 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecon: Reconstruction-Guided Reasoning Synthesis for User Modeling
May 26, 2026User modeling aims to use language models (LMs) to mimic an individual's behavior from a corpus of past context-action pairs (e.g., conversation turns), enabling the simulation of users in settings like behavioral science, human-AI collaboration, and market research. Recent approaches augment these corpora with synthesized reasoning traces, typically generated by conditioning on both context and action. However, such conditioning constitutes post-hoc rationalization rather than reasoning: the trace is guaranteed to justify the action, but may not encode the underlying latent causal decision paths. We propose Recon, which uses action reconstruction to score reasoning traces by their predictive power: given a context and candidate reasoning, a reconstruction model predicts the action, and reconstruction fidelity determines reasoning quality. Across four domains, Recon achieves a 54.7% win rate over Backward Synthesis, a standard post-hoc rationalization baseline. Further, we find that training a reasoning synthesis model with rewards derived from Recon improves downstream user modeling performance, achieving a win rate of up to 70.0% over baselines. We further show that Recon-synthesized reasoning transfers across models, and improves user modeling beyond the reconstruction model. Our work demonstrates that post-hoc rationalization is insufficient for reasoning synthesis, and that useful and interpretable reasoning should naturally elicit the action from the context.
VisGym: Diverse, Customizable, Scalable Environments for Multimodal Agents
Jan 23, 2026Modern Vision-Language Models (VLMs) remain poorly characterized in multi-step visual interactions, particularly in how they integrate perception, memory, and action over long horizons. We introduce VisGym, a gymnasium of 17 environments for evaluating and training VLMs. The suite spans symbolic puzzles, real-image understanding, navigation, and manipulation, and provides flexible controls over difficulty, input representation, planning horizon, and feedback. We also provide multi-step solvers that generate structured demonstrations, enabling supervised finetuning. Our evaluations show that all frontier models struggle in interactive settings, achieving low success rates in both the easy (46.6%) and hard (26.0%) configurations. Our experiments reveal notable limitations: models struggle to effectively leverage long context, performing worse with an unbounded history than with truncated windows. Furthermore, we find that several text-based symbolic tasks become substantially harder once rendered visually. However, explicit goal observations, textual feedback, and exploratory demonstrations in partially observable or unknown-dynamics settings for supervised finetuning yield consistent gains, highlighting concrete failure modes and pathways for improving multi-step visual decision-making. Code, data, and models can be found at: https://visgym.github.io/.
Visually Prompted Benchmarks Are Surprisingly Fragile
Dec 19, 2025



A key challenge in evaluating VLMs is testing models' ability to analyze visual content independently from their textual priors. Recent benchmarks such as BLINK probe visual perception through visual prompting, where questions about visual content are paired with coordinates to which the question refers, with the coordinates explicitly marked in the image itself. While these benchmarks are an important part of VLM evaluation, we find that existing models are surprisingly fragile to seemingly irrelevant details of visual prompting: simply changing a visual marker from red to blue can completely change rankings among models on a leaderboard. By evaluating nine commonly-used open- and closed-source VLMs on two visually prompted tasks, we demonstrate how details in benchmark setup, including visual marker design and dataset size, have a significant influence on model performance and leaderboard rankings. These effects can even be exploited to lift weaker models above stronger ones; for instance, slightly increasing the size of the visual marker results in open-source InternVL3-8B ranking alongside or better than much larger proprietary models like Gemini 2.5 Pro. We further show that low-level inference choices that are often ignored in benchmarking, such as JPEG compression levels in API calls, can also cause model lineup changes. These details have substantially larger impacts on visually prompted benchmarks than on conventional semantic VLM evaluations. To mitigate this instability, we curate existing datasets to create VPBench, a larger visually prompted benchmark with 16 visual marker variants. VPBench and additional analysis tools are released at https://lisadunlap.github.io/vpbench/.
Interpretable Embeddings with Sparse Autoencoders: A Data Analysis Toolkit
Dec 10, 2025Analyzing large-scale text corpora is a core challenge in machine learning, crucial for tasks like identifying undesirable model behaviors or biases in training data. Current methods often rely on costly LLM-based techniques (e.g. annotating dataset differences) or dense embedding models (e.g. for clustering), which lack control over the properties of interest. We propose using sparse autoencoders (SAEs) to create SAE embeddings: representations whose dimensions map to interpretable concepts. Through four data analysis tasks, we show that SAE embeddings are more cost-effective and reliable than LLMs and more controllable than dense embeddings. Using the large hypothesis space of SAEs, we can uncover insights such as (1) semantic differences between datasets and (2) unexpected concept correlations in documents. For instance, by comparing model responses, we find that Grok-4 clarifies ambiguities more often than nine other frontier models. Relative to LLMs, SAE embeddings uncover bigger differences at 2-8x lower cost and identify biases more reliably. Additionally, SAE embeddings are controllable: by filtering concepts, we can (3) cluster documents along axes of interest and (4) outperform dense embeddings on property-based retrieval. Using SAE embeddings, we study model behavior with two case studies: investigating how OpenAI model behavior has changed over time and finding "trigger" phrases learned by Tulu-3 (Lambert et al., 2024) from its training data. These results position SAEs as a versatile tool for unstructured data analysis and highlight the neglected importance of interpreting models through their data.
Discovering Divergent Representations between Text-to-Image Models
Sep 10, 2025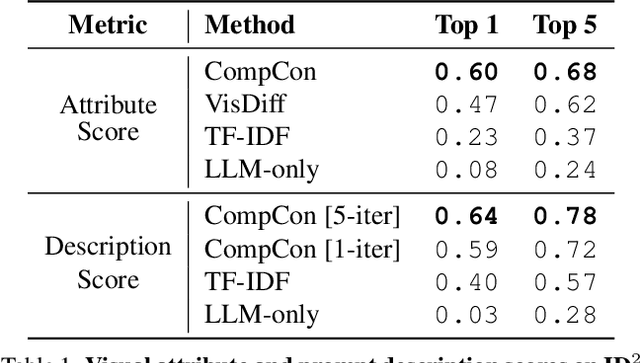
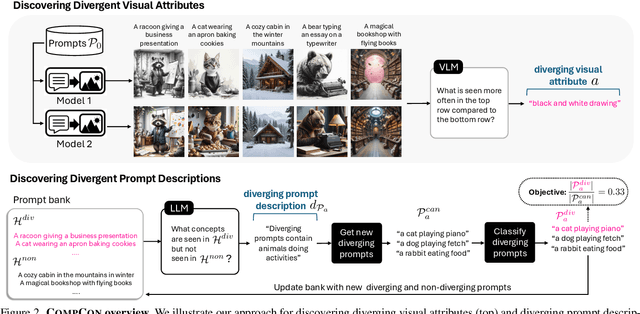


In this paper, we investigate when and how visual representations learned by two different generative models diverge. Given two text-to-image models, our goal is to discover visual attributes that appear in images generated by one model but not the other, along with the types of prompts that trigger these attribute differences. For example, "flames" might appear in one model's outputs when given prompts expressing strong emotions, while the other model does not produce this attribute given the same prompts. We introduce CompCon (Comparing Concepts), an evolutionary search algorithm that discovers visual attributes more prevalent in one model's output than the other, and uncovers the prompt concepts linked to these visual differences. To evaluate CompCon's ability to find diverging representations, we create an automated data generation pipeline to produce ID2, a dataset of 60 input-dependent differences, and compare our approach to several LLM- and VLM-powered baselines. Finally, we use CompCon to compare popular text-to-image models, finding divergent representations such as how PixArt depicts prompts mentioning loneliness with wet streets and Stable Diffusion 3.5 depicts African American people in media professions. Code at: https://github.com/adobe-research/CompCon
Video Action Differencing
Mar 10, 2025How do two individuals differ when performing the same action? In this work, we introduce Video Action Differencing (VidDiff), the novel task of identifying subtle differences between videos of the same action, which has many applications, such as coaching and skill learning. To enable development on this new task, we first create VidDiffBench, a benchmark dataset containing 549 video pairs, with human annotations of 4,469 fine-grained action differences and 2,075 localization timestamps indicating where these differences occur. Our experiments demonstrate that VidDiffBench poses a significant challenge for state-of-the-art large multimodal models (LMMs), such as GPT-4o and Qwen2-VL. By analyzing failure cases of LMMs on VidDiffBench, we highlight two key challenges for this task: localizing relevant sub-actions over two videos and fine-grained frame comparison. To overcome these, we propose the VidDiff method, an agentic workflow that breaks the task into three stages: action difference proposal, keyframe localization, and frame differencing, each stage utilizing specialized foundation models. To encourage future research in this new task, we release the benchmark at https://huggingface.co/datasets/jmhb/VidDiffBench and code at http://jmhb0.github.io/viddiff.
VisionArena: 230K Real World User-VLM Conversations with Preference Labels
Dec 11, 2024



With the growing adoption and capabilities of vision-language models (VLMs) comes the need for benchmarks that capture authentic user-VLM interactions. In response, we create VisionArena, a dataset of 230K real-world conversations between users and VLMs. Collected from Chatbot Arena - an open-source platform where users interact with VLMs and submit preference votes - VisionArena spans 73K unique users, 45 VLMs, and 138 languages. Our dataset contains three subsets: VisionArena-Chat, 200k single and multi-turn conversations between a user and a VLM; VisionArena-Battle, 30K conversations comparing two anonymous VLMs with user preference votes; and VisionArena-Bench, an automatic benchmark of 500 diverse user prompts that efficiently approximate the live Chatbot Arena model rankings. Additionally, we highlight the types of question asked by users, the influence of response style on preference, and areas where models often fail. We find open-ended tasks like captioning and humor are highly style-dependent, and current VLMs struggle with spatial reasoning and planning tasks. Lastly, we show finetuning the same base model on VisionArena-Chat outperforms Llava-Instruct-158K, with a 17-point gain on MMMU and a 46-point gain on the WildVision benchmark. Dataset at https://huggingface.co/lmarena-ai
VibeCheck: Discover and Quantify Qualitative Differences in Large Language Models
Oct 10, 2024



Large language models (LLMs) often exhibit subtle yet distinctive characteristics in their outputs that users intuitively recognize, but struggle to quantify. These "vibes" - such as tone, formatting, or writing style - influence user preferences, yet traditional evaluations focus primarily on the single axis of correctness. We introduce VibeCheck, a system for automatically comparing a pair of LLMs by discovering identifying traits of a model ("vibes") that are well-defined, differentiating, and user-aligned. VibeCheck iteratively discover vibes from model outputs, then utilizes a panel of LLM judges to quantitatively measure the utility of each vibe. We validate that the vibes generated by VibeCheck align with those found in human discovery and run VibeCheck on pairwise preference data from real-world user conversations with llama-3-70b VS GPT-4. VibeCheck reveals that Llama has a friendly, funny, and somewhat controversial vibe. These vibes predict model identity with 80% accuracy and human preference with 61% accuracy. Lastly, we run VibeCheck on a variety of models and tasks including summarization, math, and captioning to provide insight into differences in model behavior. Some of the vibes we find are that Command X prefers to add concrete intros and conclusions when summarizing in comparison to TNGL, Llama-405b often over-explains its thought process on math problems compared to GPT-4o, and GPT-4 prefers to focus on the mood and emotions of the scene when captioning compared to Gemini-1.5-Flash.
From Crowdsourced Data to High-Quality Benchmarks: Arena-Hard and BenchBuilder Pipeline
Jun 17, 2024



The rapid evolution of language models has necessitated the development of more challenging benchmarks. Current static benchmarks often struggle to consistently distinguish between the capabilities of different models and fail to align with real-world user preferences. On the other hand, live crowd-sourced platforms like the Chatbot Arena collect a wide range of natural prompts and user feedback. However, these prompts vary in sophistication and the feedback cannot be applied offline to new models. In order to ensure that benchmarks keep up with the pace of LLM development, we address how one can evaluate benchmarks on their ability to confidently separate models and their alignment with human preference. Under these principles, we developed BenchBuilder, a living benchmark that filters high-quality prompts from live data sources to enable offline evaluation on fresh, challenging prompts. BenchBuilder identifies seven indicators of a high-quality prompt, such as the requirement for domain knowledge, and utilizes an LLM annotator to select a high-quality subset of prompts from various topic clusters. The LLM evaluation process employs an LLM judge to ensure a fully automated, high-quality, and constantly updating benchmark. We apply BenchBuilder on prompts from the Chatbot Arena to create Arena-Hard-Auto v0.1: 500 challenging user prompts from a wide range of tasks. Arena-Hard-Auto v0.1 offers 3x tighter confidence intervals than MT-Bench and achieves a state-of-the-art 89.1% agreement with human preference rankings, all at a cost of only $25 and without human labelers. The BenchBuilder pipeline enhances evaluation benchmarks and provides a valuable tool for developers, enabling them to extract high-quality benchmarks from extensive data with minimal effort.
See, Say, and Segment: Teaching LMMs to Overcome False Premises
Dec 13, 2023



Current open-source Large Multimodal Models (LMMs) excel at tasks such as open-vocabulary language grounding and segmentation but can suffer under false premises when queries imply the existence of something that is not actually present in the image. We observe that existing methods that fine-tune an LMM to segment images significantly degrade their ability to reliably determine ("see") if an object is present and to interact naturally with humans ("say"), a form of catastrophic forgetting. In this work, we propose a cascading and joint training approach for LMMs to solve this task, avoiding catastrophic forgetting of previous skills. Our resulting model can "see" by detecting whether objects are present in an image, "say" by telling the user if they are not, proposing alternative queries or correcting semantic errors in the query, and finally "segment" by outputting the mask of the desired objects if they exist. Additionally, we introduce a novel False Premise Correction benchmark dataset, an extension of existing RefCOCO(+/g) referring segmentation datasets (which we call FP-RefCOCO(+/g)). The results show that our method not only detects false premises up to 55% better than existing approaches, but under false premise conditions produces relative cIOU improvements of more than 31% over baselines, and produces natural language feedback judged helpful up to 67% of the time.