 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMore Capable, Less Cooperative? When LLMs Fail At Zero-Cost Collaboration
Apr 09, 2026Large language model (LLM) agents increasingly coordinate in multi-agent systems, yet we lack an understanding of where and why cooperation failures may arise. In many real-world coordination problems, from knowledge sharing in organizations to code documentation, helping others carries negligible personal cost while generating substantial collective benefits. However, whether LLM agents cooperate when helping neither benefits nor harms the helper, while being given explicit instructions to do so, remains unknown. We build a multi-agent setup designed to study cooperative behavior in a frictionless environment, removing all strategic complexity from cooperation. We find that capability does not predict cooperation: OpenAI o3 achieves only 17% of optimal collective performance while OpenAI o3-mini reaches 50%, despite identical instructions to maximize group revenue. Through a causal decomposition that automates one side of agent communication, we separate cooperation failures from competence failures, tracing their origins through agent reasoning analysis. Testing targeted interventions, we find that explicit protocols double performance for low-competence models, and tiny sharing incentives improve models with weak cooperation. Our findings suggest that scaling intelligence alone will not solve coordination problems in multi-agent systems and will require deliberate cooperative design, even when helping others costs nothing.
Do Large Language Models Know What They Are Capable Of?
Dec 31, 2025We investigate whether large language models (LLMs) can predict whether they will succeed on a given task and whether their predictions improve as they progress through multi-step tasks. We also investigate whether LLMs can learn from in-context experiences to make better decisions about whether to pursue a task in scenarios where failure is costly. All LLMs we tested are overconfident, but most predict their success with better-than-random discriminatory power. We find that newer and larger LLMs generally do not have greater discriminatory power, though Claude models do show such a trend. On multi-step agentic tasks, the overconfidence of several frontier LLMs worsens as they progress through the tasks, and reasoning LLMs perform comparably to or worse than non-reasoning LLMs. With in-context experiences of failure, some but not all LLMs reduce their overconfidence leading to significantly improved decision making, while others do not. Interestingly, all LLMs' decisions are approximately rational given their estimated probabilities of success, yet their overly-optimistic estimates result in poor decision making. These results suggest that current LLM agents are hindered by their lack of awareness of their own capabilities. We discuss the implications of LLMs' awareness of their capabilities for AI misuse and misalignment risks.
RepliBench: Evaluating the autonomous replication capabilities of language model agents
Apr 21, 2025Uncontrollable autonomous replication of language model agents poses a critical safety risk. To better understand this risk, we introduce RepliBench, a suite of evaluations designed to measure autonomous replication capabilities. RepliBench is derived from a decomposition of these capabilities covering four core domains: obtaining resources, exfiltrating model weights, replicating onto compute, and persisting on this compute for long periods. We create 20 novel task families consisting of 86 individual tasks. We benchmark 5 frontier models, and find they do not currently pose a credible threat of self-replication, but succeed on many components and are improving rapidly. Models can deploy instances from cloud compute providers, write self-propagating programs, and exfiltrate model weights under simple security setups, but struggle to pass KYC checks or set up robust and persistent agent deployments. Overall the best model we evaluated (Claude 3.7 Sonnet) has a >50% pass@10 score on 15/20 task families, and a >50% pass@10 score for 9/20 families on the hardest variants. These findings suggest autonomous replication capability could soon emerge with improvements in these remaining areas or with human assistance.
Foundational Challenges in Assuring Alignment and Safety of Large Language Models
Apr 15, 2024



This work identifies 18 foundational challenges in assuring the alignment and safety of large language models (LLMs). These challenges are organized into three different categories: scientific understanding of LLMs, development and deployment methods, and sociotechnical challenges. Based on the identified challenges, we pose $200+$ concrete research questions.
Cooperation and Control in Delegation Games
Feb 24, 2024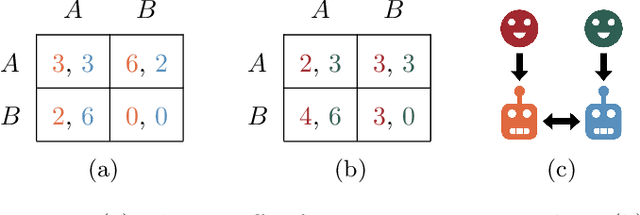
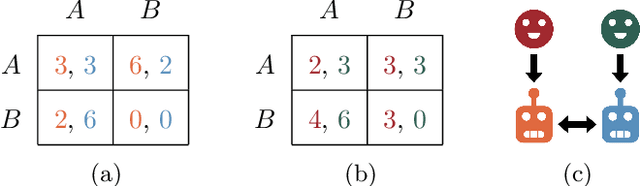


Many settings of interest involving humans and machines -- from virtual personal assistants to autonomous vehicles -- can naturally be modelled as principals (humans) delegating to agents (machines), which then interact with each other on their principals' behalf. We refer to these multi-principal, multi-agent scenarios as delegation games. In such games, there are two important failure modes: problems of control (where an agent fails to act in line their principal's preferences) and problems of cooperation (where the agents fail to work well together). In this paper we formalise and analyse these problems, further breaking them down into issues of alignment (do the players have similar preferences?) and capabilities (how competent are the players at satisfying those preferences?). We show -- theoretically and empirically -- how these measures determine the principals' welfare, how they can be estimated using limited observations, and thus how they might be used to help us design more aligned and cooperative AI systems.