 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgee3: Learning to Explore Enables Extrapolation of Test-Time Compute for LLMs
Jun 10, 2025Test-time scaling offers a promising path to improve LLM reasoning by utilizing more compute at inference time; however, the true promise of this paradigm lies in extrapolation (i.e., improvement in performance on hard problems as LLMs keep "thinking" for longer, beyond the maximum token budget they were trained on). Surprisingly, we find that most existing reasoning models do not extrapolate well. We show that one way to enable extrapolation is by training the LLM to perform in-context exploration: training the LLM to effectively spend its test time budget by chaining operations (such as generation, verification, refinement, etc.), or testing multiple hypotheses before it commits to an answer. To enable in-context exploration, we identify three key ingredients as part of our recipe e3: (1) chaining skills that the base LLM has asymmetric competence in, e.g., chaining verification (easy) with generation (hard), as a way to implement in-context search; (2) leveraging "negative" gradients from incorrect traces to amplify exploration during RL, resulting in longer search traces that chains additional asymmetries; and (3) coupling task difficulty with training token budget during training via a specifically-designed curriculum to structure in-context exploration. Our recipe e3 produces the best known 1.7B model according to AIME'25 and HMMT'25 scores, and extrapolates to 2x the training token budget. Our e3-1.7B model not only attains high pass@1 scores, but also improves pass@k over the base model.
Learning Adaptive Parallel Reasoning with Language Models
Apr 21, 2025Scaling inference-time computation has substantially improved the reasoning capabilities of language models. However, existing methods have significant limitations: serialized chain-of-thought approaches generate overly long outputs, leading to increased latency and exhausted context windows, while parallel methods such as self-consistency suffer from insufficient coordination, resulting in redundant computations and limited performance gains. To address these shortcomings, we propose Adaptive Parallel Reasoning (APR), a novel reasoning framework that enables language models to orchestrate both serialized and parallel computations end-to-end. APR generalizes existing reasoning methods by enabling adaptive multi-threaded inference using spawn() and join() operations. A key innovation is our end-to-end reinforcement learning strategy, optimizing both parent and child inference threads to enhance task success rate without requiring predefined reasoning structures. Experiments on the Countdown reasoning task demonstrate significant benefits of APR: (1) higher performance within the same context window (83.4% vs. 60.0% at 4k context); (2) superior scalability with increased computation (80.1% vs. 66.6% at 20k total tokens); (3) improved accuracy at equivalent latency (75.2% vs. 57.3% at approximately 5,000ms). APR represents a step towards enabling language models to autonomously optimize their reasoning processes through adaptive allocation of computation.
Sleep-time Compute: Beyond Inference Scaling at Test-time
Apr 17, 2025Scaling test-time compute has emerged as a key ingredient for enabling large language models (LLMs) to solve difficult problems, but comes with high latency and inference cost. We introduce sleep-time compute, which allows models to "think" offline about contexts before queries are presented: by anticipating what queries users might ask and pre-computing useful quantities, we can significantly reduce the compute requirements at test-time. To demonstrate the efficacy of our method, we create modified versions of two reasoning tasks - Stateful GSM-Symbolic and Stateful AIME. We find that sleep-time compute can reduce the amount of test-time compute needed to achieve the same accuracy by ~ 5x on Stateful GSM-Symbolic and Stateful AIME and that by scaling sleep-time compute we can further increase accuracy by up to 13% on Stateful GSM-Symbolic and 18% on Stateful AIME. Furthermore, we introduce Multi-Query GSM-Symbolic, which extends GSM-Symbolic by including multiple related queries per context. By amortizing sleep-time compute across related queries about the same context using Multi-Query GSM-Symbolic, we can decrease the average cost per query by 2.5x. We then conduct additional analysis to understand when sleep-time compute is most effective, finding the predictability of the user query to be well correlated with the efficacy of sleep-time compute. Finally, we conduct a case-study of applying sleep-time compute to a realistic agentic SWE task.
Reasoning Models Can Be Effective Without Thinking
Apr 14, 2025Recent LLMs have significantly improved reasoning capabilities, primarily by including an explicit, lengthy Thinking process as part of generation. In this paper, we question whether this explicit thinking is necessary. Using the state-of-the-art DeepSeek-R1-Distill-Qwen, we find that bypassing the thinking process via simple prompting, denoted as NoThinking, can be surprisingly effective. When controlling for the number of tokens, NoThinking outperforms Thinking across a diverse set of seven challenging reasoning datasets--including mathematical problem solving, formal theorem proving, and coding--especially in low-budget settings, e.g., 51.3 vs. 28.9 on ACM 23 with 700 tokens. Notably, the performance of NoThinking becomes more competitive with pass@k as k increases. Building on this observation, we demonstrate that a parallel scaling approach that uses NoThinking to generate N outputs independently and aggregates them is highly effective. For aggregation, we use task-specific verifiers when available, or we apply simple best-of-N strategies such as confidence-based selection. Our method outperforms a range of baselines with similar latency using Thinking, and is comparable to Thinking with significantly longer latency (up to 9x). Together, our research encourages a reconsideration of the necessity of lengthy thinking processes, while also establishing a competitive reference for achieving strong reasoning performance in low-budget settings or at low latency using parallel scaling.
Value-Based Deep RL Scales Predictably
Feb 06, 2025Scaling data and compute is critical to the success of machine learning. However, scaling demands predictability: we want methods to not only perform well with more compute or data, but also have their performance be predictable from small-scale runs, without running the large-scale experiment. In this paper, we show that value-based off-policy RL methods are predictable despite community lore regarding their pathological behavior. First, we show that data and compute requirements to attain a given performance level lie on a Pareto frontier, controlled by the updates-to-data (UTD) ratio. By estimating this frontier, we can predict this data requirement when given more compute, and this compute requirement when given more data. Second, we determine the optimal allocation of a total resource budget across data and compute for a given performance and use it to determine hyperparameters that maximize performance for a given budget. Third, this scaling behavior is enabled by first estimating predictable relationships between hyperparameters, which is used to manage effects of overfitting and plasticity loss unique to RL. We validate our approach using three algorithms: SAC, BRO, and PQL on DeepMind Control, OpenAI gym, and IsaacGym, when extrapolating to higher levels of data, compute, budget, or performance.
Towards System 2 Reasoning in LLMs: Learning How to Think With Meta Chain-of-Thought
Jan 08, 2025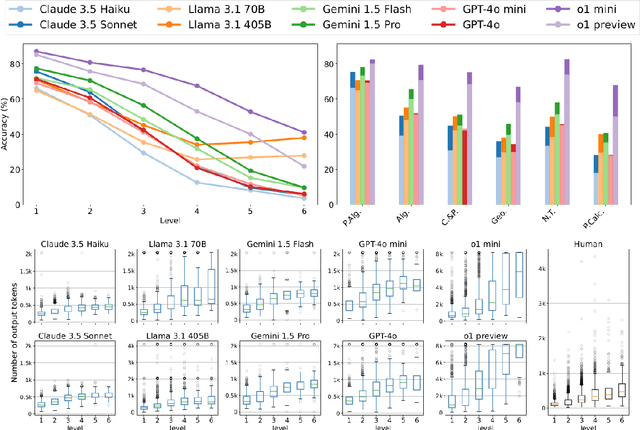
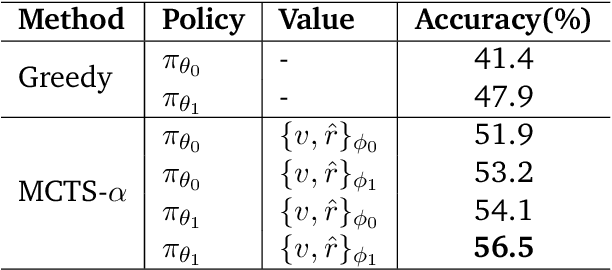
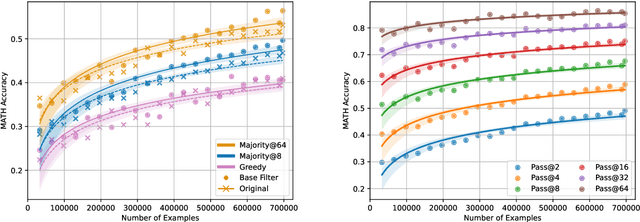
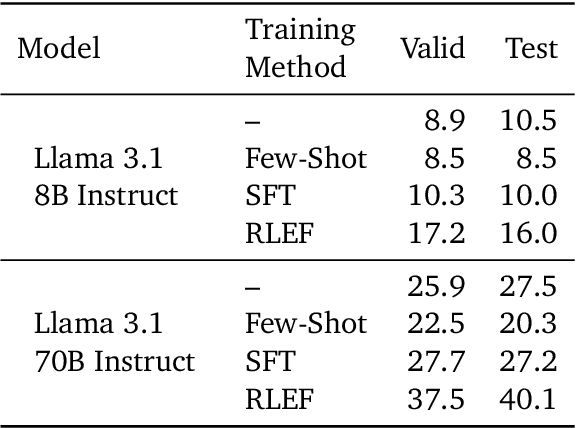
We propose a novel framework, Meta Chain-of-Thought (Meta-CoT), which extends traditional Chain-of-Thought (CoT) by explicitly modeling the underlying reasoning required to arrive at a particular CoT. We present empirical evidence from state-of-the-art models exhibiting behaviors consistent with in-context search, and explore methods for producing Meta-CoT via process supervision, synthetic data generation, and search algorithms. Finally, we outline a concrete pipeline for training a model to produce Meta-CoTs, incorporating instruction tuning with linearized search traces and reinforcement learning post-training. Finally, we discuss open research questions, including scaling laws, verifier roles, and the potential for discovering novel reasoning algorithms. This work provides a theoretical and practical roadmap to enable Meta-CoT in LLMs, paving the way for more powerful and human-like reasoning in artificial intelligence.
Predicting Emergent Capabilities by Finetuning
Nov 25, 2024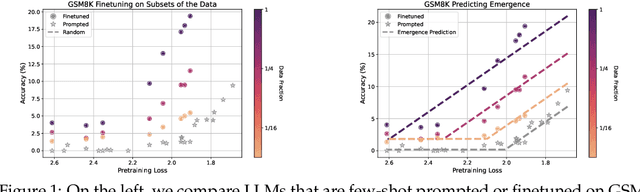

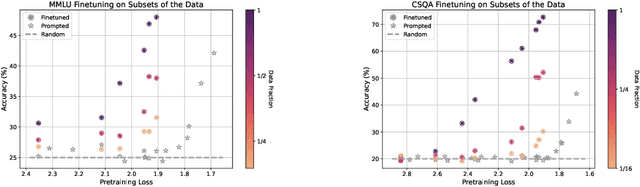
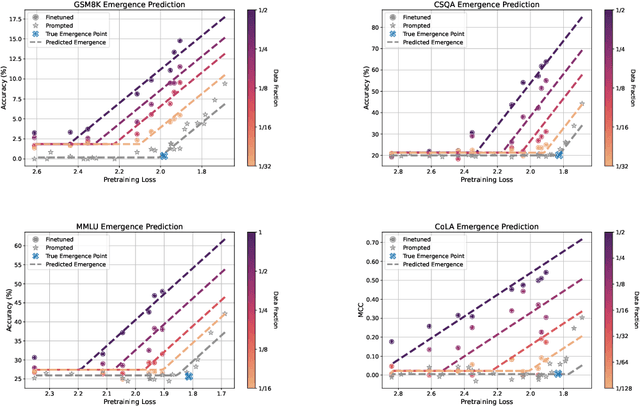
A fundamental open challenge in modern LLM scaling is the lack of understanding around emergent capabilities. In particular, language model pretraining loss is known to be highly predictable as a function of compute. However, downstream capabilities are far less predictable -- sometimes even exhibiting emergent jumps -- which makes it challenging to anticipate the capabilities of future models. In this work, we first pose the task of emergence prediction: given access to current LLMs that have random few-shot accuracy on a task, can we predict whether future models (GPT-N+1) will have non-trivial accuracy on that task? We then discover a simple insight for this problem: finetuning LLMs on a given task can shift the point in scaling at which emergence occurs towards less capable models. To operationalize this insight, we can finetune LLMs with varying amounts of data and fit a parametric function that predicts when emergence will occur (i.e., "emergence laws"). We validate this approach using four standard NLP benchmarks where large-scale open-source LLMs already demonstrate emergence (MMLU, GSM8K, CommonsenseQA, and CoLA). Using only small-scale LLMs, we find that, in some cases, we can accurately predict whether models trained with up to 4x more compute have emerged. Finally, we present a case study of two realistic uses for emergence prediction.
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
Aug 06, 2024
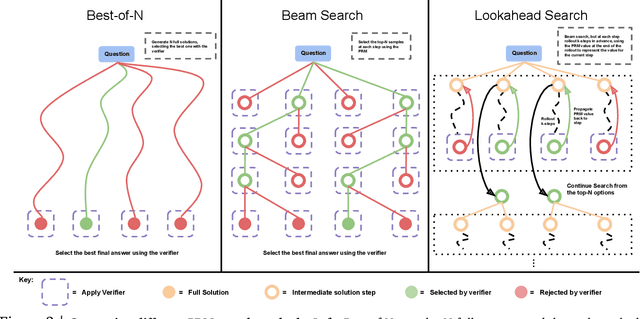
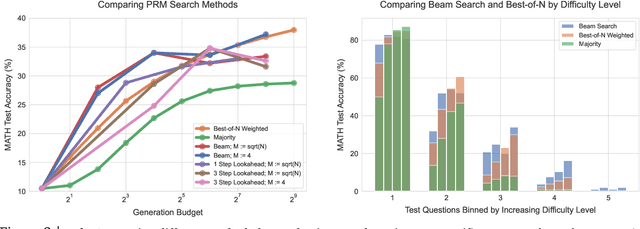
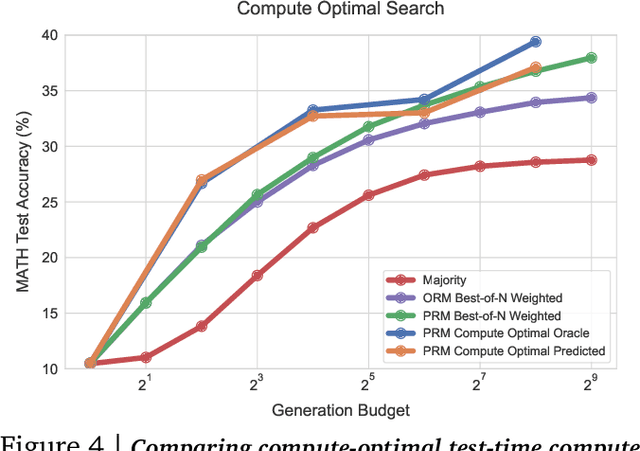
Enabling LLMs to improve their outputs by using more test-time computation is a critical step towards building generally self-improving agents that can operate on open-ended natural language. In this paper, we study the scaling of inference-time computation in LLMs, with a focus on answering the question: if an LLM is allowed to use a fixed but non-trivial amount of inference-time compute, how much can it improve its performance on a challenging prompt? Answering this question has implications not only on the achievable performance of LLMs, but also on the future of LLM pretraining and how one should tradeoff inference-time and pre-training compute. Despite its importance, little research attempted to understand the scaling behaviors of various test-time inference methods. Moreover, current work largely provides negative results for a number of these strategies. In this work, we analyze two primary mechanisms to scale test-time computation: (1) searching against dense, process-based verifier reward models; and (2) updating the model's distribution over a response adaptively, given the prompt at test time. We find that in both cases, the effectiveness of different approaches to scaling test-time compute critically varies depending on the difficulty of the prompt. This observation motivates applying a "compute-optimal" scaling strategy, which acts to most effectively allocate test-time compute adaptively per prompt. Using this compute-optimal strategy, we can improve the efficiency of test-time compute scaling by more than 4x compared to a best-of-N baseline. Additionally, in a FLOPs-matched evaluation, we find that on problems where a smaller base model attains somewhat non-trivial success rates, test-time compute can be used to outperform a 14x larger model.
LMRL Gym: Benchmarks for Multi-Turn Reinforcement Learning with Language Models
Nov 30, 2023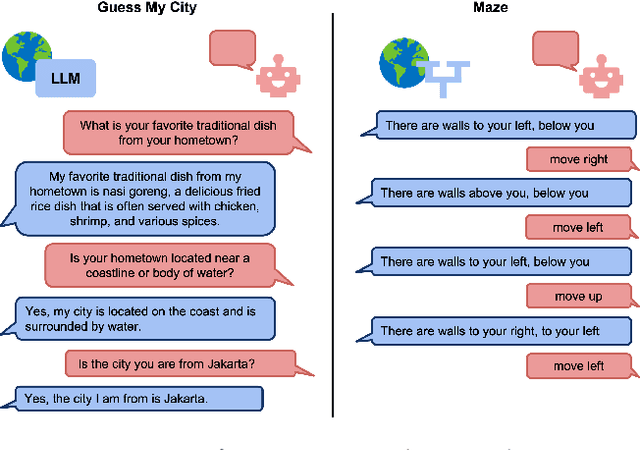
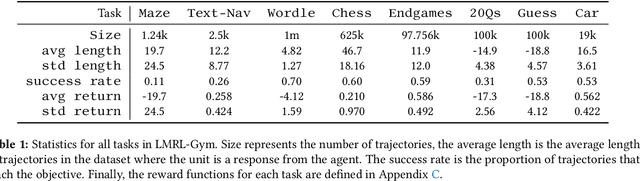
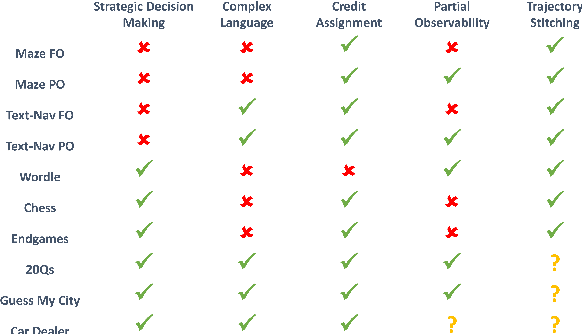
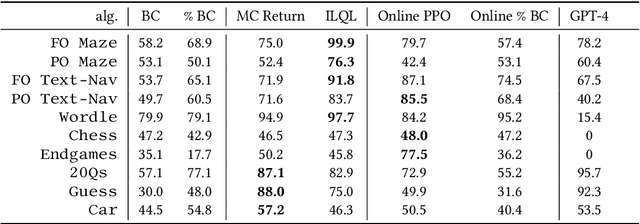
Large language models (LLMs) provide excellent text-generation capabilities, but standard prompting and generation methods generally do not lead to intentional or goal-directed agents and might necessitate considerable prompt tuning. This becomes particularly apparent in multi-turn conversations: even the best current LLMs rarely ask clarifying questions, engage in explicit information gathering, or take actions now that lead to better decisions after multiple turns. Reinforcement learning has the potential to leverage the powerful modeling capabilities of LLMs, as well as their internal representation of textual interactions, to create capable goal-directed language agents. This can enable intentional and temporally extended interactions, such as with humans, through coordinated persuasion and carefully crafted questions, or in goal-directed play through text games to bring about desired final outcomes. However, enabling this requires the community to develop stable and reliable reinforcement learning algorithms that can effectively train LLMs. Developing such algorithms requires tasks that can gauge progress on algorithm design, provide accessible and reproducible evaluations for multi-turn interactions, and cover a range of task properties and challenges in improving reinforcement learning algorithms. Our paper introduces the LMRL-Gym benchmark for evaluating multi-turn RL for LLMs, together with an open-source research framework containing a basic toolkit for getting started on multi-turn RL with offline value-based and policy-based RL methods. Our benchmark consists of 8 different language tasks, which require multiple rounds of language interaction and cover a range of tasks in open-ended dialogue and text games.
The False Promise of Imitating Proprietary LLMs
May 25, 2023



An emerging method to cheaply improve a weaker language model is to finetune it on outputs from a stronger model, such as a proprietary system like ChatGPT (e.g., Alpaca, Self-Instruct, and others). This approach looks to cheaply imitate the proprietary model's capabilities using a weaker open-source model. In this work, we critically analyze this approach. We first finetune a series of LMs that imitate ChatGPT using varying base model sizes (1.5B--13B), data sources, and imitation data amounts (0.3M--150M tokens). We then evaluate the models using crowd raters and canonical NLP benchmarks. Initially, we were surprised by the output quality of our imitation models -- they appear far better at following instructions, and crowd workers rate their outputs as competitive with ChatGPT. However, when conducting more targeted automatic evaluations, we find that imitation models close little to none of the gap from the base LM to ChatGPT on tasks that are not heavily supported in the imitation data. We show that these performance discrepancies may slip past human raters because imitation models are adept at mimicking ChatGPT's style but not its factuality. Overall, we conclude that model imitation is a false promise: there exists a substantial capabilities gap between open and closed LMs that, with current methods, can only be bridged using an unwieldy amount of imitation data or by using more capable base LMs. In turn, we argue that the highest leverage action for improving open-source models is to tackle the difficult challenge of developing better base LMs, rather than taking the shortcut of imitating proprietary systems.