 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSleep-time Compute: Beyond Inference Scaling at Test-time
Apr 17, 2025Scaling test-time compute has emerged as a key ingredient for enabling large language models (LLMs) to solve difficult problems, but comes with high latency and inference cost. We introduce sleep-time compute, which allows models to "think" offline about contexts before queries are presented: by anticipating what queries users might ask and pre-computing useful quantities, we can significantly reduce the compute requirements at test-time. To demonstrate the efficacy of our method, we create modified versions of two reasoning tasks - Stateful GSM-Symbolic and Stateful AIME. We find that sleep-time compute can reduce the amount of test-time compute needed to achieve the same accuracy by ~ 5x on Stateful GSM-Symbolic and Stateful AIME and that by scaling sleep-time compute we can further increase accuracy by up to 13% on Stateful GSM-Symbolic and 18% on Stateful AIME. Furthermore, we introduce Multi-Query GSM-Symbolic, which extends GSM-Symbolic by including multiple related queries per context. By amortizing sleep-time compute across related queries about the same context using Multi-Query GSM-Symbolic, we can decrease the average cost per query by 2.5x. We then conduct additional analysis to understand when sleep-time compute is most effective, finding the predictability of the user query to be well correlated with the efficacy of sleep-time compute. Finally, we conduct a case-study of applying sleep-time compute to a realistic agentic SWE task.
CARFF: Conditional Auto-encoded Radiance Field for 3D Scene Forecasting
Jan 31, 2024



We propose CARFF: Conditional Auto-encoded Radiance Field for 3D Scene Forecasting, a method for predicting future 3D scenes given past observations, such as 2D ego-centric images. Our method maps an image to a distribution over plausible 3D latent scene configurations using a probabilistic encoder, and predicts the evolution of the hypothesized scenes through time. Our latent scene representation conditions a global Neural Radiance Field (NeRF) to represent a 3D scene model, which enables explainable predictions and straightforward downstream applications. This approach extends beyond previous neural rendering work by considering complex scenarios of uncertainty in environmental states and dynamics. We employ a two-stage training of Pose-Conditional-VAE and NeRF to learn 3D representations. Additionally, we auto-regressively predict latent scene representations as a partially observable Markov decision process, utilizing a mixture density network. We demonstrate the utility of our method in realistic scenarios using the CARLA driving simulator, where CARFF can be used to enable efficient trajectory and contingency planning in complex multi-agent autonomous driving scenarios involving visual occlusions.
MemGPT: Towards LLMs as Operating Systems
Oct 12, 2023



Large language models (LLMs) have revolutionized AI, but are constrained by limited context windows, hindering their utility in tasks like extended conversations and document analysis. To enable using context beyond limited context windows, we propose virtual context management, a technique drawing inspiration from hierarchical memory systems in traditional operating systems that provide the appearance of large memory resources through data movement between fast and slow memory. Using this technique, we introduce MemGPT (Memory-GPT), a system that intelligently manages different memory tiers in order to effectively provide extended context within the LLM's limited context window, and utilizes interrupts to manage control flow between itself and the user. We evaluate our OS-inspired design in two domains where the limited context windows of modern LLMs severely handicaps their performance: document analysis, where MemGPT is able to analyze large documents that far exceed the underlying LLM's context window, and multi-session chat, where MemGPT can create conversational agents that remember, reflect, and evolve dynamically through long-term interactions with their users. We release MemGPT code and data for our experiments at https://memgpt.ai.
Hindsight Task Relabelling: Experience Replay for Sparse Reward Meta-RL
Dec 02, 2021



Meta-reinforcement learning (meta-RL) has proven to be a successful framework for leveraging experience from prior tasks to rapidly learn new related tasks, however, current meta-RL approaches struggle to learn in sparse reward environments. Although existing meta-RL algorithms can learn strategies for adapting to new sparse reward tasks, the actual adaptation strategies are learned using hand-shaped reward functions, or require simple environments where random exploration is sufficient to encounter sparse reward. In this paper, we present a formulation of hindsight relabeling for meta-RL, which relabels experience during meta-training to enable learning to learn entirely using sparse reward. We demonstrate the effectiveness of our approach on a suite of challenging sparse reward goal-reaching environments that previously required dense reward during meta-training to solve. Our approach solves these environments using the true sparse reward function, with performance comparable to training with a proxy dense reward function.
Contingencies from Observations: Tractable Contingency Planning with Learned Behavior Models
Apr 21, 2021



Humans have a remarkable ability to make decisions by accurately reasoning about future events, including the future behaviors and states of mind of other agents. Consider driving a car through a busy intersection: it is necessary to reason about the physics of the vehicle, the intentions of other drivers, and their beliefs about your own intentions. If you signal a turn, another driver might yield to you, or if you enter the passing lane, another driver might decelerate to give you room to merge in front. Competent drivers must plan how they can safely react to a variety of potential future behaviors of other agents before they make their next move. This requires contingency planning: explicitly planning a set of conditional actions that depend on the stochastic outcome of future events. In this work, we develop a general-purpose contingency planner that is learned end-to-end using high-dimensional scene observations and low-dimensional behavioral observations. We use a conditional autoregressive flow model to create a compact contingency planning space, and show how this model can tractably learn contingencies from behavioral observations. We developed a closed-loop control benchmark of realistic multi-agent scenarios in a driving simulator (CARLA), on which we compare our method to various noncontingent methods that reason about multi-agent future behavior, including several state-of-the-art deep learning-based planning approaches. We illustrate that these noncontingent planning methods fundamentally fail on this benchmark, and find that our deep contingency planning method achieves significantly superior performance. Code to run our benchmark and reproduce our results is available at https://sites.google.com/view/contingency-planning
Assessing Generalization in Deep Reinforcement Learning
Oct 29, 2018


Deep reinforcement learning (RL) has achieved breakthrough results on many tasks, but has been shown to be sensitive to system changes at test time. As a result, building deep RL agents that generalize has become an active research area. Our aim is to catalyze and streamline community-wide progress on this problem by providing the first benchmark and a common experimental protocol for investigating generalization in RL. Our benchmark contains a diverse set of environments and our evaluation methodology covers both in-distribution and out-of-distribution generalization. To provide a set of baselines for future research, we conduct a systematic evaluation of deep RL algorithms, including those that specifically tackle the problem of generalization.
Visually-Aware Personalized Recommendation using Interpretable Image Representations
Aug 21, 2018
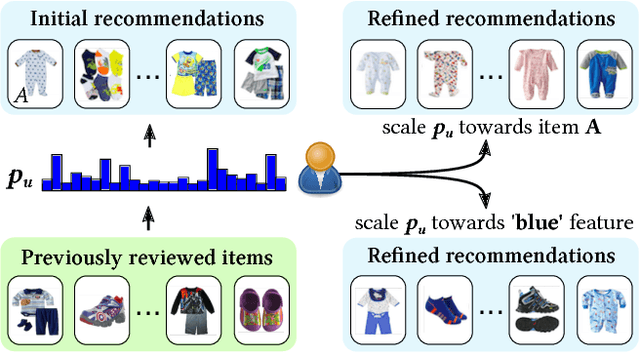


Visually-aware recommender systems use visual signals present in the underlying data to model the visual characteristics of items and users' preferences towards them. In the domain of clothing recommendation, incorporating items' visual information (e.g., product images) is particularly important since clothing item appearance is often a critical factor in influencing the user's purchasing decisions. Current state-of-the-art visually-aware recommender systems utilize image features extracted from pre-trained deep convolutional neural networks, however these extremely high-dimensional representations are difficult to interpret, especially in relation to the relatively low number of visual properties that may guide users' decisions. In this paper we propose a novel approach to personalized clothing recommendation that models the dynamics of individual users' visual preferences. By using interpretable image representations generated with a unique feature learning process, our model learns to explain users' prior feedback in terms of their affinity towards specific visual attributes and styles. Our approach achieves state-of-the-art performance on personalized ranking tasks, and the incorporation of interpretable visual features allows for powerful model introspection, which we demonstrate by using an interactive recommendation algorithm and visualizing the rise and fall of fashion trends over time.
Learning Compatibility Across Categories for Heterogeneous Item Recommendation
Sep 29, 2016

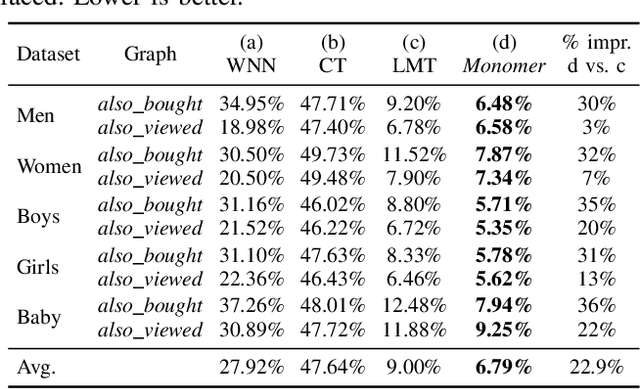
Identifying relationships between items is a key task of an online recommender system, in order to help users discover items that are functionally complementary or visually compatible. In domains like clothing recommendation, this task is particularly challenging since a successful system should be capable of handling a large corpus of items, a huge amount of relationships among them, as well as the high-dimensional and semantically complicated features involved. Furthermore, the human notion of "compatibility" to capture goes beyond mere similarity: For two items to be compatible---whether jeans and a t-shirt, or a laptop and a charger---they should be similar in some ways, but systematically different in others. In this paper we propose a novel method, Monomer, to learn complicated and heterogeneous relationships between items in product recommendation settings. Recently, scalable methods have been developed that address this task by learning similarity metrics on top of the content of the products involved. Here our method relaxes the metricity assumption inherent in previous work and models multiple localized notions of 'relatedness,' so as to uncover ways in which related items should be systematically similar, and systematically different. Quantitatively, we show that our system achieves state-of-the-art performance on large-scale compatibility prediction tasks, especially in cases where there is substantial heterogeneity between related items. Qualitatively, we demonstrate that richer notions of compatibility can be learned that go beyond similarity, and that our model can make effective recommendations of heterogeneous content.