 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoWorld: Scaling Multi-Agent Traffic Simulation with Self-Supervised World Models
Mar 30, 2026Multi-agent traffic simulation is central to developing and testing autonomous driving systems. Recent data-driven simulators have achieved promising results, but rely heavily on supervised learning from labeled trajectories or semantic annotations, making it costly to scale their performance. Meanwhile, large amounts of unlabeled sensor data can be collected at scale but remain largely unused by existing traffic simulation frameworks. This raises a key question: How can a method harness unlabeled data to improve traffic simulation performance? In this work, we propose AutoWorld, a traffic simulation framework that employs a world model learned from unlabeled occupancy representations of LiDAR data. Given world model samples, AutoWorld constructs a coarse-to-fine predictive scene context as input to a multi-agent motion generation model. To promote sample diversity, AutoWorld uses a cascaded Determinantal Point Process framework to guide the sampling processes of both the world model and the motion model. Furthermore, we designed a motion-aware latent supervision objective that enhances AutoWorld's representation of scene dynamics. Experiments on the WOSAC benchmark show that AutoWorld ranks first on the leaderboard according to the primary Realism Meta Metric (RMM). We further show that simulation performance consistently improves with the inclusion of unlabeled LiDAR data, and study the efficacy of each component with ablations. Our method paves the way for scaling traffic simulation realism without additional labeling. Our project page contains additional visualizations and released code.
OccSim: Multi-kilometer Simulation with Long-horizon Occupancy World Models
Mar 30, 2026Data-driven autonomous driving simulation has long been constrained by its heavy reliance on pre-recorded driving logs or spatial priors, such as HD maps. This fundamental dependency severely limits scalability, restricting open-ended generation capabilities to the finite scale of existing collected datasets. To break this bottleneck, we present OccSim, the first occupancy world model-driven 3D simulator. OccSim obviates the requirement for continuous logs or HD maps; conditioned only on a single initial frame and a sequence of future ego-actions, it can stably generate over 3,000 continuous frames, enabling the continuous construction of large-scale 3D occupancy maps spanning over 4 kilometers for simulation. This represents an >80x improvement in stable generation length over previous state-of-the-art occupancy world models. OccSim is powered by two modules: W-DiT based static occupancy world model and the Layout Generator. W-DiT handles the ultra-long-horizon generation of static environments by explicitly introducing known rigid transformations in architecture design, while the Layout Generator populates the dynamic foreground with reactive agents based on the synthesized road topology. With these designs, OccSim can synthesize massive, diverse simulation streams. Extensive experiments demonstrate its downstream utility: data collected directly from OccSim can pre-train 4D semantic occupancy forecasting models to achieve up to 67% zero-shot performance on unseen data, outperforming previous asset-based simulator by 11%. When scaling the OccSim dataset to 5x the size, the zero-shot performance increases to about 74%, while the improvement over asset-based simulators expands to 22.1%.
DR-MPC: Deep Residual Model Predictive Control for Real-world Social Navigation
Oct 14, 2024



How can a robot safely navigate around people exhibiting complex motion patterns? Reinforcement Learning (RL) or Deep RL (DRL) in simulation holds some promise, although much prior work relies on simulators that fail to precisely capture the nuances of real human motion. To address this gap, we propose Deep Residual Model Predictive Control (DR-MPC), a method to enable robots to quickly and safely perform DRL from real-world crowd navigation data. By blending MPC with model-free DRL, DR-MPC overcomes the traditional DRL challenges of large data requirements and unsafe initial behavior. DR-MPC is initialized with MPC-based path tracking, and gradually learns to interact more effectively with humans. To further accelerate learning, a safety component estimates when the robot encounters out-of-distribution states and guides it away from likely collisions. In simulation, we show that DR-MPC substantially outperforms prior work, including traditional DRL and residual DRL models. Real-world experiments show our approach successfully enables a robot to navigate a variety of crowded situations with few errors using less than 4 hours of training data.
CARFF: Conditional Auto-encoded Radiance Field for 3D Scene Forecasting
Jan 31, 2024



We propose CARFF: Conditional Auto-encoded Radiance Field for 3D Scene Forecasting, a method for predicting future 3D scenes given past observations, such as 2D ego-centric images. Our method maps an image to a distribution over plausible 3D latent scene configurations using a probabilistic encoder, and predicts the evolution of the hypothesized scenes through time. Our latent scene representation conditions a global Neural Radiance Field (NeRF) to represent a 3D scene model, which enables explainable predictions and straightforward downstream applications. This approach extends beyond previous neural rendering work by considering complex scenarios of uncertainty in environmental states and dynamics. We employ a two-stage training of Pose-Conditional-VAE and NeRF to learn 3D representations. Additionally, we auto-regressively predict latent scene representations as a partially observable Markov decision process, utilizing a mixture density network. We demonstrate the utility of our method in realistic scenarios using the CARLA driving simulator, where CARFF can be used to enable efficient trajectory and contingency planning in complex multi-agent autonomous driving scenarios involving visual occlusions.
Information is Power: Intrinsic Control via Information Capture
Dec 07, 2021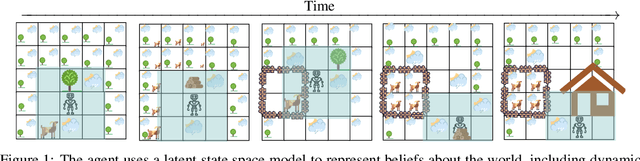


Humans and animals explore their environment and acquire useful skills even in the absence of clear goals, exhibiting intrinsic motivation. The study of intrinsic motivation in artificial agents is concerned with the following question: what is a good general-purpose objective for an agent? We study this question in dynamic partially-observed environments, and argue that a compact and general learning objective is to minimize the entropy of the agent's state visitation estimated using a latent state-space model. This objective induces an agent to both gather information about its environment, corresponding to reducing uncertainty, and to gain control over its environment, corresponding to reducing the unpredictability of future world states. We instantiate this approach as a deep reinforcement learning agent equipped with a deep variational Bayes filter. We find that our agent learns to discover, represent, and exercise control of dynamic objects in a variety of partially-observed environments sensed with visual observations without extrinsic reward.
Hybrid Imitative Planning with Geometric and Predictive Costs in Off-road Environments
Nov 22, 2021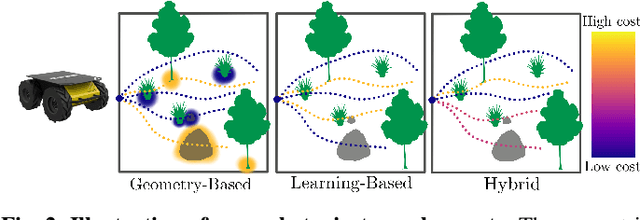
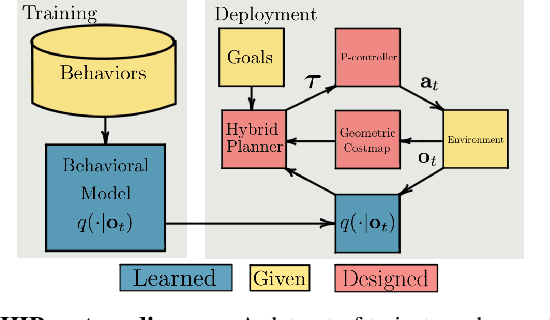
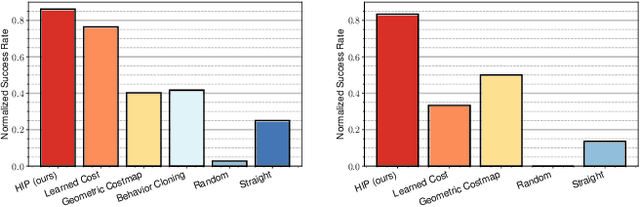

Geometric methods for solving open-world off-road navigation tasks, by learning occupancy and metric maps, provide good generalization but can be brittle in outdoor environments that violate their assumptions (e.g., tall grass). Learning-based methods can directly learn collision-free behavior from raw observations, but are difficult to integrate with standard geometry-based pipelines. This creates an unfortunate conflict -- either use learning and lose out on well-understood geometric navigational components, or do not use it, in favor of extensively hand-tuned geometry-based cost maps. In this work, we reject this dichotomy by designing the learning and non-learning-based components in a way such that they can be effectively combined in a self-supervised manner. Both components contribute to a planning criterion: the learned component contributes predicted traversability as rewards, while the geometric component contributes obstacle cost information. We instantiate and comparatively evaluate our system in both in-distribution and out-of-distribution environments, showing that this approach inherits complementary gains from the learned and geometric components and significantly outperforms either of them. Videos of our results are hosted at https://sites.google.com/view/hybrid-imitative-planning
Explore and Control with Adversarial Surprise
Jul 12, 2021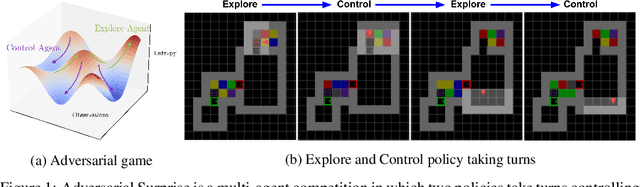
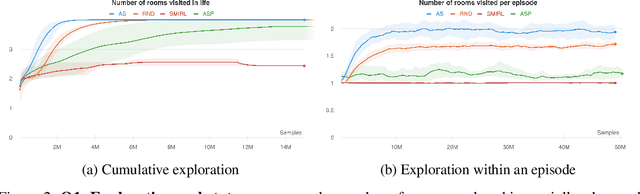
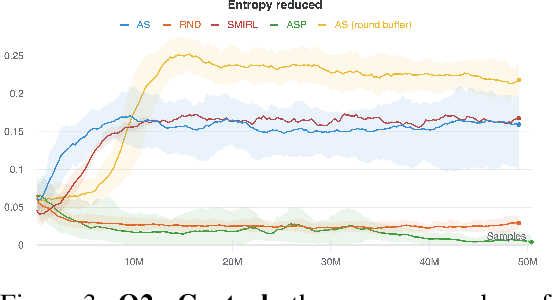
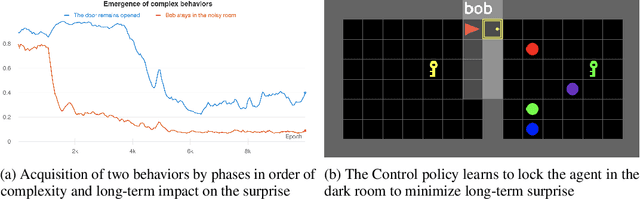
Reinforcement learning (RL) provides a framework for learning goal-directed policies given user-specified rewards. However, since designing rewards often requires substantial engineering effort, we are interested in the problem of learning without rewards, where agents must discover useful behaviors in the absence of task-specific incentives. Intrinsic motivation is a family of unsupervised RL techniques which develop general objectives for an RL agent to optimize that lead to better exploration or the discovery of skills. In this paper, we propose a new unsupervised RL technique based on an adversarial game which pits two policies against each other to compete over the amount of surprise an RL agent experiences. The policies each take turns controlling the agent. The Explore policy maximizes entropy, putting the agent into surprising or unfamiliar situations. Then, the Control policy takes over and seeks to recover from those situations by minimizing entropy. The game harnesses the power of multi-agent competition to drive the agent to seek out increasingly surprising parts of the environment while learning to gain mastery over them. We show empirically that our method leads to the emergence of complex skills by exhibiting clear phase transitions. Furthermore, we show both theoretically (via a latent state space coverage argument) and empirically that our method has the potential to be applied to the exploration of stochastic, partially-observed environments. We show that Adversarial Surprise learns more complex behaviors, and explores more effectively than competitive baselines, outperforming intrinsic motivation methods based on active inference, novelty-seeking (Random Network Distillation (RND)), and multi-agent unsupervised RL (Asymmetric Self-Play (ASP)) in MiniGrid, Atari and VizDoom environments.
Contingencies from Observations: Tractable Contingency Planning with Learned Behavior Models
Apr 21, 2021



Humans have a remarkable ability to make decisions by accurately reasoning about future events, including the future behaviors and states of mind of other agents. Consider driving a car through a busy intersection: it is necessary to reason about the physics of the vehicle, the intentions of other drivers, and their beliefs about your own intentions. If you signal a turn, another driver might yield to you, or if you enter the passing lane, another driver might decelerate to give you room to merge in front. Competent drivers must plan how they can safely react to a variety of potential future behaviors of other agents before they make their next move. This requires contingency planning: explicitly planning a set of conditional actions that depend on the stochastic outcome of future events. In this work, we develop a general-purpose contingency planner that is learned end-to-end using high-dimensional scene observations and low-dimensional behavioral observations. We use a conditional autoregressive flow model to create a compact contingency planning space, and show how this model can tractably learn contingencies from behavioral observations. We developed a closed-loop control benchmark of realistic multi-agent scenarios in a driving simulator (CARLA), on which we compare our method to various noncontingent methods that reason about multi-agent future behavior, including several state-of-the-art deep learning-based planning approaches. We illustrate that these noncontingent planning methods fundamentally fail on this benchmark, and find that our deep contingency planning method achieves significantly superior performance. Code to run our benchmark and reproduce our results is available at https://sites.google.com/view/contingency-planning
RECON: Rapid Exploration for Open-World Navigation with Latent Goal Models
Apr 14, 2021
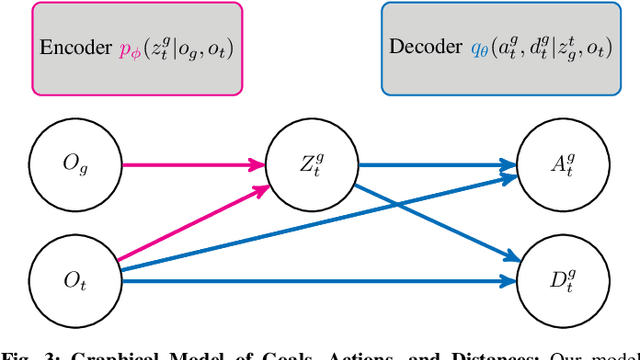
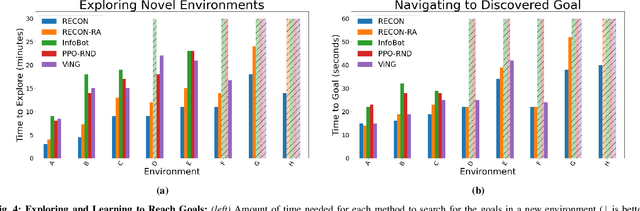
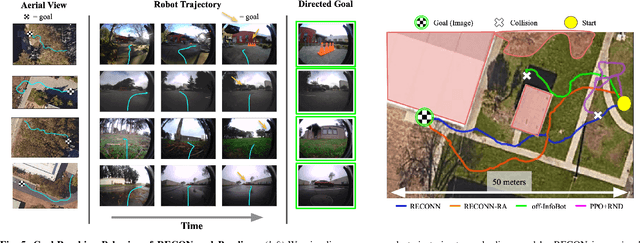
We describe a robotic learning system for autonomous navigation in diverse environments. At the core of our method are two components: (i) a non-parametric map that reflects the connectivity of the environment but does not require geometric reconstruction or localization, and (ii) a latent variable model of distances and actions that enables efficiently constructing and traversing this map. The model is trained on a large dataset of prior experience to predict the expected amount of time and next action needed to transit between the current image and a goal image. Training the model in this way enables it to develop a representation of goals robust to distracting information in the input images, which aids in deploying the system to quickly explore new environments. We demonstrate our method on a mobile ground robot in a range of outdoor navigation scenarios. Our method can learn to reach new goals, specified as images, in a radius of up to 80 meters in just 20 minutes, and reliably revisit these goals in changing environments. We also demonstrate our method's robustness to previously-unseen obstacles and variable weather conditions. We encourage the reader to visit the project website for videos of our experiments and demonstrations https://sites.google.com/view/recon-robot
ViNG: Learning Open-World Navigation with Visual Goals
Dec 17, 2020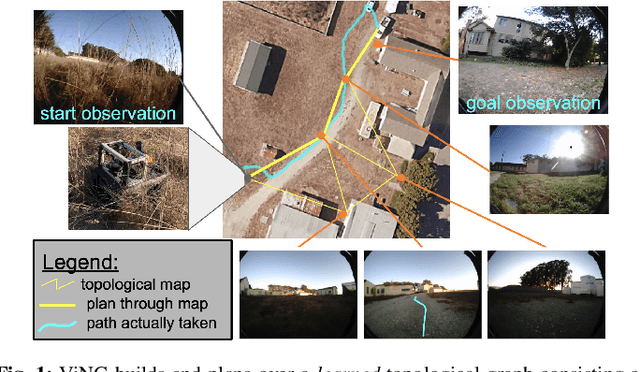

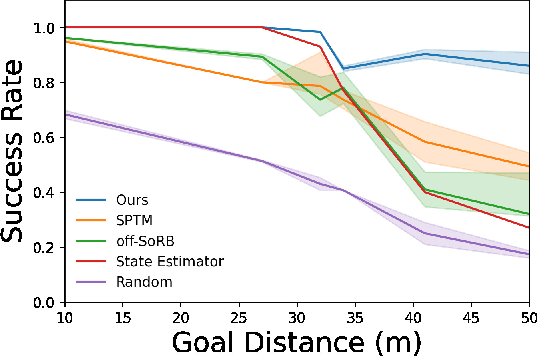
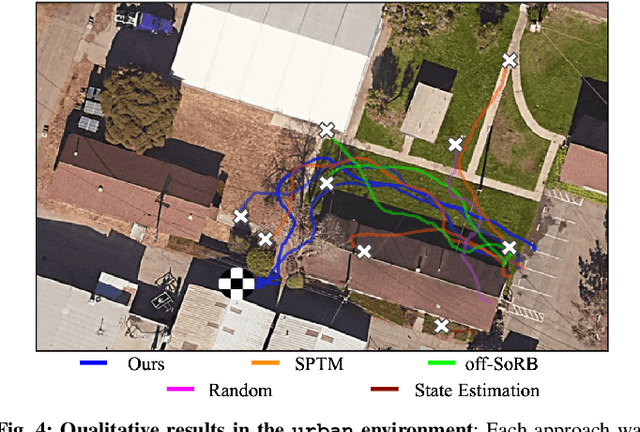
We propose a learning-based navigation system for reaching visually indicated goals and demonstrate this system on a real mobile robot platform. Learning provides an appealing alternative to conventional methods for robotic navigation: instead of reasoning about environments in terms of geometry and maps, learning can enable a robot to learn about navigational affordances, understand what types of obstacles are traversable (e.g., tall grass) or not (e.g., walls), and generalize over patterns in the environment. However, unlike conventional planning algorithms, it is harder to change the goal for a learned policy during deployment. We propose a method for learning to navigate towards a goal image of the desired destination. By combining a learned policy with a topological graph constructed out of previously observed data, our system can determine how to reach this visually indicated goal even in the presence of variable appearance and lighting. Three key insights, waypoint proposal, graph pruning and negative mining, enable our method to learn to navigate in real-world environments using only offline data, a setting where prior methods struggle. We instantiate our method on a real outdoor ground robot and show that our system, which we call ViNG, outperforms previously-proposed methods for goal-conditioned reinforcement learning, including other methods that incorporate reinforcement learning and search. We also study how ViNG generalizes to unseen environments and evaluate its ability to adapt to such an environment with growing experience. Finally, we demonstrate ViNG on a number of real-world applications, such as last-mile delivery and warehouse inspection. We encourage the reader to check out the videos of our experiments and demonstrations at our project website https://sites.google.com/view/ving-robot