 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Rectified Flow Transformers for High-Resolution Image Synthesis
Mar 05, 2024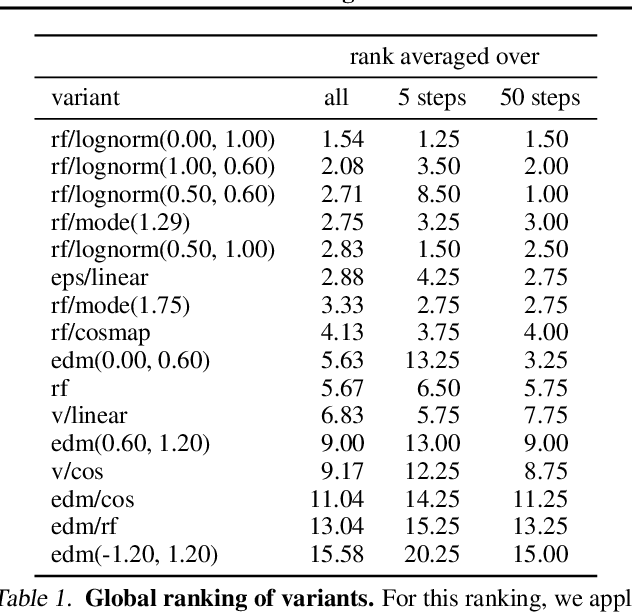
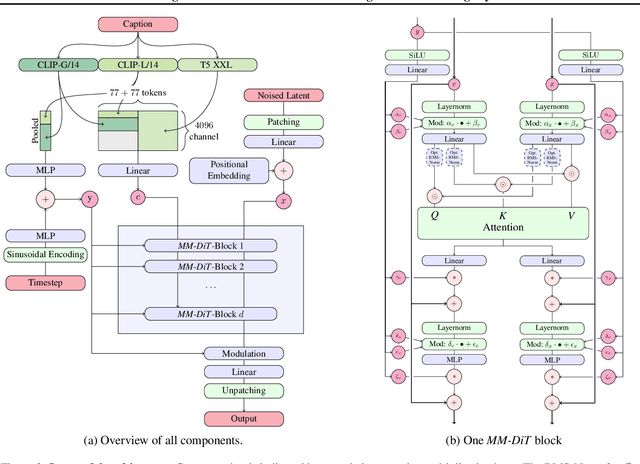
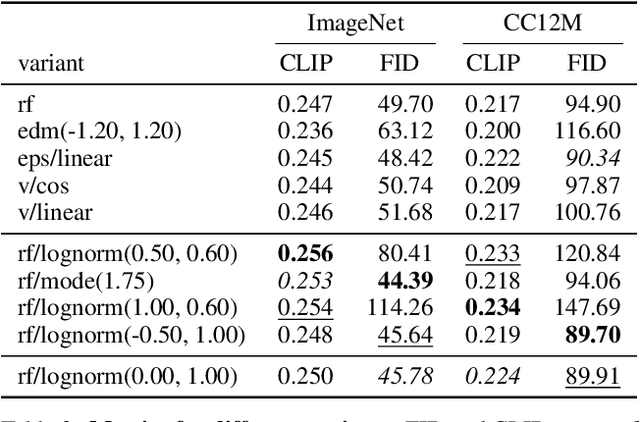
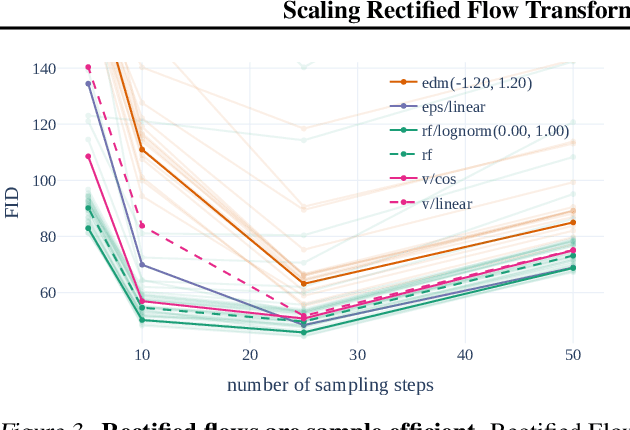
Diffusion models create data from noise by inverting the forward paths of data towards noise and have emerged as a powerful generative modeling technique for high-dimensional, perceptual data such as images and videos. Rectified flow is a recent generative model formulation that connects data and noise in a straight line. Despite its better theoretical properties and conceptual simplicity, it is not yet decisively established as standard practice. In this work, we improve existing noise sampling techniques for training rectified flow models by biasing them towards perceptually relevant scales. Through a large-scale study, we demonstrate the superior performance of this approach compared to established diffusion formulations for high-resolution text-to-image synthesis. Additionally, we present a novel transformer-based architecture for text-to-image generation that uses separate weights for the two modalities and enables a bidirectional flow of information between image and text tokens, improving text comprehension, typography, and human preference ratings. We demonstrate that this architecture follows predictable scaling trends and correlates lower validation loss to improved text-to-image synthesis as measured by various metrics and human evaluations. Our largest models outperform state-of-the-art models, and we will make our experimental data, code, and model weights publicly available.
Stable LM 2 1.6B Technical Report
Feb 27, 2024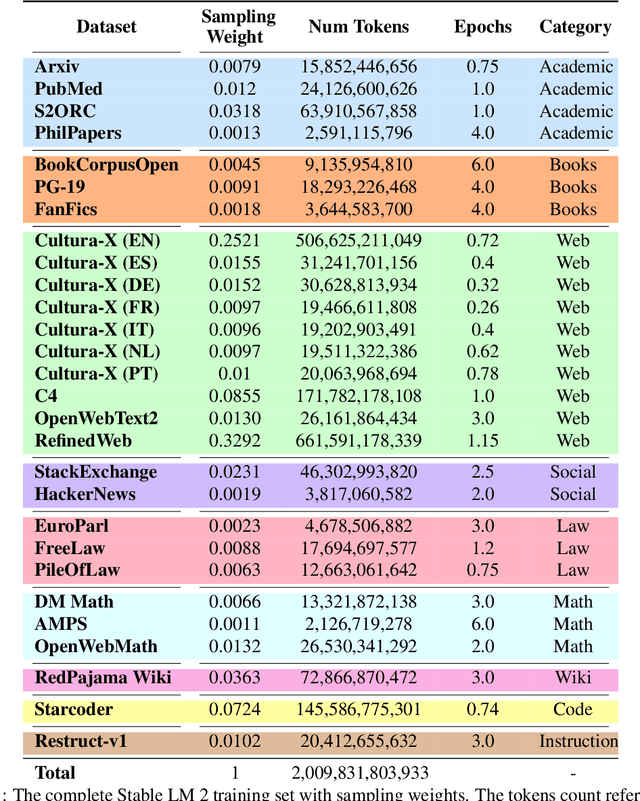
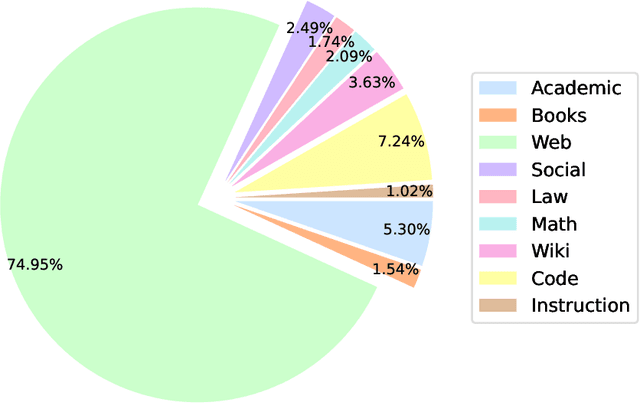
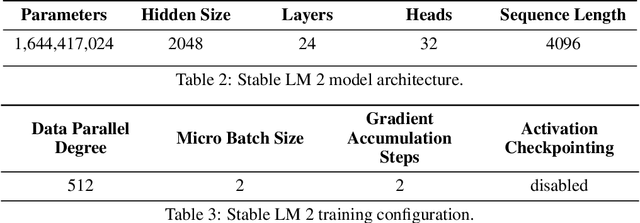
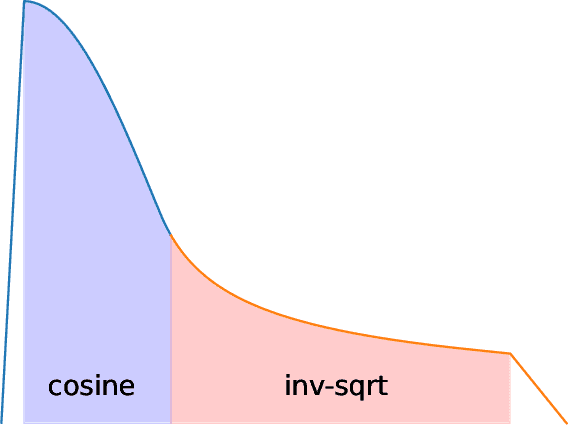
We introduce StableLM 2 1.6B, the first in a new generation of our language model series. In this technical report, we present in detail the data and training procedure leading to the base and instruction-tuned versions of StableLM 2 1.6B. The weights for both models are available via Hugging Face for anyone to download and use. The report contains thorough evaluations of these models, including zero- and few-shot benchmarks, multilingual benchmarks, and the MT benchmark focusing on multi-turn dialogues. At the time of publishing this report, StableLM 2 1.6B was the state-of-the-art open model under 2B parameters by a significant margin. Given its appealing small size, we also provide throughput measurements on a number of edge devices. In addition, we open source several quantized checkpoints and provide their performance metrics compared to the original model.