 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniQueR: Unified Query-based Feedforward 3D Reconstruction
Mar 24, 2026We present UniQueR, a unified query-based feedforward framework for efficient and accurate 3D reconstruction from unposed images. Existing feedforward models such as DUSt3R, VGGT, and AnySplat typically predict per-pixel point maps or pixel-aligned Gaussians, which remain fundamentally 2.5D and limited to visible surfaces. In contrast, UniQueR formulates reconstruction as a sparse 3D query inference problem. Our model learns a compact set of 3D anchor points that act as explicit geometric queries, enabling the network to infer scene structure, including geometry in occluded regions--in a single forward pass. Each query encodes spatial and appearance priors directly in global 3D space (instead of per-frame camera space) and spawns a set of 3D Gaussians for differentiable rendering. By leveraging unified query interactions across multi-view features and a decoupled cross-attention design, UniQueR achieves strong geometric expressiveness while substantially reducing memory and computational cost. Experiments on Mip-NeRF 360 and VR-NeRF demonstrate that UniQueR surpasses state-of-the-art feedforward methods in both rendering quality and geometric accuracy, using an order of magnitude fewer primitives than dense alternatives.
RAYNOVA: Scale-Temporal Autoregressive World Modeling in Ray Space
Feb 25, 2026World foundation models aim to simulate the evolution of the real world with physically plausible behavior. Unlike prior methods that handle spatial and temporal correlations separately, we propose RAYNOVA, a geometry-agonistic multiview world model for driving scenarios that employs a dual-causal autoregressive framework. It follows both scale-wise and temporal topological orders in the autoregressive process, and leverages global attention for unified 4D spatio-temporal reasoning. Different from existing works that impose strong 3D geometric priors, RAYNOVA constructs an isotropic spatio-temporal representation across views, frames, and scales based on relative Plücker-ray positional encoding, enabling robust generalization to diverse camera setups and ego motions. We further introduce a recurrent training paradigm to alleviate distribution drift in long-horizon video generation. RAYNOVA achieves state-of-the-art multi-view video generation results on nuScenes, while offering higher throughput and strong controllability under diverse input conditions, generalizing to novel views and camera configurations without explicit 3D scene representation. Our code will be released at https://raynova-ai.github.io/.
Learning to Drive is a Free Gift: Large-Scale Label-Free Autonomy Pretraining from Unposed In-The-Wild Videos
Feb 25, 2026Ego-centric driving videos available online provide an abundant source of visual data for autonomous driving, yet their lack of annotations makes it difficult to learn representations that capture both semantic structure and 3D geometry. Recent advances in large feedforward spatial models demonstrate that point maps and ego-motion can be inferred in a single forward pass, suggesting a promising direction for scalable driving perception. We therefore propose a label-free, teacher-guided framework for learning autonomous driving representations directly from unposed videos. Unlike prior self-supervised approaches that focus primarily on frame-to-frame consistency, we posit that safe and reactive driving depends critically on temporal context. To this end, we leverage a feedforward architecture equipped with a lightweight autoregressive module, trained using multi-modal supervisory signals that guide the model to jointly predict current and future point maps, camera poses, semantic segmentation, and motion masks. Multi-modal teachers provide sequence-level pseudo-supervision, enabling LFG to learn a unified pseudo-4D representation from raw YouTube videos without poses, labels, or LiDAR. The resulting encoder not only transfers effectively to downstream autonomous driving planning on the NAVSIM benchmark, surpassing multi-camera and LiDAR baselines with only a single monocular camera, but also yields strong performance when evaluated on a range of semantic, geometric, and qualitative motion prediction tasks. These geometry and motion-aware features position LFG as a compelling video-centric foundation model for autonomous driving.
PreF3R: Pose-Free Feed-Forward 3D Gaussian Splatting from Variable-length Image Sequence
Nov 25, 2024
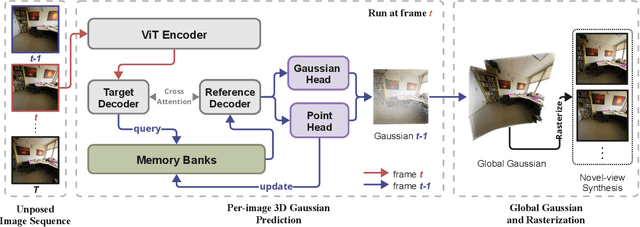


We present PreF3R, Pose-Free Feed-forward 3D Reconstruction from an image sequence of variable length. Unlike previous approaches, PreF3R removes the need for camera calibration and reconstructs the 3D Gaussian field within a canonical coordinate frame directly from a sequence of unposed images, enabling efficient novel-view rendering. We leverage DUSt3R's ability for pair-wise 3D structure reconstruction, and extend it to sequential multi-view input via a spatial memory network, eliminating the need for optimization-based global alignment. Additionally, PreF3R incorporates a dense Gaussian parameter prediction head, which enables subsequent novel-view synthesis with differentiable rasterization. This allows supervising our model with the combination of photometric loss and pointmap regression loss, enhancing both photorealism and structural accuracy. Given a sequence of ordered images, PreF3R incrementally reconstructs the 3D Gaussian field at 20 FPS, therefore enabling real-time novel-view rendering. Empirical experiments demonstrate that PreF3R is an effective solution for the challenging task of pose-free feed-forward novel-view synthesis, while also exhibiting robust generalization to unseen scenes.
CARFF: Conditional Auto-encoded Radiance Field for 3D Scene Forecasting
Jan 31, 2024



We propose CARFF: Conditional Auto-encoded Radiance Field for 3D Scene Forecasting, a method for predicting future 3D scenes given past observations, such as 2D ego-centric images. Our method maps an image to a distribution over plausible 3D latent scene configurations using a probabilistic encoder, and predicts the evolution of the hypothesized scenes through time. Our latent scene representation conditions a global Neural Radiance Field (NeRF) to represent a 3D scene model, which enables explainable predictions and straightforward downstream applications. This approach extends beyond previous neural rendering work by considering complex scenarios of uncertainty in environmental states and dynamics. We employ a two-stage training of Pose-Conditional-VAE and NeRF to learn 3D representations. Additionally, we auto-regressively predict latent scene representations as a partially observable Markov decision process, utilizing a mixture density network. We demonstrate the utility of our method in realistic scenarios using the CARLA driving simulator, where CARFF can be used to enable efficient trajectory and contingency planning in complex multi-agent autonomous driving scenarios involving visual occlusions.
Diversify Your Vision Datasets with Automatic Diffusion-Based Augmentation
May 25, 2023



Many fine-grained classification tasks, like rare animal identification, have limited training data and consequently classifiers trained on these datasets often fail to generalize to variations in the domain like changes in weather or location. As such, we explore how natural language descriptions of the domains seen in training data can be used with large vision models trained on diverse pretraining datasets to generate useful variations of the training data. We introduce ALIA (Automated Language-guided Image Augmentation), a method which utilizes large vision and language models to automatically generate natural language descriptions of a dataset's domains and augment the training data via language-guided image editing. To maintain data integrity, a model trained on the original dataset filters out minimal image edits and those which corrupt class-relevant information. The resulting dataset is visually consistent with the original training data and offers significantly enhanced diversity. On fine-grained and cluttered datasets for classification and detection, ALIA surpasses traditional data augmentation and text-to-image generated data by up to 15\%, often even outperforming equivalent additions of real data. Code is avilable at https://github.com/lisadunlap/ALIA.