 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePutting People in Their Place: Affordance-Aware Human Insertion into Scenes
Apr 27, 2023
We study the problem of inferring scene affordances by presenting a method for realistically inserting people into scenes. Given a scene image with a marked region and an image of a person, we insert the person into the scene while respecting the scene affordances. Our model can infer the set of realistic poses given the scene context, re-pose the reference person, and harmonize the composition. We set up the task in a self-supervised fashion by learning to re-pose humans in video clips. We train a large-scale diffusion model on a dataset of 2.4M video clips that produces diverse plausible poses while respecting the scene context. Given the learned human-scene composition, our model can also hallucinate realistic people and scenes when prompted without conditioning and also enables interactive editing. A quantitative evaluation shows that our method synthesizes more realistic human appearance and more natural human-scene interactions than prior work.
Towards Enhanced Controllability of Diffusion Models
Mar 15, 2023Denoising Diffusion models have shown remarkable capabilities in generating realistic, high-quality and diverse images. However, the extent of controllability during generation is underexplored. Inspired by techniques based on GAN latent space for image manipulation, we train a diffusion model conditioned on two latent codes, a spatial content mask and a flattened style embedding. We rely on the inductive bias of the progressive denoising process of diffusion models to encode pose/layout information in the spatial structure mask and semantic/style information in the style code. We propose two generic sampling techniques for improving controllability. We extend composable diffusion models to allow for some dependence between conditional inputs, to improve the quality of generations while also providing control over the amount of guidance from each latent code and their joint distribution. We also propose timestep dependent weight scheduling for content and style latents to further improve the translations. We observe better controllability compared to existing methods and show that without explicit training objectives, diffusion models can be used for effective image manipulation and image translation.
Modulating Pretrained Diffusion Models for Multimodal Image Synthesis
Feb 24, 2023
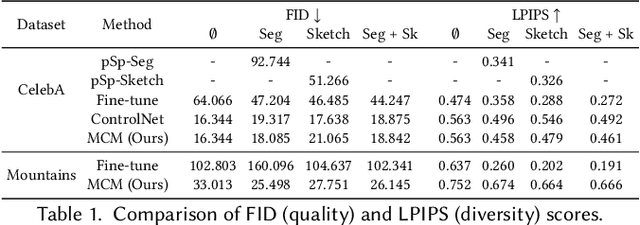


We present multimodal conditioning modules (MCM) for enabling conditional image synthesis using pretrained diffusion models. Previous multimodal synthesis works rely on training networks from scratch or fine-tuning pretrained networks, both of which are computationally expensive for large, state-of-the-art diffusion models. Our method uses pretrained networks but does not require any updates to the diffusion network's parameters. MCM is a small module trained to modulate the diffusion network's predictions during sampling using 2D modalities (e.g., semantic segmentation maps, sketches) that were unseen during the original training of the diffusion model. We show that MCM enables user control over the spatial layout of the image and leads to increased control over the image generation process. Training MCM is cheap as it does not require gradients from the original diffusion net, consists of only $\sim$1$\%$ of the number of parameters of the base diffusion model, and is trained using only a limited number of training examples. We evaluate our method on unconditional and text-conditional models to demonstrate the improved control over the generated images and their alignment with respect to the conditioning inputs.
Zero-shot Image-to-Image Translation
Feb 06, 2023



Large-scale text-to-image generative models have shown their remarkable ability to synthesize diverse and high-quality images. However, it is still challenging to directly apply these models for editing real images for two reasons. First, it is hard for users to come up with a perfect text prompt that accurately describes every visual detail in the input image. Second, while existing models can introduce desirable changes in certain regions, they often dramatically alter the input content and introduce unexpected changes in unwanted regions. In this work, we propose pix2pix-zero, an image-to-image translation method that can preserve the content of the original image without manual prompting. We first automatically discover editing directions that reflect desired edits in the text embedding space. To preserve the general content structure after editing, we further propose cross-attention guidance, which aims to retain the cross-attention maps of the input image throughout the diffusion process. In addition, our method does not need additional training for these edits and can directly use the existing pre-trained text-to-image diffusion model. We conduct extensive experiments and show that our method outperforms existing and concurrent works for both real and synthetic image editing.
Structure-Guided Image Completion with Image-level and Object-level Semantic Discriminators
Dec 13, 2022Structure-guided image completion aims to inpaint a local region of an image according to an input guidance map from users. While such a task enables many practical applications for interactive editing, existing methods often struggle to hallucinate realistic object instances in complex natural scenes. Such a limitation is partially due to the lack of semantic-level constraints inside the hole region as well as the lack of a mechanism to enforce realistic object generation. In this work, we propose a learning paradigm that consists of semantic discriminators and object-level discriminators for improving the generation of complex semantics and objects. Specifically, the semantic discriminators leverage pretrained visual features to improve the realism of the generated visual concepts. Moreover, the object-level discriminators take aligned instances as inputs to enforce the realism of individual objects. Our proposed scheme significantly improves the generation quality and achieves state-of-the-art results on various tasks, including segmentation-guided completion, edge-guided manipulation and panoptically-guided manipulation on Places2 datasets. Furthermore, our trained model is flexible and can support multiple editing use cases, such as object insertion, replacement, removal and standard inpainting. In particular, our trained model combined with a novel automatic image completion pipeline achieves state-of-the-art results on the standard inpainting task.
UMFuse: Unified Multi View Fusion for Human Editing applications
Dec 01, 2022



The vision community has explored numerous pose guided human editing methods due to their extensive practical applications. Most of these methods still use an image-to-image formulation in which a single image is given as input to produce an edited image as output. However, the problem is ill-defined in cases when the target pose is significantly different from the input pose. Existing methods then resort to in-painting or style transfer to handle occlusions and preserve content. In this paper, we explore the utilization of multiple views to minimize the issue of missing information and generate an accurate representation of the underlying human model. To fuse the knowledge from multiple viewpoints, we design a selector network that takes the pose keypoints and texture from images and generates an interpretable per-pixel selection map. After that, the encodings from a separate network (trained on a single image human reposing task) are merged in the latent space. This enables us to generate accurate, precise, and visually coherent images for different editing tasks. We show the application of our network on 2 newly proposed tasks - Multi-view human reposing, and Mix-and-match human image generation. Additionally, we study the limitations of single-view editing and scenarios in which multi-view provides a much better alternative.
VGFlow: Visibility guided Flow Network for Human Reposing
Nov 13, 2022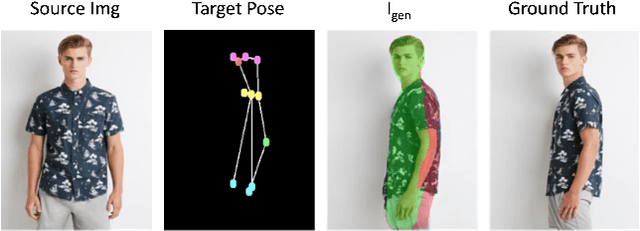



The task of human reposing involves generating a realistic image of a person standing in an arbitrary conceivable pose. There are multiple difficulties in generating perceptually accurate images, and existing methods suffer from limitations in preserving texture, maintaining pattern coherence, respecting cloth boundaries, handling occlusions, manipulating skin generation, etc. These difficulties are further exacerbated by the fact that the possible space of pose orientation for humans is large and variable, the nature of clothing items is highly non-rigid, and the diversity in body shape differs largely among the population. To alleviate these difficulties and synthesize perceptually accurate images, we propose VGFlow. Our model uses a visibility-guided flow module to disentangle the flow into visible and invisible parts of the target for simultaneous texture preservation and style manipulation. Furthermore, to tackle distinct body shapes and avoid network artifacts, we also incorporate a self-supervised patch-wise "realness" loss to improve the output. VGFlow achieves state-of-the-art results as observed qualitatively and quantitatively on different image quality metrics (SSIM, LPIPS, FID).
Contrastive Learning for Diverse Disentangled Foreground Generation
Nov 04, 2022We introduce a new method for diverse foreground generation with explicit control over various factors. Existing image inpainting based foreground generation methods often struggle to generate diverse results and rarely allow users to explicitly control specific factors of variation (e.g., varying the facial identity or expression for face inpainting results). We leverage contrastive learning with latent codes to generate diverse foreground results for the same masked input. Specifically, we define two sets of latent codes, where one controls a pre-defined factor (``known''), and the other controls the remaining factors (``unknown''). The sampled latent codes from the two sets jointly bi-modulate the convolution kernels to guide the generator to synthesize diverse results. Experiments demonstrate the superiority of our method over state-of-the-arts in result diversity and generation controllability.
Spatially-Adaptive Multilayer Selection for GAN Inversion and Editing
Jun 16, 2022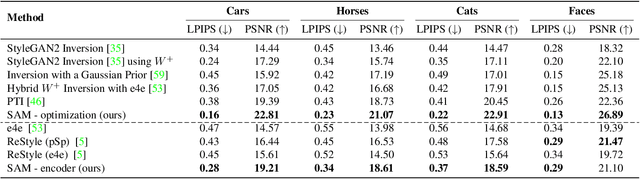
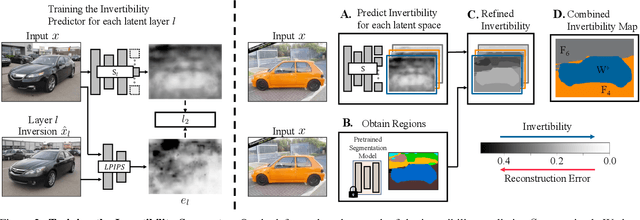
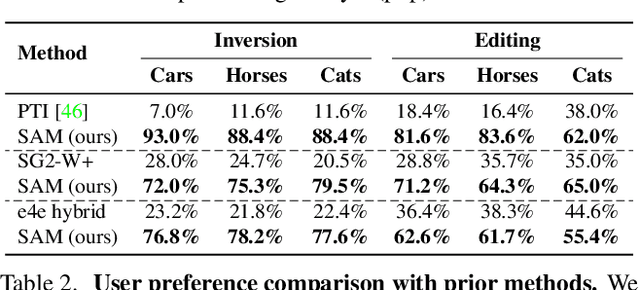

Existing GAN inversion and editing methods work well for aligned objects with a clean background, such as portraits and animal faces, but often struggle for more difficult categories with complex scene layouts and object occlusions, such as cars, animals, and outdoor images. We propose a new method to invert and edit such complex images in the latent space of GANs, such as StyleGAN2. Our key idea is to explore inversion with a collection of layers, spatially adapting the inversion process to the difficulty of the image. We learn to predict the "invertibility" of different image segments and project each segment into a latent layer. Easier regions can be inverted into an earlier layer in the generator's latent space, while more challenging regions can be inverted into a later feature space. Experiments show that our method obtains better inversion results compared to the recent approaches on complex categories, while maintaining downstream editability. Please refer to our project page at https://www.cs.cmu.edu/~SAMInversion.
Learning Motion-Dependent Appearance for High-Fidelity Rendering of Dynamic Humans from a Single Camera
Mar 24, 2022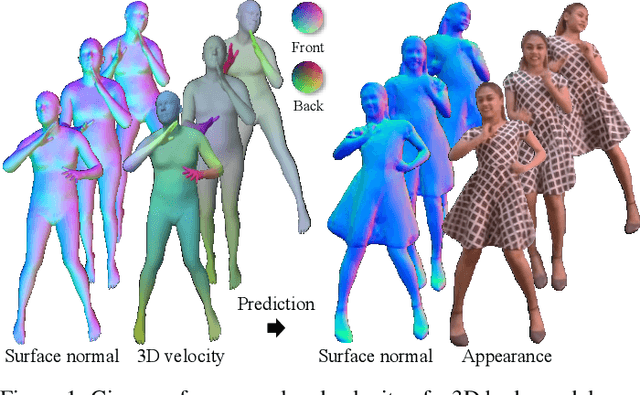

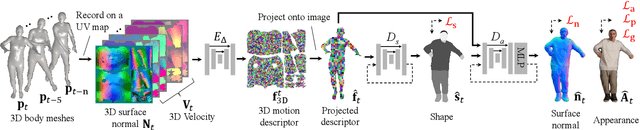

Appearance of dressed humans undergoes a complex geometric transformation induced not only by the static pose but also by its dynamics, i.e., there exists a number of cloth geometric configurations given a pose depending on the way it has moved. Such appearance modeling conditioned on motion has been largely neglected in existing human rendering methods, resulting in rendering of physically implausible motion. A key challenge of learning the dynamics of the appearance lies in the requirement of a prohibitively large amount of observations. In this paper, we present a compact motion representation by enforcing equivariance -- a representation is expected to be transformed in the way that the pose is transformed. We model an equivariant encoder that can generate the generalizable representation from the spatial and temporal derivatives of the 3D body surface. This learned representation is decoded by a compositional multi-task decoder that renders high fidelity time-varying appearance. Our experiments show that our method can generate a temporally coherent video of dynamic humans for unseen body poses and novel views given a single view video.
* CVPR accepted. 15 pages. 17 figures, 5 tables