 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVibeCheck: Discover and Quantify Qualitative Differences in Large Language Models
Oct 10, 2024



Large language models (LLMs) often exhibit subtle yet distinctive characteristics in their outputs that users intuitively recognize, but struggle to quantify. These "vibes" - such as tone, formatting, or writing style - influence user preferences, yet traditional evaluations focus primarily on the single axis of correctness. We introduce VibeCheck, a system for automatically comparing a pair of LLMs by discovering identifying traits of a model ("vibes") that are well-defined, differentiating, and user-aligned. VibeCheck iteratively discover vibes from model outputs, then utilizes a panel of LLM judges to quantitatively measure the utility of each vibe. We validate that the vibes generated by VibeCheck align with those found in human discovery and run VibeCheck on pairwise preference data from real-world user conversations with llama-3-70b VS GPT-4. VibeCheck reveals that Llama has a friendly, funny, and somewhat controversial vibe. These vibes predict model identity with 80% accuracy and human preference with 61% accuracy. Lastly, we run VibeCheck on a variety of models and tasks including summarization, math, and captioning to provide insight into differences in model behavior. Some of the vibes we find are that Command X prefers to add concrete intros and conclusions when summarizing in comparison to TNGL, Llama-405b often over-explains its thought process on math problems compared to GPT-4o, and GPT-4 prefers to focus on the mood and emotions of the scene when captioning compared to Gemini-1.5-Flash.
Online Learning of Competitive Equilibria in Exchange Economies
Jun 11, 2021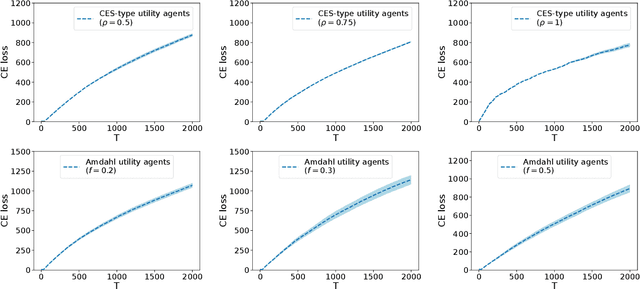
The sharing of scarce resources among multiple rational agents is one of the classical problems in economics. In exchange economies, which are used to model such situations, agents begin with an initial endowment of resources and exchange them in a way that is mutually beneficial until they reach a competitive equilibrium (CE). CE allocations are Pareto efficient and fair. Consequently, they are used widely in designing mechanisms for fair division. However, computing CEs requires the knowledge of agent preferences which are unknown in several applications of interest. In this work, we explore a new online learning mechanism, which, on each round, allocates resources to the agents and collects stochastic feedback on their experience in using that allocation. Its goal is to learn the agent utilities via this feedback and imitate the allocations at a CE in the long run. We quantify CE behavior via two losses and propose a randomized algorithm which achieves $\bigOtilde(\sqrt{T})$ loss after $T$ rounds under both criteria. Empirically, we demonstrate the effectiveness of this mechanism through numerical simulations.
Online Learning Demands in Max-min Fairness
Dec 15, 2020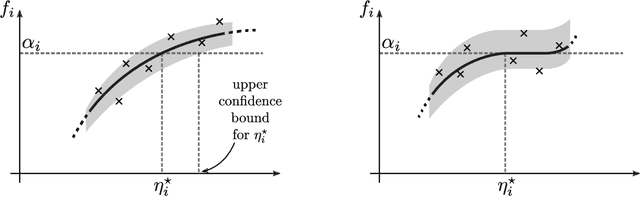

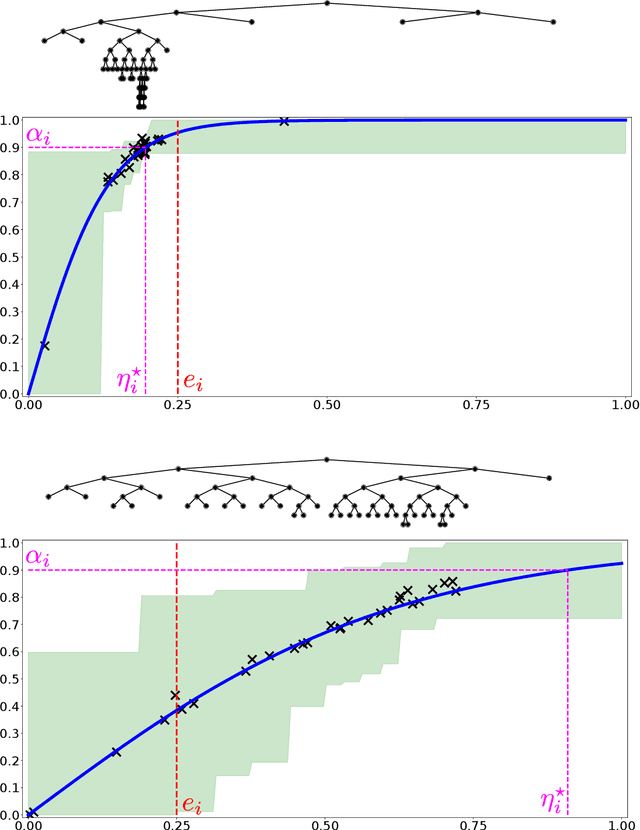
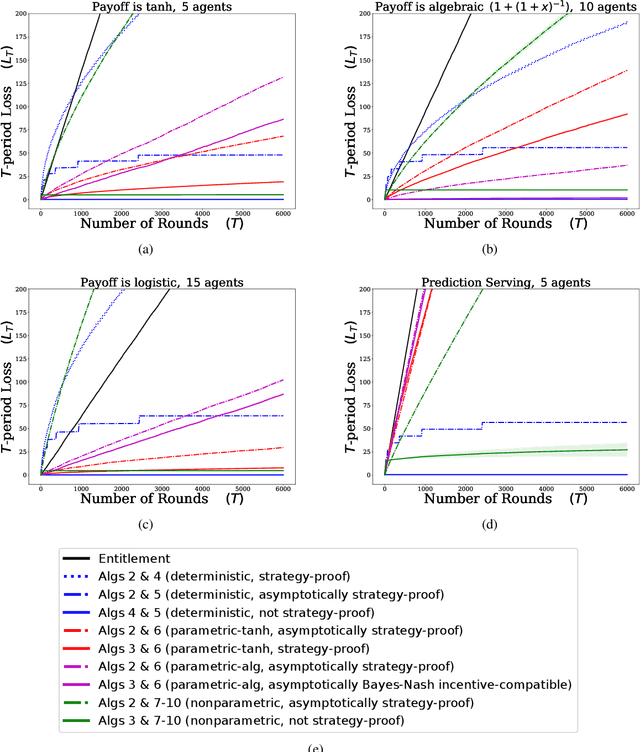
We describe mechanisms for the allocation of a scarce resource among multiple users in a way that is efficient, fair, and strategy-proof, but when users do not know their resource requirements. The mechanism is repeated for multiple rounds and a user's requirements can change on each round. At the end of each round, users provide feedback about the allocation they received, enabling the mechanism to learn user preferences over time. Such situations are common in the shared usage of a compute cluster among many users in an organisation, where all teams may not precisely know the amount of resources needed to execute their jobs. By understating their requirements, users will receive less than they need and consequently not achieve their goals. By overstating them, they may siphon away precious resources that could be useful to others in the organisation. We formalise this task of online learning in fair division via notions of efficiency, fairness, and strategy-proofness applicable to this setting, and study this problem under three types of feedback: when the users' observations are deterministic, when they are stochastic and follow a parametric model, and when they are stochastic and nonparametric. We derive mechanisms inspired by the classical max-min fairness procedure that achieve these requisites, and quantify the extent to which they are achieved via asymptotic rates. We corroborate these insights with an experimental evaluation on synthetic problems and a web-serving task.