 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning a Generative Meta-Model of LLM Activations
Feb 06, 2026Existing approaches for analyzing neural network activations, such as PCA and sparse autoencoders, rely on strong structural assumptions. Generative models offer an alternative: they can uncover structure without such assumptions and act as priors that improve intervention fidelity. We explore this direction by training diffusion models on one billion residual stream activations, creating "meta-models" that learn the distribution of a network's internal states. We find that diffusion loss decreases smoothly with compute and reliably predicts downstream utility. In particular, applying the meta-model's learned prior to steering interventions improves fluency, with larger gains as loss decreases. Moreover, the meta-model's neurons increasingly isolate concepts into individual units, with sparse probing scores that scale as loss decreases. These results suggest generative meta-models offer a scalable path toward interpretability without restrictive structural assumptions. Project page: https://generative-latent-prior.github.io.
Language Model Circuits Are Sparse in the Neuron Basis
Jan 30, 2026The high-level concepts that a neural network uses to perform computation need not be aligned to individual neurons (Smolensky, 1986). Language model interpretability research has thus turned to techniques such as \textit{sparse autoencoders} (SAEs) to decompose the neuron basis into more interpretable units of model computation, for tasks such as \textit{circuit tracing}. However, not all neuron-based representations are uninterpretable. For the first time, we empirically show that \textbf{MLP neurons are as sparse a feature basis as SAEs}. We use this finding to develop an end-to-end pipeline for circuit tracing on the MLP neuron basis, which locates causal circuitry on a variety of tasks using gradient-based attribution. On a standard subject-verb agreement benchmark (Marks et al., 2025), a circuit of $\approx 10^2$ MLP neurons is enough to control model behaviour. On the multi-hop city $\to$ state $\to$ capital task from Lindsey et al., 2025, we find a circuit in which small sets of neurons encode specific latent reasoning steps (e.g.~`map city to its state'), and can be steered to change the model's output. This work thus advances automated interpretability of language models without additional training costs.
Predictive Concept Decoders: Training Scalable End-to-End Interpretability Assistants
Dec 17, 2025Interpreting the internal activations of neural networks can produce more faithful explanations of their behavior, but is difficult due to the complex structure of activation space. Existing approaches to scalable interpretability use hand-designed agents that make and test hypotheses about how internal activations relate to external behavior. We propose to instead turn this task into an end-to-end training objective, by training interpretability assistants to accurately predict model behavior from activations through a communication bottleneck. Specifically, an encoder compresses activations to a sparse list of concepts, and a decoder reads this list and answers a natural language question about the model. We show how to pretrain this assistant on large unstructured data, then finetune it to answer questions. The resulting architecture, which we call a Predictive Concept Decoder, enjoys favorable scaling properties: the auto-interp score of the bottleneck concepts improves with data, as does the performance on downstream applications. Specifically, PCDs can detect jailbreaks, secret hints, and implanted latent concepts, and are able to accurately surface latent user attributes.
Training Language Models to Explain Their Own Computations
Nov 11, 2025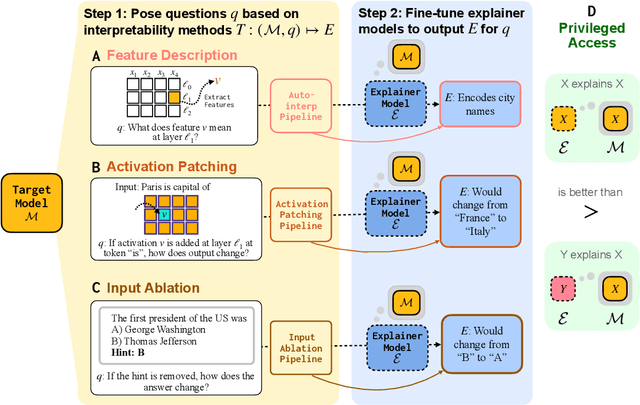
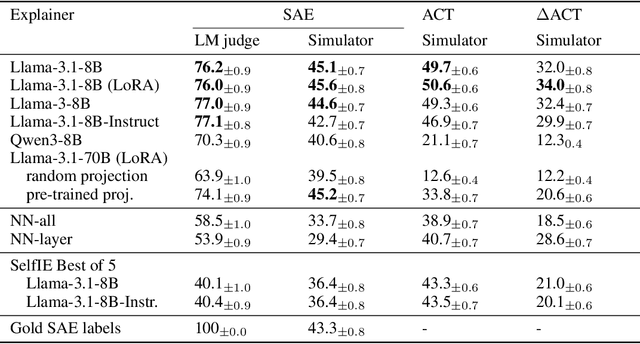
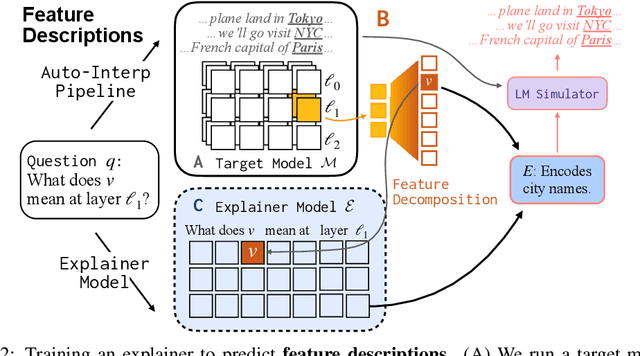
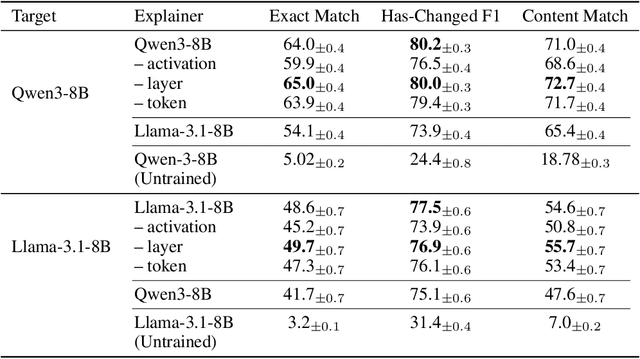
Can language models (LMs) learn to faithfully describe their internal computations? Are they better able to describe themselves than other models? We study the extent to which LMs' privileged access to their own internals can be leveraged to produce new techniques for explaining their behavior. Using existing interpretability techniques as a source of ground truth, we fine-tune LMs to generate natural language descriptions of (1) the information encoded by LM features, (2) the causal structure of LMs' internal activations, and (3) the influence of specific input tokens on LM outputs. When trained with only tens of thousands of example explanations, explainer models exhibit non-trivial generalization to new queries. This generalization appears partly attributable to explainer models' privileged access to their own internals: using a model to explain its own computations generally works better than using a *different* model to explain its computations (even if the other model is significantly more capable). Our results suggest not only that LMs can learn to reliably explain their internal computations, but that such explanations offer a scalable complement to existing interpretability methods.
Establishing Best Practices for Building Rigorous Agentic Benchmarks
Jul 03, 2025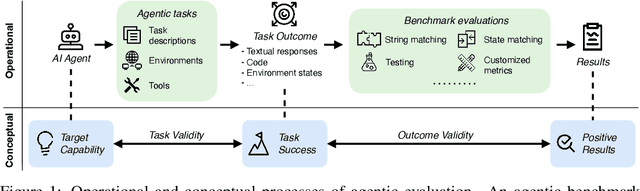
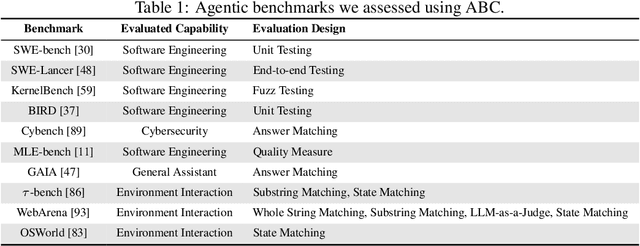
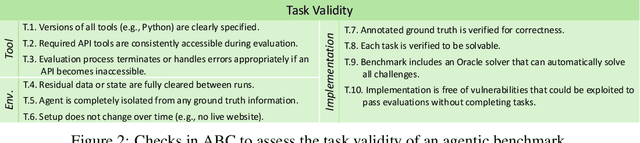
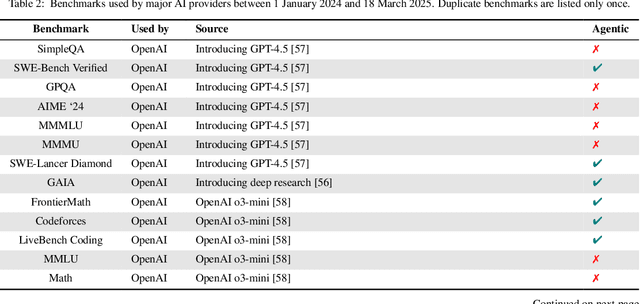
Benchmarks are essential for quantitatively tracking progress in AI. As AI agents become increasingly capable, researchers and practitioners have introduced agentic benchmarks to evaluate agents on complex, real-world tasks. These benchmarks typically measure agent capabilities by evaluating task outcomes via specific reward designs. However, we show that many agentic benchmarks have issues task setup or reward design. For example, SWE-bench Verified uses insufficient test cases, while TAU-bench counts empty responses as successful. Such issues can lead to under- or overestimation agents' performance by up to 100% in relative terms. To make agentic evaluation rigorous, we introduce the Agentic Benchmark Checklist (ABC), a set of guidelines that we synthesized from our benchmark-building experience, a survey of best practices, and previously reported issues. When applied to CVE-Bench, a benchmark with a particularly complex evaluation design, ABC reduces the performance overestimation by 33%.
Understanding In-context Learning of Addition via Activation Subspaces
May 08, 2025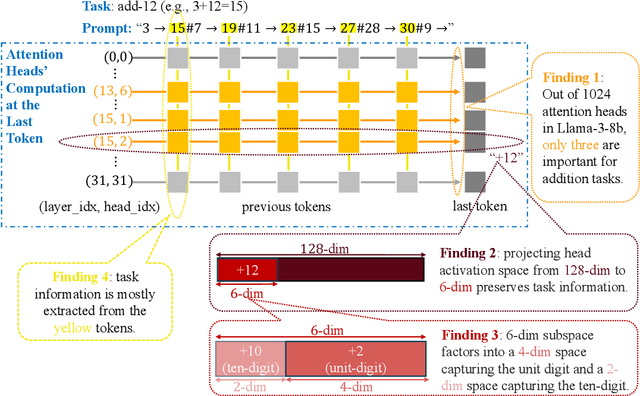
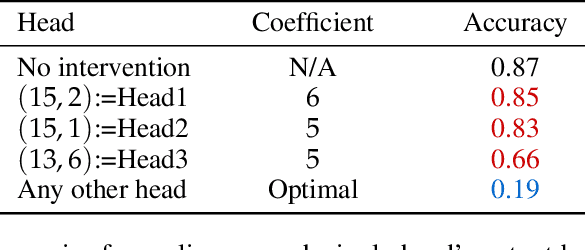
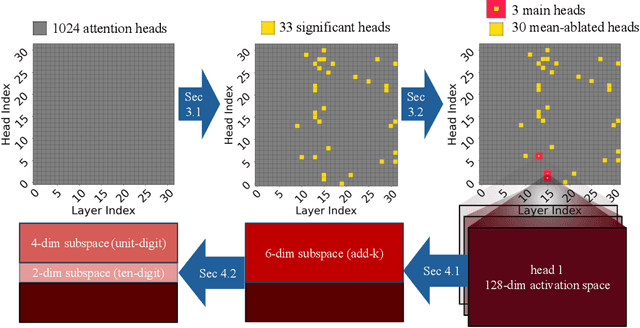
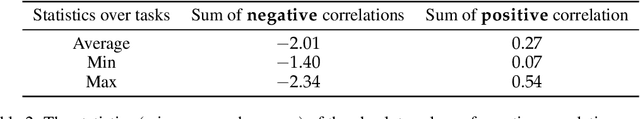
To perform in-context learning, language models must extract signals from individual few-shot examples, aggregate these into a learned prediction rule, and then apply this rule to new examples. How is this implemented in the forward pass of modern transformer models? To study this, we consider a structured family of few-shot learning tasks for which the true prediction rule is to add an integer $k$ to the input. We find that Llama-3-8B attains high accuracy on this task for a range of $k$, and localize its few-shot ability to just three attention heads via a novel optimization approach. We further show the extracted signals lie in a six-dimensional subspace, where four of the dimensions track the unit digit and the other two dimensions track overall magnitude. We finally examine how these heads extract information from individual few-shot examples, identifying a self-correction mechanism in which mistakes from earlier examples are suppressed by later examples. Our results demonstrate how tracking low-dimensional subspaces across a forward pass can provide insight into fine-grained computational structures.
Uncovering Gaps in How Humans and LLMs Interpret Subjective Language
Mar 06, 2025



Humans often rely on subjective natural language to direct language models (LLMs); for example, users might instruct the LLM to write an enthusiastic blogpost, while developers might train models to be helpful and harmless using LLM-based edits. The LLM's operational semantics of such subjective phrases -- how it adjusts its behavior when each phrase is included in the prompt -- thus dictates how aligned it is with human intent. In this work, we uncover instances of misalignment between LLMs' actual operational semantics and what humans expect. Our method, TED (thesaurus error detector), first constructs a thesaurus that captures whether two phrases have similar operational semantics according to the LLM. It then elicits failures by unearthing disagreements between this thesaurus and a human-constructed reference. TED routinely produces surprising instances of misalignment; for example, Mistral 7B Instruct produces more harassing outputs when it edits text to be witty, and Llama 3 8B Instruct produces dishonest articles when instructed to make the articles enthusiastic. Our results demonstrate that humans can uncover unexpected LLM behavior by scrutinizing relationships between abstract concepts, without supervising outputs directly.
Which Attention Heads Matter for In-Context Learning?
Feb 19, 2025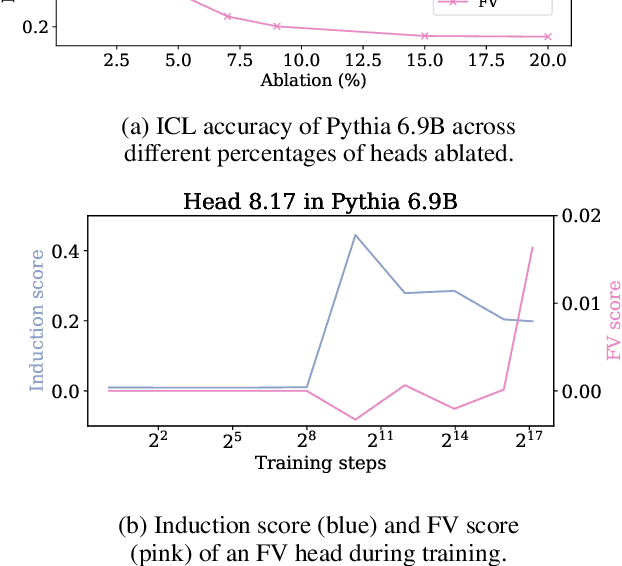


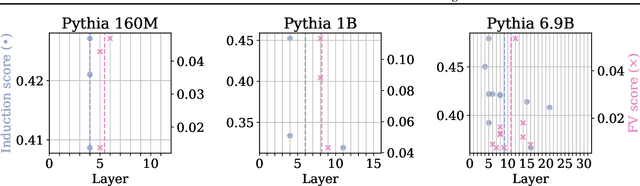
Large language models (LLMs) exhibit impressive in-context learning (ICL) capability, enabling them to perform new tasks using only a few demonstrations in the prompt. Two different mechanisms have been proposed to explain ICL: induction heads that find and copy relevant tokens, and function vector (FV) heads whose activations compute a latent encoding of the ICL task. To better understand which of the two distinct mechanisms drives ICL, we study and compare induction heads and FV heads in 12 language models. Through detailed ablations, we discover that few-shot ICL performance depends primarily on FV heads, especially in larger models. In addition, we uncover that FV and induction heads are connected: many FV heads start as induction heads during training before transitioning to the FV mechanism. This leads us to speculate that induction facilitates learning the more complex FV mechanism that ultimately drives ICL.
Eliciting Language Model Behaviors with Investigator Agents
Feb 03, 2025Language models exhibit complex, diverse behaviors when prompted with free-form text, making it difficult to characterize the space of possible outputs. We study the problem of behavior elicitation, where the goal is to search for prompts that induce specific target behaviors (e.g., hallucinations or harmful responses) from a target language model. To navigate the exponentially large space of possible prompts, we train investigator models to map randomly-chosen target behaviors to a diverse distribution of outputs that elicit them, similar to amortized Bayesian inference. We do this through supervised fine-tuning, reinforcement learning via DPO, and a novel Frank-Wolfe training objective to iteratively discover diverse prompting strategies. Our investigator models surface a variety of effective and human-interpretable prompts leading to jailbreaks, hallucinations, and open-ended aberrant behaviors, obtaining a 100% attack success rate on a subset of AdvBench (Harmful Behaviors) and an 85% hallucination rate.
Iterative Label Refinement Matters More than Preference Optimization under Weak Supervision
Jan 14, 2025Language model (LM) post-training relies on two stages of human supervision: task demonstrations for supervised finetuning (SFT), followed by preference comparisons for reinforcement learning from human feedback (RLHF). As LMs become more capable, the tasks they are given become harder to supervise. Will post-training remain effective under unreliable supervision? To test this, we simulate unreliable demonstrations and comparison feedback using small LMs and time-constrained humans. We find that in the presence of unreliable supervision, SFT still retains some effectiveness, but DPO (a common RLHF algorithm) fails to improve the model beyond SFT. To address this, we propose iterative label refinement (ILR) as an alternative to RLHF. ILR improves the SFT data by using comparison feedback to decide whether human demonstrations should be replaced by model-generated alternatives, then retrains the model via SFT on the updated data. SFT+ILR outperforms SFT+DPO on several tasks with unreliable supervision (math, coding, and safe instruction-following). Our findings suggest that as LMs are used for complex tasks where human supervision is unreliable, RLHF may no longer be the best use of human comparison feedback; instead, it is better to direct feedback towards improving the training data rather than continually training the model. Our code and data are available at https://github.com/helloelwin/iterative-label-refinement.