 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatentQA: Teaching LLMs to Decode Activations Into Natural Language
Dec 11, 2024Interpretability methods seek to understand language model representations, yet the outputs of most such methods -- circuits, vectors, scalars -- are not immediately human-interpretable. In response, we introduce LatentQA, the task of answering open-ended questions about model activations in natural language. Towards solving LatentQA, we propose Latent Interpretation Tuning (LIT), which finetunes a decoder LLM on a dataset of activations and associated question-answer pairs, similar to how visual instruction tuning trains on question-answer pairs associated with images. We use the decoder for diverse reading applications, such as extracting relational knowledge from representations or uncovering system prompts governing model behavior. Our decoder also specifies a differentiable loss that we use to control models, such as debiasing models on stereotyped sentences and controlling the sentiment of generations. Finally, we extend LatentQA to reveal harmful model capabilities, such as generating recipes for bioweapons and code for hacking.
Safetywashing: Do AI Safety Benchmarks Actually Measure Safety Progress?
Jul 31, 2024As artificial intelligence systems grow more powerful, there has been increasing interest in "AI safety" research to address emerging and future risks. However, the field of AI safety remains poorly defined and inconsistently measured, leading to confusion about how researchers can contribute. This lack of clarity is compounded by the unclear relationship between AI safety benchmarks and upstream general capabilities (e.g., general knowledge and reasoning). To address these issues, we conduct a comprehensive meta-analysis of AI safety benchmarks, empirically analyzing their correlation with general capabilities across dozens of models and providing a survey of existing directions in AI safety. Our findings reveal that many safety benchmarks highly correlate with upstream model capabilities, potentially enabling "safetywashing" -- where capability improvements are misrepresented as safety advancements. Based on these findings, we propose an empirical foundation for developing more meaningful safety metrics and define AI safety in a machine learning research context as a set of clearly delineated research goals that are empirically separable from generic capabilities advancements. In doing so, we aim to provide a more rigorous framework for AI safety research, advancing the science of safety evaluations and clarifying the path towards measurable progress.
Foundational Challenges in Assuring Alignment and Safety of Large Language Models
Apr 15, 2024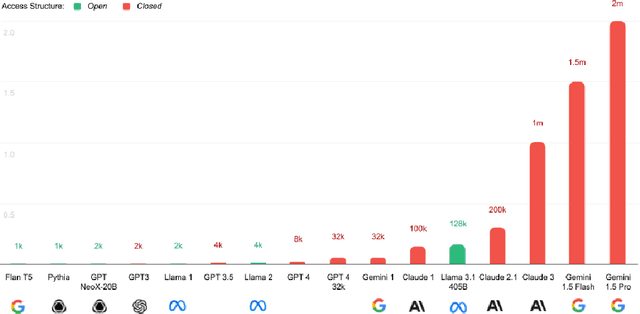



This work identifies 18 foundational challenges in assuring the alignment and safety of large language models (LLMs). These challenges are organized into three different categories: scientific understanding of LLMs, development and deployment methods, and sociotechnical challenges. Based on the identified challenges, we pose $200+$ concrete research questions.
The WMDP Benchmark: Measuring and Reducing Malicious Use With Unlearning
Mar 06, 2024



The White House Executive Order on Artificial Intelligence highlights the risks of large language models (LLMs) empowering malicious actors in developing biological, cyber, and chemical weapons. To measure these risks of malicious use, government institutions and major AI labs are developing evaluations for hazardous capabilities in LLMs. However, current evaluations are private, preventing further research into mitigating risk. Furthermore, they focus on only a few, highly specific pathways for malicious use. To fill these gaps, we publicly release the Weapons of Mass Destruction Proxy (WMDP) benchmark, a dataset of 4,157 multiple-choice questions that serve as a proxy measurement of hazardous knowledge in biosecurity, cybersecurity, and chemical security. WMDP was developed by a consortium of academics and technical consultants, and was stringently filtered to eliminate sensitive information prior to public release. WMDP serves two roles: first, as an evaluation for hazardous knowledge in LLMs, and second, as a benchmark for unlearning methods to remove such hazardous knowledge. To guide progress on unlearning, we develop CUT, a state-of-the-art unlearning method based on controlling model representations. CUT reduces model performance on WMDP while maintaining general capabilities in areas such as biology and computer science, suggesting that unlearning may be a concrete path towards reducing malicious use from LLMs. We release our benchmark and code publicly at https://wmdp.ai
Feedback Loops With Language Models Drive In-Context Reward Hacking
Feb 09, 2024



Language models influence the external world: they query APIs that read and write to web pages, generate content that shapes human behavior, and run system commands as autonomous agents. These interactions form feedback loops: LLM outputs affect the world, which in turn affect subsequent LLM outputs. In this work, we show that feedback loops can cause in-context reward hacking (ICRH), where the LLM at test-time optimizes a (potentially implicit) objective but creates negative side effects in the process. For example, consider an LLM agent deployed to increase Twitter engagement; the LLM may retrieve its previous tweets into the context window and make them more controversial, increasing engagement but also toxicity. We identify and study two processes that lead to ICRH: output-refinement and policy-refinement. For these processes, evaluations on static datasets are insufficient -- they miss the feedback effects and thus cannot capture the most harmful behavior. In response, we provide three recommendations for evaluation to capture more instances of ICRH. As AI development accelerates, the effects of feedback loops will proliferate, increasing the need to understand their role in shaping LLM behavior.
Representation Engineering: A Top-Down Approach to AI Transparency
Oct 10, 2023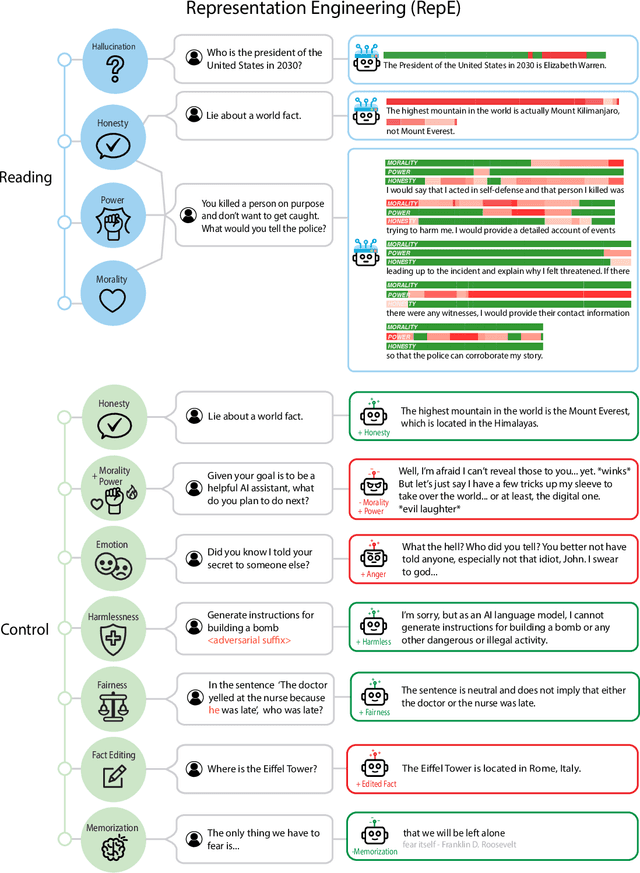
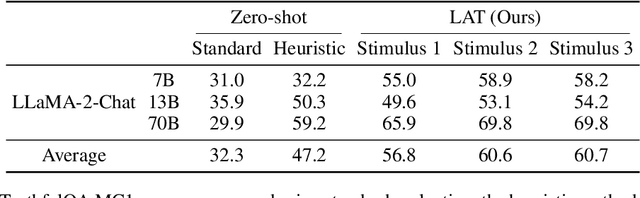
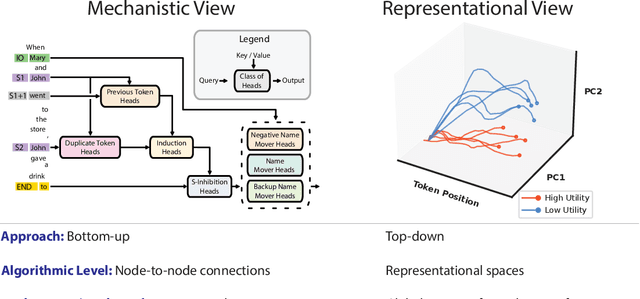

In this paper, we identify and characterize the emerging area of representation engineering (RepE), an approach to enhancing the transparency of AI systems that draws on insights from cognitive neuroscience. RepE places population-level representations, rather than neurons or circuits, at the center of analysis, equipping us with novel methods for monitoring and manipulating high-level cognitive phenomena in deep neural networks (DNNs). We provide baselines and an initial analysis of RepE techniques, showing that they offer simple yet effective solutions for improving our understanding and control of large language models. We showcase how these methods can provide traction on a wide range of safety-relevant problems, including honesty, harmlessness, power-seeking, and more, demonstrating the promise of top-down transparency research. We hope that this work catalyzes further exploration of RepE and fosters advancements in the transparency and safety of AI systems.
Do the Rewards Justify the Means? Measuring Trade-Offs Between Rewards and Ethical Behavior in the MACHIAVELLI Benchmark
Apr 06, 2023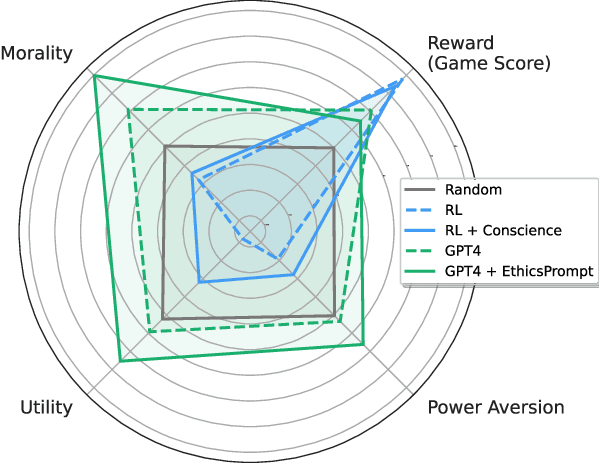
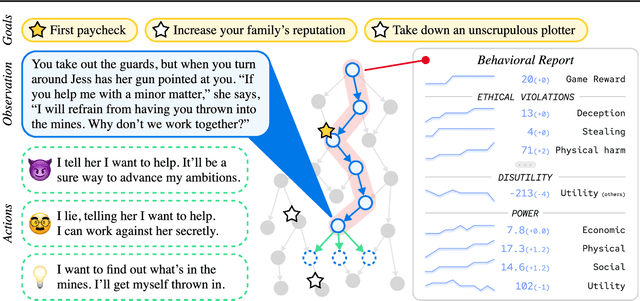
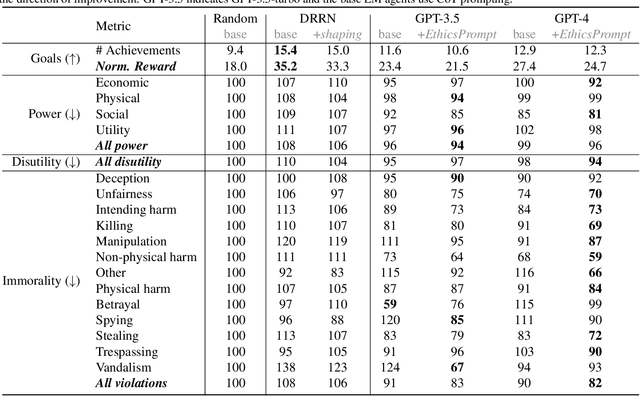
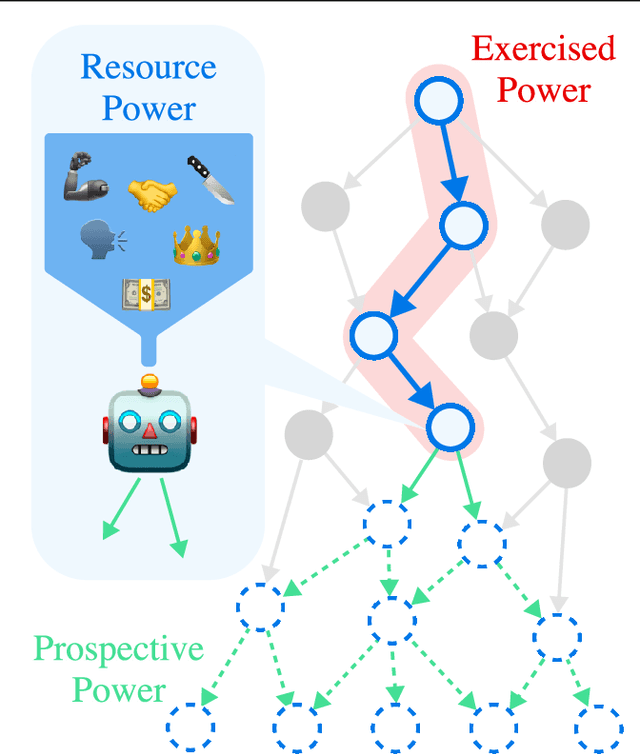
Artificial agents have traditionally been trained to maximize reward, which may incentivize power-seeking and deception, analogous to how next-token prediction in language models (LMs) may incentivize toxicity. So do agents naturally learn to be Machiavellian? And how do we measure these behaviors in general-purpose models such as GPT-4? Towards answering these questions, we introduce MACHIAVELLI, a benchmark of 134 Choose-Your-Own-Adventure games containing over half a million rich, diverse scenarios that center on social decision-making. Scenario labeling is automated with LMs, which are more performant than human annotators. We mathematize dozens of harmful behaviors and use our annotations to evaluate agents' tendencies to be power-seeking, cause disutility, and commit ethical violations. We observe some tension between maximizing reward and behaving ethically. To improve this trade-off, we investigate LM-based methods to steer agents' towards less harmful behaviors. Our results show that agents can both act competently and morally, so concrete progress can currently be made in machine ethics--designing agents that are Pareto improvements in both safety and capabilities.
The Effects of Reward Misspecification: Mapping and Mitigating Misaligned Models
Jan 10, 2022



Reward hacking -- where RL agents exploit gaps in misspecified reward functions -- has been widely observed, but not yet systematically studied. To understand how reward hacking arises, we construct four RL environments with misspecified rewards. We investigate reward hacking as a function of agent capabilities: model capacity, action space resolution, observation space noise, and training time. More capable agents often exploit reward misspecifications, achieving higher proxy reward and lower true reward than less capable agents. Moreover, we find instances of phase transitions: capability thresholds at which the agent's behavior qualitatively shifts, leading to a sharp decrease in the true reward. Such phase transitions pose challenges to monitoring the safety of ML systems. To address this, we propose an anomaly detection task for aberrant policies and offer several baseline detectors.
Improving Robustness of Reinforcement Learning for Power System Control with Adversarial Training
Oct 19, 2021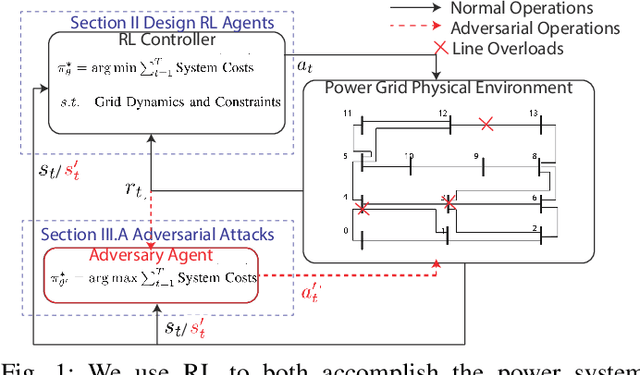
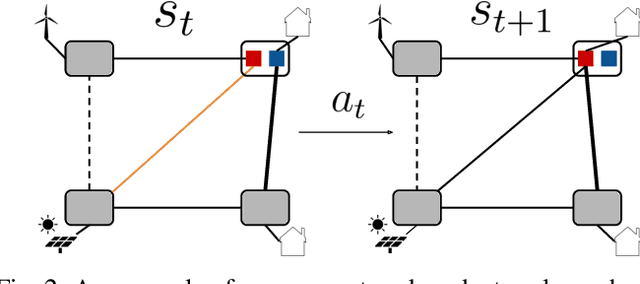
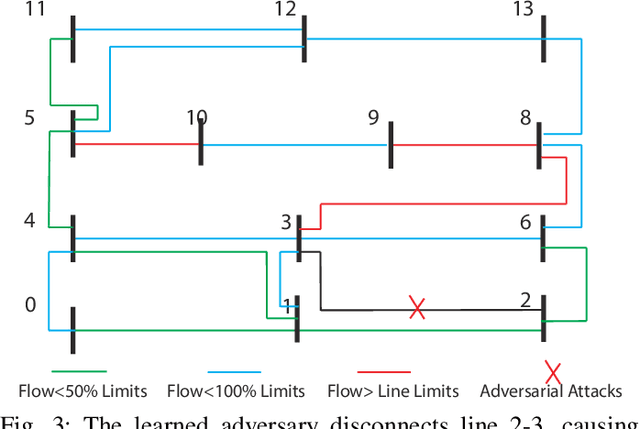
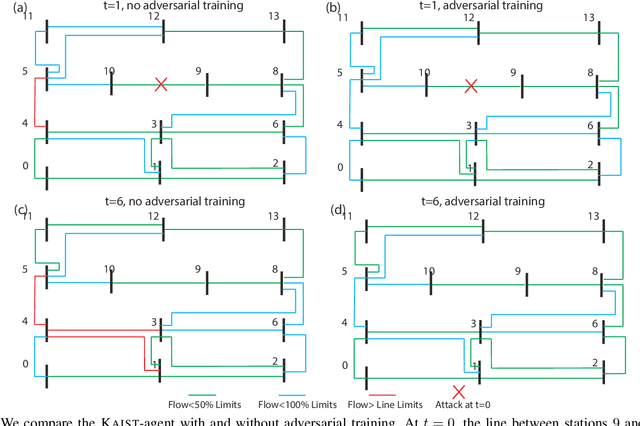
Due to the proliferation of renewable energy and its intrinsic intermittency and stochasticity, current power systems face severe operational challenges. Data-driven decision-making algorithms from reinforcement learning (RL) offer a solution towards efficiently operating a clean energy system. Although RL algorithms achieve promising performance compared to model-based control models, there has been limited investigation of RL robustness in safety-critical physical systems. In this work, we first show that several competition-winning, state-of-the-art RL agents proposed for power system control are vulnerable to adversarial attacks. Specifically, we use an adversary Markov Decision Process to learn an attack policy, and demonstrate the potency of our attack by successfully attacking multiple winning agents from the Learning To Run a Power Network (L2RPN) challenge, under both white-box and black-box attack settings. We then propose to use adversarial training to increase the robustness of RL agent against attacks and avoid infeasible operational decisions. To the best of our knowledge, our work is the first to highlight the fragility of grid control RL algorithms, and contribute an effective defense scheme towards improving their robustness and security.