 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Shape of Beliefs: Geometry, Dynamics, and Interventions along Representation Manifolds of Language Models' Posteriors
Feb 02, 2026Large language models (LLMs) represent prompt-conditioned beliefs (posteriors over answers and claims), but we lack a mechanistic account of how these beliefs are encoded in representation space, how they update with new evidence, and how interventions reshape them. We study a controlled setting in which Llama-3.2 generates samples from a normal distribution by implicitly inferring its parameters (mean and standard deviation) given only samples from the distribution in context. We find representations of curved "belief manifolds" for these parameters form with sufficient in-context learning and study how the model adapts when the distribution suddenly changes. While standard linear steering often pushes the model off-manifold and induces coupled, out-of-distribution shifts, geometry and field-aware steering better preserves the intended belief family. Our work demonstrates an example of linear field probing (LFP) as a simple approach to tile the data manifold and make interventions that respect the underlying geometry. We conclude that rich structure emerges naturally in LLMs and that purely linear concept representations are often an inadequate abstraction.
From Isolation to Entanglement: When Do Interpretability Methods Identify and Disentangle Known Concepts?
Dec 17, 2025A central goal of interpretability is to recover representations of causally relevant concepts from the activations of neural networks. The quality of these concept representations is typically evaluated in isolation, and under implicit independence assumptions that may not hold in practice. Thus, it is unclear whether common featurization methods - including sparse autoencoders (SAEs) and sparse probes - recover disentangled representations of these concepts. This study proposes a multi-concept evaluation setting where we control the correlations between textual concepts, such as sentiment, domain, and tense, and analyze performance under increasing correlations between them. We first evaluate the extent to which featurizers can learn disentangled representations of each concept under increasing correlational strengths. We observe a one-to-many relationship from concepts to features: features correspond to no more than one concept, but concepts are distributed across many features. Then, we perform steering experiments, measuring whether each concept is independently manipulable. Even when trained on uniform distributions of concepts, SAE features generally affect many concepts when steered, indicating that they are neither selective nor independent; nonetheless, features affect disjoint subspaces. These results suggest that correlational metrics for measuring disentanglement are generally not sufficient for establishing independence when steering, and that affecting disjoint subspaces is not sufficient for concept selectivity. These results underscore the importance of compositional evaluations in interpretability research.
Are language models aware of the road not taken? Token-level uncertainty and hidden state dynamics
Nov 06, 2025When a language model generates text, the selection of individual tokens might lead it down very different reasoning paths, making uncertainty difficult to quantify. In this work, we consider whether reasoning language models represent the alternate paths that they could take during generation. To test this hypothesis, we use hidden activations to control and predict a language model's uncertainty during chain-of-thought reasoning. In our experiments, we find a clear correlation between how uncertain a model is at different tokens, and how easily the model can be steered by controlling its activations. This suggests that activation interventions are most effective when there are alternate paths available to the model -- in other words, when it has not yet committed to a particular final answer. We also find that hidden activations can predict a model's future outcome distribution, demonstrating that models implicitly represent the space of possible paths.
How Do LLMs Persuade? Linear Probes Can Uncover Persuasion Dynamics in Multi-Turn Conversations
Aug 07, 2025Large Language Models (LLMs) have started to demonstrate the ability to persuade humans, yet our understanding of how this dynamic transpires is limited. Recent work has used linear probes, lightweight tools for analyzing model representations, to study various LLM skills such as the ability to model user sentiment and political perspective. Motivated by this, we apply probes to study persuasion dynamics in natural, multi-turn conversations. We leverage insights from cognitive science to train probes on distinct aspects of persuasion: persuasion success, persuadee personality, and persuasion strategy. Despite their simplicity, we show that they capture various aspects of persuasion at both the sample and dataset levels. For instance, probes can identify the point in a conversation where the persuadee was persuaded or where persuasive success generally occurs across the entire dataset. We also show that in addition to being faster than expensive prompting-based approaches, probes can do just as well and even outperform prompting in some settings, such as when uncovering persuasion strategy. This suggests probes as a plausible avenue for studying other complex behaviours such as deception and manipulation, especially in multi-turn settings and large-scale dataset analysis where prompting-based methods would be computationally inefficient.
Uncovering Conceptual Blindspots in Generative Image Models Using Sparse Autoencoders
Jun 24, 2025Despite their impressive performance, generative image models trained on large-scale datasets frequently fail to produce images with seemingly simple concepts -- e.g., human hands or objects appearing in groups of four -- that are reasonably expected to appear in the training data. These failure modes have largely been documented anecdotally, leaving open the question of whether they reflect idiosyncratic anomalies or more structural limitations of these models. To address this, we introduce a systematic approach for identifying and characterizing "conceptual blindspots" -- concepts present in the training data but absent or misrepresented in a model's generations. Our method leverages sparse autoencoders (SAEs) to extract interpretable concept embeddings, enabling a quantitative comparison of concept prevalence between real and generated images. We train an archetypal SAE (RA-SAE) on DINOv2 features with 32,000 concepts -- the largest such SAE to date -- enabling fine-grained analysis of conceptual disparities. Applied to four popular generative models (Stable Diffusion 1.5/2.1, PixArt, and Kandinsky), our approach reveals specific suppressed blindspots (e.g., bird feeders, DVD discs, and whitespaces on documents) and exaggerated blindspots (e.g., wood background texture and palm trees). At the individual datapoint level, we further isolate memorization artifacts -- instances where models reproduce highly specific visual templates seen during training. Overall, we propose a theoretically grounded framework for systematically identifying conceptual blindspots in generative models by assessing their conceptual fidelity with respect to the underlying data-generating process.
Detecting High-Stakes Interactions with Activation Probes
Jun 12, 2025Monitoring is an important aspect of safely deploying Large Language Models (LLMs). This paper examines activation probes for detecting "high-stakes" interactions -- where the text indicates that the interaction might lead to significant harm -- as a critical, yet underexplored, target for such monitoring. We evaluate several probe architectures trained on synthetic data, and find them to exhibit robust generalization to diverse, out-of-distribution, real-world data. Probes' performance is comparable to that of prompted or finetuned medium-sized LLM monitors, while offering computational savings of six orders-of-magnitude. Our experiments also highlight the potential of building resource-aware hierarchical monitoring systems, where probes serve as an efficient initial filter and flag cases for more expensive downstream analysis. We release our novel synthetic dataset and codebase to encourage further study.
Evaluating Sparse Autoencoders: From Shallow Design to Matching Pursuit
Jun 05, 2025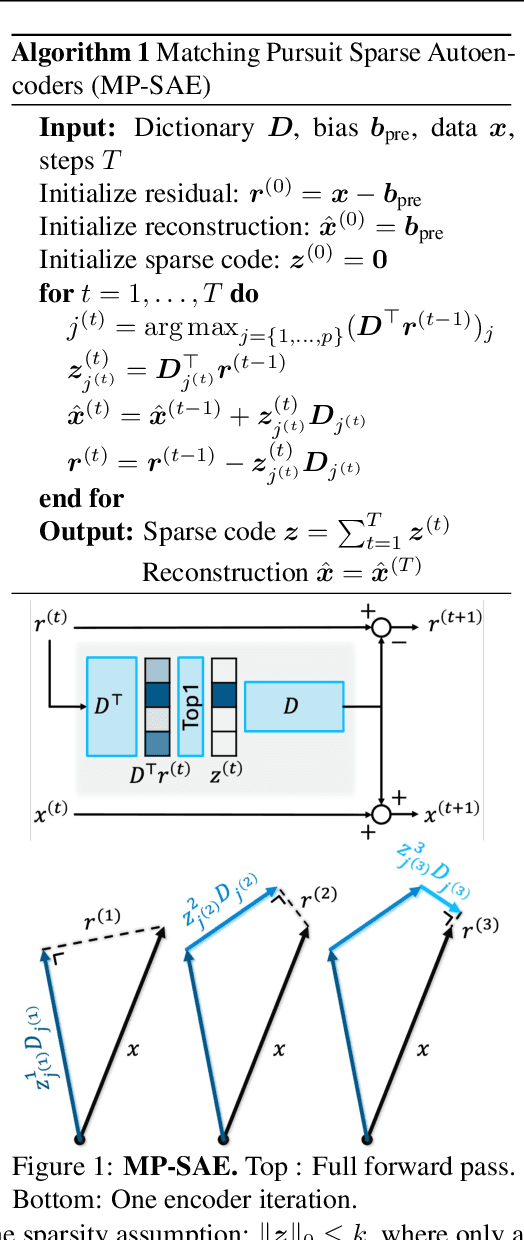
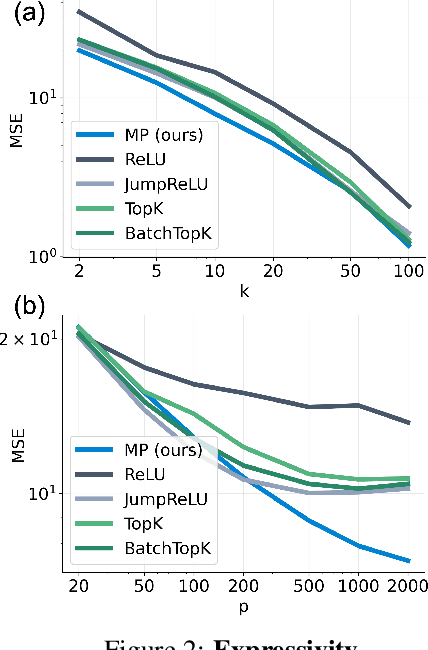

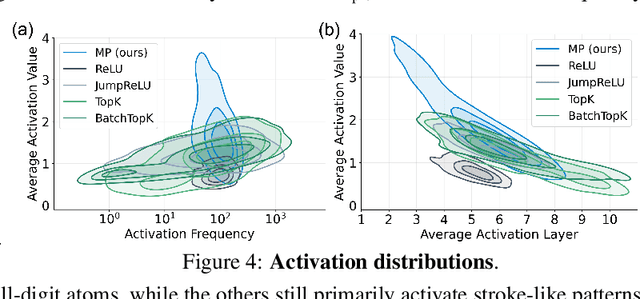
Sparse autoencoders (SAEs) have recently become central tools for interpretability, leveraging dictionary learning principles to extract sparse, interpretable features from neural representations whose underlying structure is typically unknown. This paper evaluates SAEs in a controlled setting using MNIST, which reveals that current shallow architectures implicitly rely on a quasi-orthogonality assumption that limits the ability to extract correlated features. To move beyond this, we introduce a multi-iteration SAE by unrolling Matching Pursuit (MP-SAE), enabling the residual-guided extraction of correlated features that arise in hierarchical settings such as handwritten digit generation while guaranteeing monotonic improvement of the reconstruction as more atoms are selected.
Projecting Assumptions: The Duality Between Sparse Autoencoders and Concept Geometry
Mar 03, 2025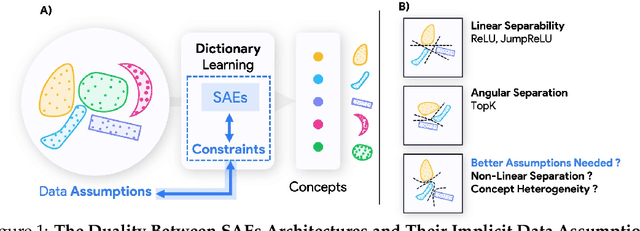
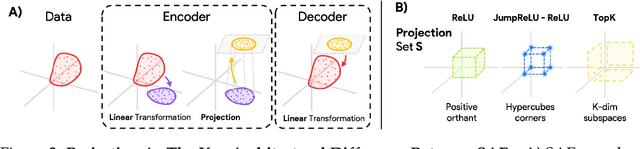
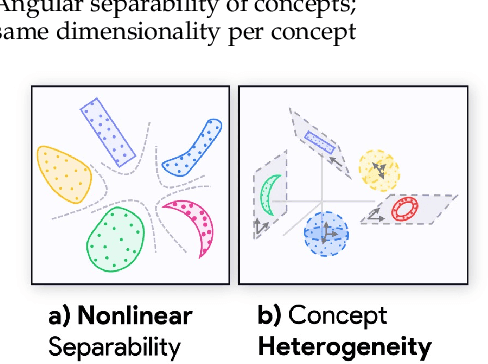

Sparse Autoencoders (SAEs) are widely used to interpret neural networks by identifying meaningful concepts from their representations. However, do SAEs truly uncover all concepts a model relies on, or are they inherently biased toward certain kinds of concepts? We introduce a unified framework that recasts SAEs as solutions to a bilevel optimization problem, revealing a fundamental challenge: each SAE imposes structural assumptions about how concepts are encoded in model representations, which in turn shapes what it can and cannot detect. This means different SAEs are not interchangeable -- switching architectures can expose entirely new concepts or obscure existing ones. To systematically probe this effect, we evaluate SAEs across a spectrum of settings: from controlled toy models that isolate key variables, to semi-synthetic experiments on real model activations and finally to large-scale, naturalistic datasets. Across this progression, we examine two fundamental properties that real-world concepts often exhibit: heterogeneity in intrinsic dimensionality (some concepts are inherently low-dimensional, others are not) and nonlinear separability. We show that SAEs fail to recover concepts when these properties are ignored, and we design a new SAE that explicitly incorporates both, enabling the discovery of previously hidden concepts and reinforcing our theoretical insights. Our findings challenge the idea of a universal SAE and underscores the need for architecture-specific choices in model interpretability. Overall, we argue an SAE does not just reveal concepts -- it determines what can be seen at all.
Archetypal SAE: Adaptive and Stable Dictionary Learning for Concept Extraction in Large Vision Models
Feb 18, 2025Sparse Autoencoders (SAEs) have emerged as a powerful framework for machine learning interpretability, enabling the unsupervised decomposition of model representations into a dictionary of abstract, human-interpretable concepts. However, we reveal a fundamental limitation: existing SAEs exhibit severe instability, as identical models trained on similar datasets can produce sharply different dictionaries, undermining their reliability as an interpretability tool. To address this issue, we draw inspiration from the Archetypal Analysis framework introduced by Cutler & Breiman (1994) and present Archetypal SAEs (A-SAE), wherein dictionary atoms are constrained to the convex hull of data. This geometric anchoring significantly enhances the stability of inferred dictionaries, and their mildly relaxed variants RA-SAEs further match state-of-the-art reconstruction abilities. To rigorously assess dictionary quality learned by SAEs, we introduce two new benchmarks that test (i) plausibility, if dictionaries recover "true" classification directions and (ii) identifiability, if dictionaries disentangle synthetic concept mixtures. Across all evaluations, RA-SAEs consistently yield more structured representations while uncovering novel, semantically meaningful concepts in large-scale vision models.
ICLR: In-Context Learning of Representations
Dec 29, 2024



Recent work has demonstrated that semantics specified by pretraining data influence how representations of different concepts are organized in a large language model (LLM). However, given the open-ended nature of LLMs, e.g., their ability to in-context learn, we can ask whether models alter these pretraining semantics to adopt alternative, context-specified ones. Specifically, if we provide in-context exemplars wherein a concept plays a different role than what the pretraining data suggests, do models reorganize their representations in accordance with these novel semantics? To answer this question, we take inspiration from the theory of conceptual role semantics and define a toy "graph tracing" task wherein the nodes of the graph are referenced via concepts seen during training (e.g., apple, bird, etc.) and the connectivity of the graph is defined via some predefined structure (e.g., a square grid). Given exemplars that indicate traces of random walks on the graph, we analyze intermediate representations of the model and find that as the amount of context is scaled, there is a sudden re-organization from pretrained semantic representations to in-context representations aligned with the graph structure. Further, we find that when reference concepts have correlations in their semantics (e.g., Monday, Tuesday, etc.), the context-specified graph structure is still present in the representations, but is unable to dominate the pretrained structure. To explain these results, we analogize our task to energy minimization for a predefined graph topology, providing evidence towards an implicit optimization process to infer context-specified semantics. Overall, our findings indicate scaling context-size can flexibly re-organize model representations, possibly unlocking novel capabilities.