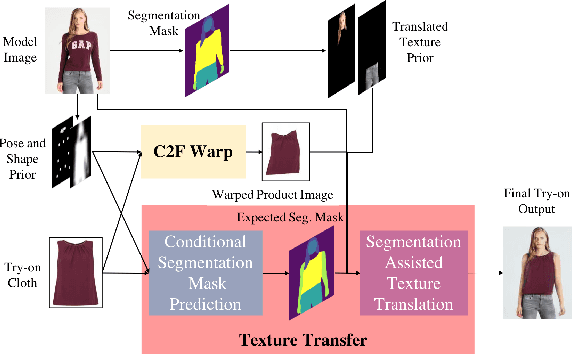
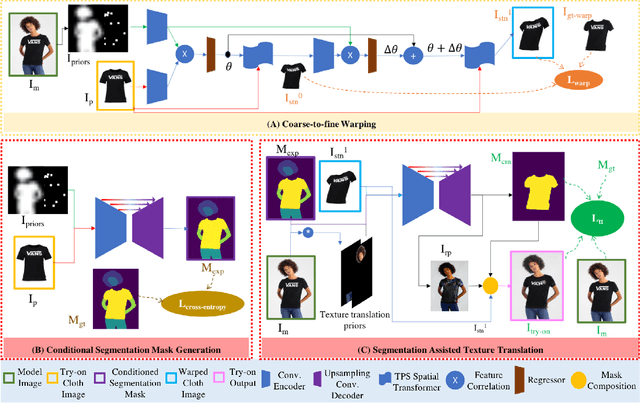
Image-based virtual try-on for fashion has gained considerable attention recently. The task requires trying on a clothing item on a target model image. An efficient framework for this is composed of two stages: (1) warping (transforming) the try-on cloth to align with the pose and shape of the target model, and (2) a texture transfer module to seamlessly integrate the warped try-on cloth onto the target model image. Existing methods suffer from artifacts and distortions in their try-on output. In this work, we present SieveNet, a framework for robust image-based virtual try-on. Firstly, we introduce a multi-stage coarse-to-fine warping network to better model fine-grained intricacies (while transforming the try-on cloth) and train it with a novel perceptual geometric matching loss. Next, we introduce a try-on cloth conditioned segmentation mask prior to improve the texture transfer network. Finally, we also introduce a dueling triplet loss strategy for training the texture translation network which further improves the quality of the generated try-on results. We present extensive qualitative and quantitative evaluations of each component of the proposed pipeline and show significant performance improvements against the current state-of-the-art method.