 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHermes 4 Technical Report
Aug 25, 2025We present Hermes 4, a family of hybrid reasoning models that combine structured, multi-turn reasoning with broad instruction-following ability. We describe the challenges encountered during data curation, synthesis, training, and evaluation, and outline the solutions employed to address these challenges at scale. We comprehensively evaluate across mathematical reasoning, coding, knowledge, comprehension, and alignment benchmarks, and we report both quantitative performance and qualitative behavioral analysis. To support open research, all model weights are published publicly at https://huggingface.co/collections/NousResearch/hermes-4-collection-68a731bfd452e20816725728
Big-Math: A Large-Scale, High-Quality Math Dataset for Reinforcement Learning in Language Models
Feb 24, 2025Increasing interest in reasoning models has led math to become a prominent testing ground for algorithmic and methodological improvements. However, existing open math datasets either contain a small collection of high-quality, human-written problems or a large corpus of machine-generated problems of uncertain quality, forcing researchers to choose between quality and quantity. In this work, we present Big-Math, a dataset of over 250,000 high-quality math questions with verifiable answers, purposefully made for reinforcement learning (RL). To create Big-Math, we rigorously filter, clean, and curate openly available datasets, extracting questions that satisfy our three desiderata: (1) problems with uniquely verifiable solutions, (2) problems that are open-ended, (3) and problems with a closed-form solution. To ensure the quality of Big-Math, we manually verify each step in our filtering process. Based on the findings from our filtering process, we introduce 47,000 new questions with verified answers, Big-Math-Reformulated: closed-ended questions (i.e. multiple choice questions) that have been reformulated as open-ended questions through a systematic reformulation algorithm. Compared to the most commonly used existing open-source datasets for math reasoning, GSM8k and MATH, Big-Math is an order of magnitude larger, while our rigorous filtering ensures that we maintain the questions most suitable for RL. We also provide a rigorous analysis of the dataset, finding that Big-Math contains a high degree of diversity across problem domains, and incorporates a wide range of problem difficulties, enabling a wide range of downstream uses for models of varying capabilities and training requirements. By bridging the gap between data quality and quantity, Big-Math establish a robust foundation for advancing reasoning in LLMs.
Towards System 2 Reasoning in LLMs: Learning How to Think With Meta Chain-of-Thought
Jan 08, 2025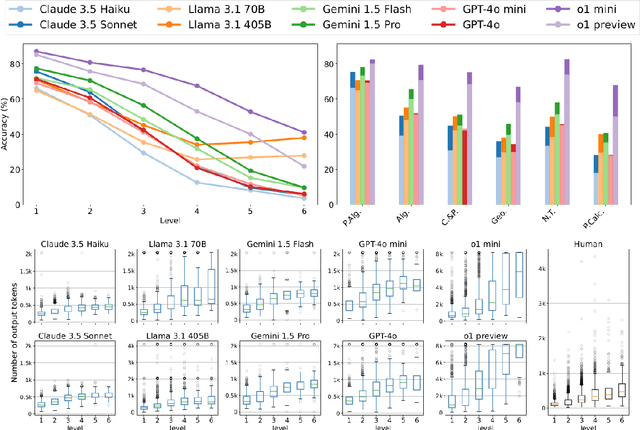
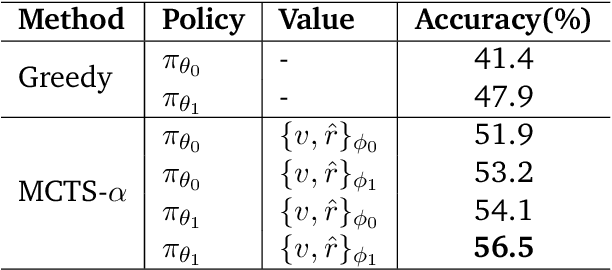
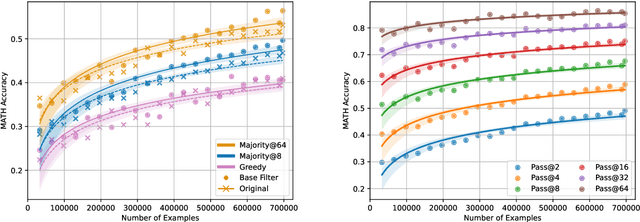
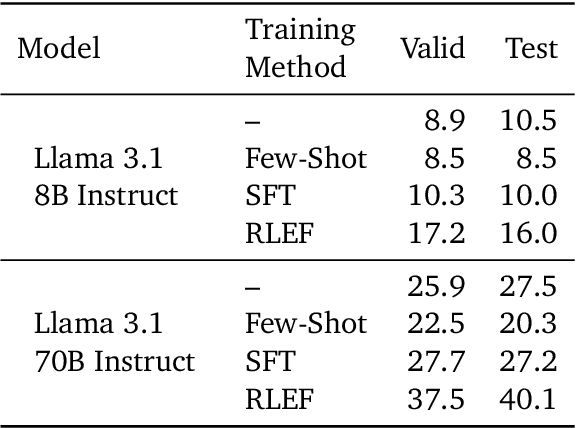
We propose a novel framework, Meta Chain-of-Thought (Meta-CoT), which extends traditional Chain-of-Thought (CoT) by explicitly modeling the underlying reasoning required to arrive at a particular CoT. We present empirical evidence from state-of-the-art models exhibiting behaviors consistent with in-context search, and explore methods for producing Meta-CoT via process supervision, synthetic data generation, and search algorithms. Finally, we outline a concrete pipeline for training a model to produce Meta-CoTs, incorporating instruction tuning with linearized search traces and reinforcement learning post-training. Finally, we discuss open research questions, including scaling laws, verifier roles, and the potential for discovering novel reasoning algorithms. This work provides a theoretical and practical roadmap to enable Meta-CoT in LLMs, paving the way for more powerful and human-like reasoning in artificial intelligence.
Surveying the Effects of Quality, Diversity, and Complexity in Synthetic Data From Large Language Models
Dec 04, 2024



Synthetic data generation with Large Language Models is a promising paradigm for augmenting natural data over a nearly infinite range of tasks. Given this variety, direct comparisons among synthetic data generation algorithms are scarce, making it difficult to understand where improvement comes from and what bottlenecks exist. We propose to evaluate algorithms via the makeup of synthetic data generated by each algorithm in terms of data quality, diversity, and complexity. We choose these three characteristics for their significance in open-ended processes and the impact each has on the capabilities of downstream models. We find quality to be essential for in-distribution model generalization, diversity to be essential for out-of-distribution generalization, and complexity to be beneficial for both. Further, we emphasize the existence of Quality-Diversity trade-offs in training data and the downstream effects on model performance. We then examine the effect of various components in the synthetic data pipeline on each data characteristic. This examination allows us to taxonomize and compare synthetic data generation algorithms through the components they utilize and the resulting effects on data QDC composition. This analysis extends into a discussion on the importance of balancing QDC in synthetic data for efficient reinforcement learning and self-improvement algorithms. Analogous to the QD trade-offs in training data, often there exist trade-offs between model output quality and output diversity which impact the composition of synthetic data. We observe that many models are currently evaluated and optimized only for output quality, thereby limiting output diversity and the potential for self-improvement. We argue that balancing these trade-offs is essential to the development of future self-improvement algorithms and highlight a number of works making progress in this direction.
Stable Code Technical Report
Apr 01, 2024



We introduce Stable Code, the first in our new-generation of code language models series, which serves as a general-purpose base code language model targeting code completion, reasoning, math, and other software engineering-based tasks. Additionally, we introduce an instruction variant named Stable Code Instruct that allows conversing with the model in a natural chat interface for performing question-answering and instruction-based tasks. In this technical report, we detail the data and training procedure leading to both models. Their weights are available via Hugging Face for anyone to download and use at https://huggingface.co/stabilityai/stable-code-3b and https://huggingface.co/stabilityai/stable-code-instruct-3b. This report contains thorough evaluations of the models, including multilingual programming benchmarks, and the MT benchmark focusing on multi-turn dialogues. At the time of its release, Stable Code is the state-of-the-art open model under 3B parameters and even performs comparably to larger models of sizes 7 billion and 15 billion parameters on the popular Multi-PL benchmark. Stable Code Instruct also exhibits state-of-the-art performance on the MT-Bench coding tasks and on Multi-PL completion compared to other instruction tuned models. Given its appealing small size, we also provide throughput measurements on a number of edge devices. In addition, we open source several quantized checkpoints and provide their performance metrics compared to the original model.
Stable LM 2 1.6B Technical Report
Feb 27, 2024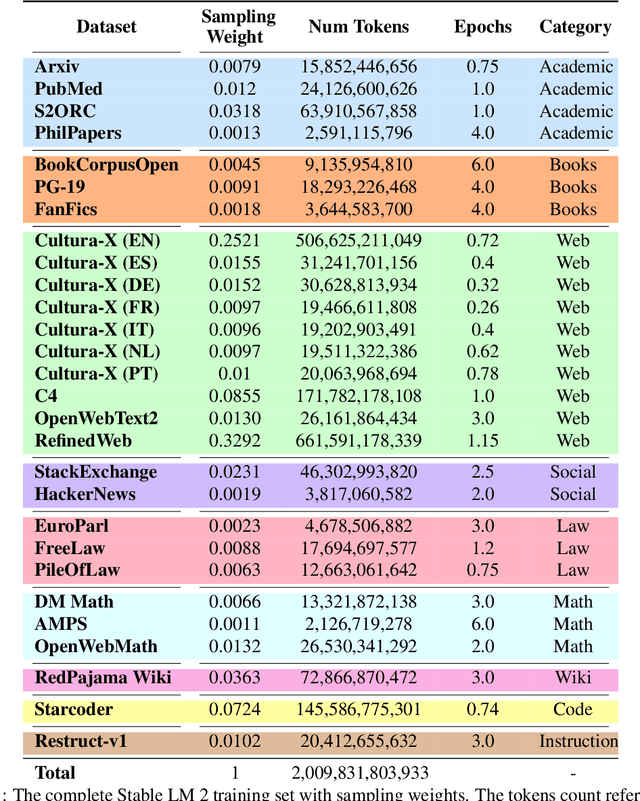
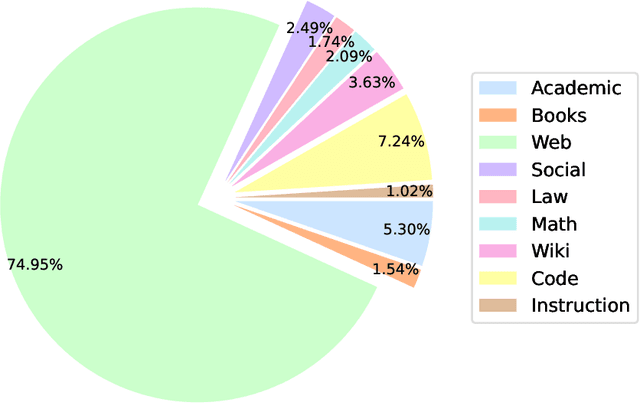
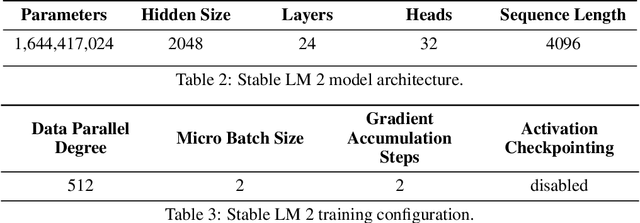
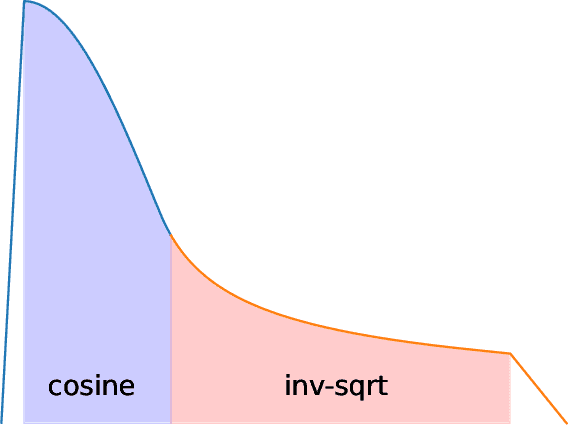
We introduce StableLM 2 1.6B, the first in a new generation of our language model series. In this technical report, we present in detail the data and training procedure leading to the base and instruction-tuned versions of StableLM 2 1.6B. The weights for both models are available via Hugging Face for anyone to download and use. The report contains thorough evaluations of these models, including zero- and few-shot benchmarks, multilingual benchmarks, and the MT benchmark focusing on multi-turn dialogues. At the time of publishing this report, StableLM 2 1.6B was the state-of-the-art open model under 2B parameters by a significant margin. Given its appealing small size, we also provide throughput measurements on a number of edge devices. In addition, we open source several quantized checkpoints and provide their performance metrics compared to the original model.