 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Rectified Flow Transformers for High-Resolution Image Synthesis
Mar 05, 2024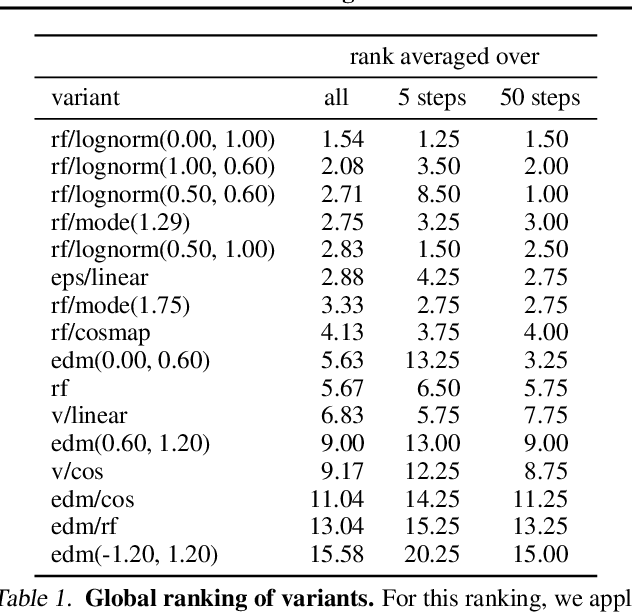
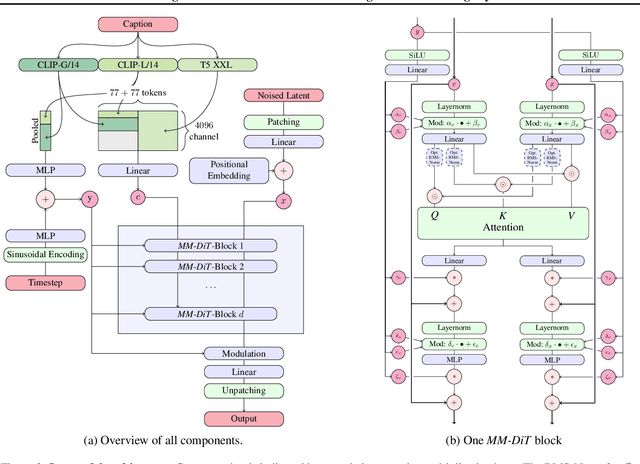
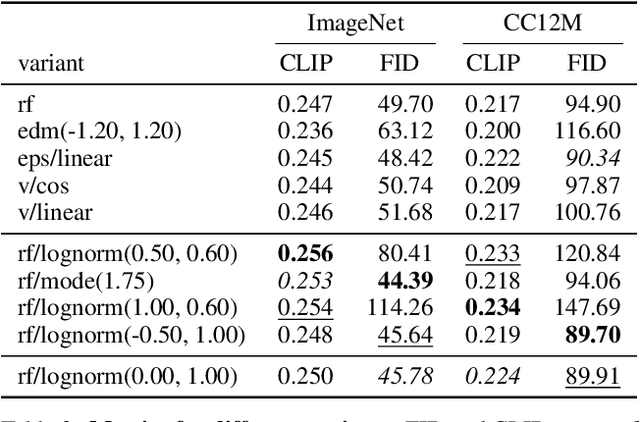
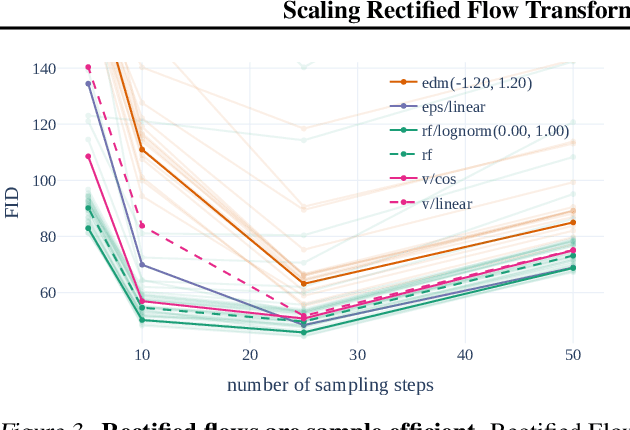
Diffusion models create data from noise by inverting the forward paths of data towards noise and have emerged as a powerful generative modeling technique for high-dimensional, perceptual data such as images and videos. Rectified flow is a recent generative model formulation that connects data and noise in a straight line. Despite its better theoretical properties and conceptual simplicity, it is not yet decisively established as standard practice. In this work, we improve existing noise sampling techniques for training rectified flow models by biasing them towards perceptually relevant scales. Through a large-scale study, we demonstrate the superior performance of this approach compared to established diffusion formulations for high-resolution text-to-image synthesis. Additionally, we present a novel transformer-based architecture for text-to-image generation that uses separate weights for the two modalities and enables a bidirectional flow of information between image and text tokens, improving text comprehension, typography, and human preference ratings. We demonstrate that this architecture follows predictable scaling trends and correlates lower validation loss to improved text-to-image synthesis as measured by various metrics and human evaluations. Our largest models outperform state-of-the-art models, and we will make our experimental data, code, and model weights publicly available.
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Nov 25, 2023



We present Stable Video Diffusion - a latent video diffusion model for high-resolution, state-of-the-art text-to-video and image-to-video generation. Recently, latent diffusion models trained for 2D image synthesis have been turned into generative video models by inserting temporal layers and finetuning them on small, high-quality video datasets. However, training methods in the literature vary widely, and the field has yet to agree on a unified strategy for curating video data. In this paper, we identify and evaluate three different stages for successful training of video LDMs: text-to-image pretraining, video pretraining, and high-quality video finetuning. Furthermore, we demonstrate the necessity of a well-curated pretraining dataset for generating high-quality videos and present a systematic curation process to train a strong base model, including captioning and filtering strategies. We then explore the impact of finetuning our base model on high-quality data and train a text-to-video model that is competitive with closed-source video generation. We also show that our base model provides a powerful motion representation for downstream tasks such as image-to-video generation and adaptability to camera motion-specific LoRA modules. Finally, we demonstrate that our model provides a strong multi-view 3D-prior and can serve as a base to finetune a multi-view diffusion model that jointly generates multiple views of objects in a feedforward fashion, outperforming image-based methods at a fraction of their compute budget. We release code and model weights at https://github.com/Stability-AI/generative-models .
Putting People in Their Place: Affordance-Aware Human Insertion into Scenes
Apr 27, 2023
We study the problem of inferring scene affordances by presenting a method for realistically inserting people into scenes. Given a scene image with a marked region and an image of a person, we insert the person into the scene while respecting the scene affordances. Our model can infer the set of realistic poses given the scene context, re-pose the reference person, and harmonize the composition. We set up the task in a self-supervised fashion by learning to re-pose humans in video clips. We train a large-scale diffusion model on a dataset of 2.4M video clips that produces diverse plausible poses while respecting the scene context. Given the learned human-scene composition, our model can also hallucinate realistic people and scenes when prompted without conditioning and also enables interactive editing. A quantitative evaluation shows that our method synthesizes more realistic human appearance and more natural human-scene interactions than prior work.
Programmatic Concept Learning for Human Motion Description and Synthesis
Jun 27, 2022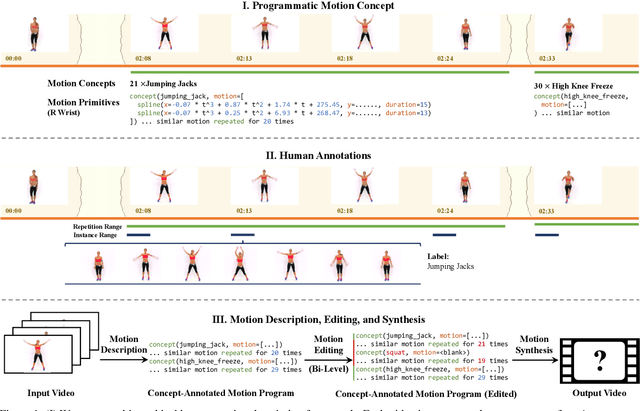
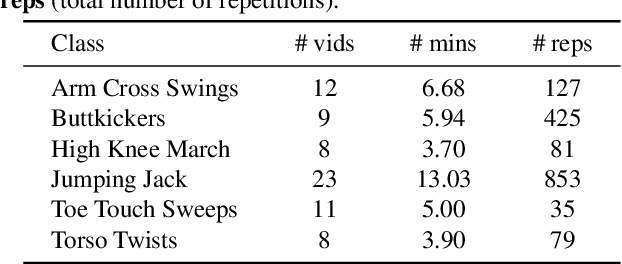
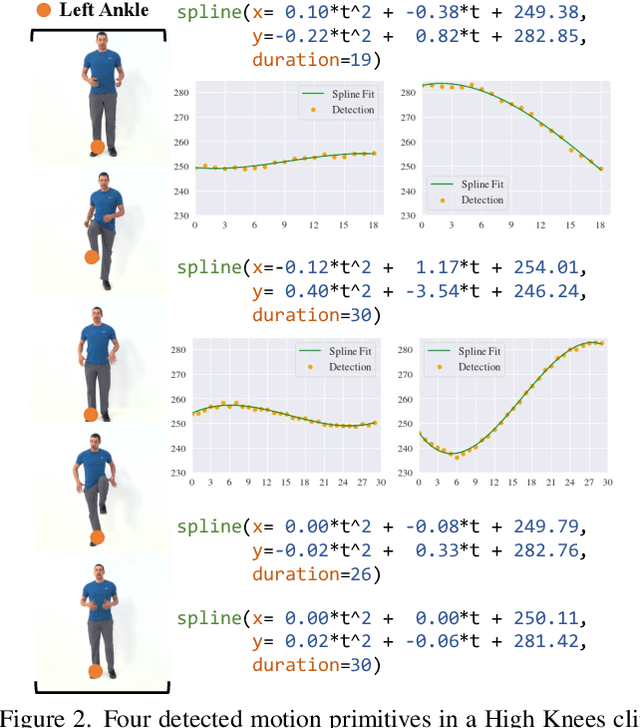
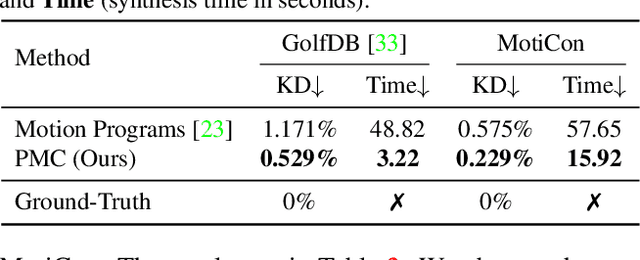
We introduce Programmatic Motion Concepts, a hierarchical motion representation for human actions that captures both low-level motion and high-level description as motion concepts. This representation enables human motion description, interactive editing, and controlled synthesis of novel video sequences within a single framework. We present an architecture that learns this concept representation from paired video and action sequences in a semi-supervised manner. The compactness of our representation also allows us to present a low-resource training recipe for data-efficient learning. By outperforming established baselines, especially in the small data regime, we demonstrate the efficiency and effectiveness of our framework for multiple applications.
Hierarchical Motion Understanding via Motion Programs
Apr 22, 2021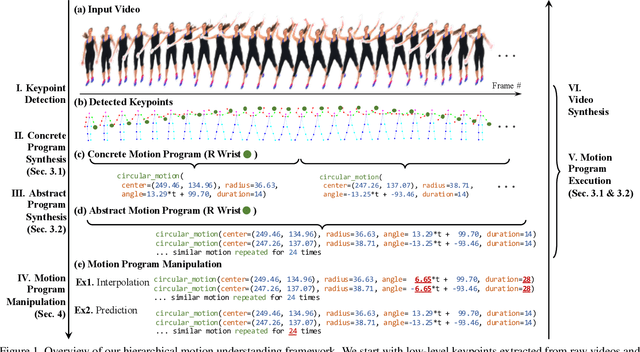


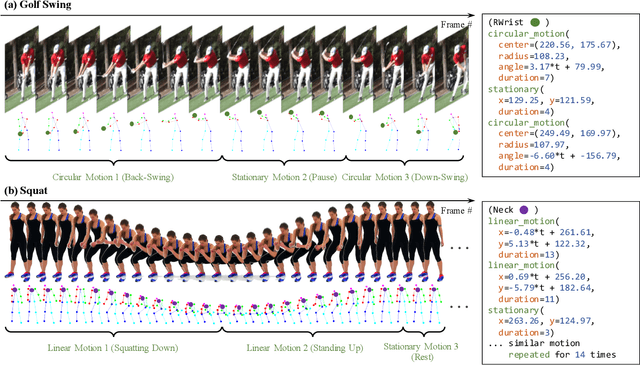
Current approaches to video analysis of human motion focus on raw pixels or keypoints as the basic units of reasoning. We posit that adding higher-level motion primitives, which can capture natural coarser units of motion such as backswing or follow-through, can be used to improve downstream analysis tasks. This higher level of abstraction can also capture key features, such as loops of repeated primitives, that are currently inaccessible at lower levels of representation. We therefore introduce Motion Programs, a neuro-symbolic, program-like representation that expresses motions as a composition of high-level primitives. We also present a system for automatically inducing motion programs from videos of human motion and for leveraging motion programs in video synthesis. Experiments show that motion programs can accurately describe a diverse set of human motions and the inferred programs contain semantically meaningful motion primitives, such as arm swings and jumping jacks. Our representation also benefits downstream tasks such as video interpolation and video prediction and outperforms off-the-shelf models. We further demonstrate how these programs can detect diverse kinds of repetitive motion and facilitate interactive video editing.
SPoC: Search-based Pseudocode to Code
Jun 12, 2019
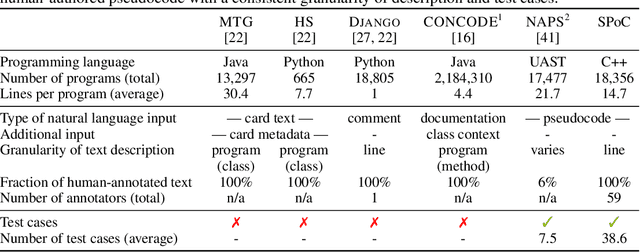
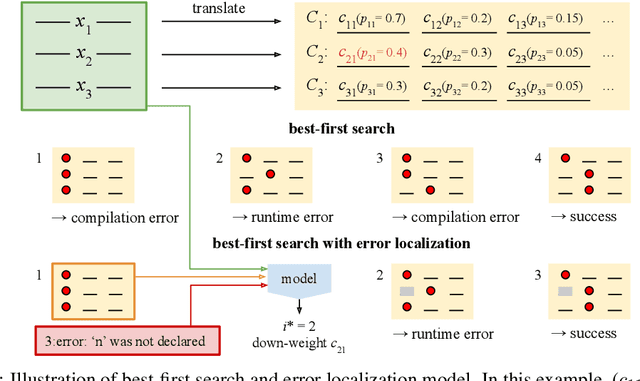
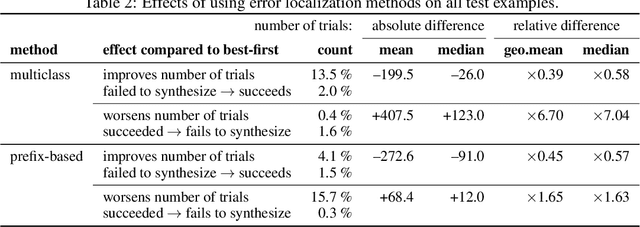
We consider the task of mapping pseudocode to long programs that are functionally correct. Given test cases as a mechanism to validate programs, we search over the space of possible translations of the pseudocode to find a program that passes the validation. However, without proper credit assignment to localize the sources of program failures, it is difficult to guide search toward more promising programs. We propose to perform credit assignment based on signals from compilation errors, which constitute 88.7% of program failures. Concretely, we treat the translation of each pseudocode line as a discrete portion of the program, and whenever a synthesized program fails to compile, an error localization method tries to identify the portion of the program responsible for the failure. We then focus search over alternative translations of the pseudocode for those portions. For evaluation, we collected the SPoC dataset (Search-based Pseudocode to Code) containing 18,356 programs with human-authored pseudocode and test cases. Under a budget of 100 program compilations, performing search improves the synthesis success rate over using the top-one translation of the pseudocode from 25.6% to 44.7%.