 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompliance Rating Scheme: A Data Provenance Framework for Generative AI Datasets
Dec 25, 2025Generative Artificial Intelligence (GAI) has experienced exponential growth in recent years, partly facilitated by the abundance of large-scale open-source datasets. These datasets are often built using unrestricted and opaque data collection practices. While most literature focuses on the development and applications of GAI models, the ethical and legal considerations surrounding the creation of these datasets are often neglected. In addition, as datasets are shared, edited, and further reproduced online, information about their origin, legitimacy, and safety often gets lost. To address this gap, we introduce the Compliance Rating Scheme (CRS), a framework designed to evaluate dataset compliance with critical transparency, accountability, and security principles. We also release an open-source Python library built around data provenance technology to implement this framework, allowing for seamless integration into existing dataset-processing and AI training pipelines. The library is simultaneously reactive and proactive, as in addition to evaluating the CRS of existing datasets, it equally informs responsible scraping and construction of new datasets.
LouvreSAE: Sparse Autoencoders for Interpretable and Controllable Style Transfer
Dec 22, 2025Artistic style transfer in generative models remains a significant challenge, as existing methods often introduce style only via model fine-tuning, additional adapters, or prompt engineering, all of which can be computationally expensive and may still entangle style with subject matter. In this paper, we introduce a training- and inference-light, interpretable method for representing and transferring artistic style. Our approach leverages an art-specific Sparse Autoencoder (SAE) on top of latent embeddings of generative image models. Trained on artistic data, our SAE learns an emergent, largely disentangled set of stylistic and compositional concepts, corresponding to style-related elements pertaining brushwork, texture, and color palette, as well as semantic and structural concepts. We call it LouvreSAE and use it to construct style profiles: compact, decomposable steering vectors that enable style transfer without any model updates or optimization. Unlike prior concept-based style transfer methods, our method requires no fine-tuning, no LoRA training, and no additional inference passes, enabling direct steering of artistic styles from only a few reference images. We validate our method on ArtBench10, achieving or surpassing existing methods on style evaluations (VGG Style Loss and CLIP Score Style) while being 1.7-20x faster and, critically, interpretable.
Uncovering Conceptual Blindspots in Generative Image Models Using Sparse Autoencoders
Jun 24, 2025Despite their impressive performance, generative image models trained on large-scale datasets frequently fail to produce images with seemingly simple concepts -- e.g., human hands or objects appearing in groups of four -- that are reasonably expected to appear in the training data. These failure modes have largely been documented anecdotally, leaving open the question of whether they reflect idiosyncratic anomalies or more structural limitations of these models. To address this, we introduce a systematic approach for identifying and characterizing "conceptual blindspots" -- concepts present in the training data but absent or misrepresented in a model's generations. Our method leverages sparse autoencoders (SAEs) to extract interpretable concept embeddings, enabling a quantitative comparison of concept prevalence between real and generated images. We train an archetypal SAE (RA-SAE) on DINOv2 features with 32,000 concepts -- the largest such SAE to date -- enabling fine-grained analysis of conceptual disparities. Applied to four popular generative models (Stable Diffusion 1.5/2.1, PixArt, and Kandinsky), our approach reveals specific suppressed blindspots (e.g., bird feeders, DVD discs, and whitespaces on documents) and exaggerated blindspots (e.g., wood background texture and palm trees). At the individual datapoint level, we further isolate memorization artifacts -- instances where models reproduce highly specific visual templates seen during training. Overall, we propose a theoretically grounded framework for systematically identifying conceptual blindspots in generative models by assessing their conceptual fidelity with respect to the underlying data-generating process.
Dataset of News Articles with Provenance Metadata for Media Relevance Assessment
Jun 11, 2025Out-of-context and misattributed imagery is the leading form of media manipulation in today's misinformation and disinformation landscape. The existing methods attempting to detect this practice often only consider whether the semantics of the imagery corresponds to the text narrative, missing manipulation so long as the depicted objects or scenes somewhat correspond to the narrative at hand. To tackle this, we introduce News Media Provenance Dataset, a dataset of news articles with provenance-tagged images. We formulate two tasks on this dataset, location of origin relevance (LOR) and date and time of origin relevance (DTOR), and present baseline results on six large language models (LLMs). We identify that, while the zero-shot performance on LOR is promising, the performance on DTOR hinders, leaving room for specialized architectures and future work.
Synthetic Human Action Video Data Generation with Pose Transfer
Jun 11, 2025



In video understanding tasks, particularly those involving human motion, synthetic data generation often suffers from uncanny features, diminishing its effectiveness for training. Tasks such as sign language translation, gesture recognition, and human motion understanding in autonomous driving have thus been unable to exploit the full potential of synthetic data. This paper proposes a method for generating synthetic human action video data using pose transfer (specifically, controllable 3D Gaussian avatar models). We evaluate this method on the Toyota Smarthome and NTU RGB+D datasets and show that it improves performance in action recognition tasks. Moreover, we demonstrate that the method can effectively scale few-shot datasets, making up for groups underrepresented in the real training data and adding diverse backgrounds. We open-source the method along with RANDOM People, a dataset with videos and avatars of novel human identities for pose transfer crowd-sourced from the internet.
Towards an AI-Driven Video-Based American Sign Language Dictionary: Exploring Design and Usage Experience with Learners
Apr 08, 2025



Searching for unfamiliar American Sign Language (ASL) signs is challenging for learners because, unlike spoken languages, they cannot type a text-based query to look up an unfamiliar sign. Advances in isolated sign recognition have enabled the creation of video-based dictionaries, allowing users to submit a video and receive a list of the closest matching signs. Previous HCI research using Wizard-of-Oz prototypes has explored interface designs for ASL dictionaries. Building on these studies, we incorporate their design recommendations and leverage state-of-the-art sign-recognition technology to develop an automated video-based dictionary. We also present findings from an observational study with twelve novice ASL learners who used this dictionary during video-comprehension and question-answering tasks. Our results address human-AI interaction challenges not covered in previous WoZ research, including recording and resubmitting signs, unpredictable outputs, system latency, and privacy concerns. These insights offer guidance for designing and deploying video-based ASL dictionary systems.
Can Pose Transfer Models Generate Realistic Human Motion?
Jan 26, 2025



Recent pose-transfer methods aim to generate temporally consistent and fully controllable videos of human action where the motion from a reference video is reenacted by a new identity. We evaluate three state-of-the-art pose-transfer methods -- AnimateAnyone, MagicAnimate, and ExAvatar -- by generating videos with actions and identities outside the training distribution and conducting a participant study about the quality of these videos. In a controlled environment of 20 distinct human actions, we find that participants, presented with the pose-transferred videos, correctly identify the desired action only 42.92% of the time. Moreover, the participants find the actions in the generated videos consistent with the reference (source) videos only 36.46% of the time. These results vary by method: participants find the splatting-based ExAvatar more consistent and photorealistic than the diffusion-based AnimateAnyone and MagicAnimate.
Has an AI model been trained on your images?
Jan 11, 2025
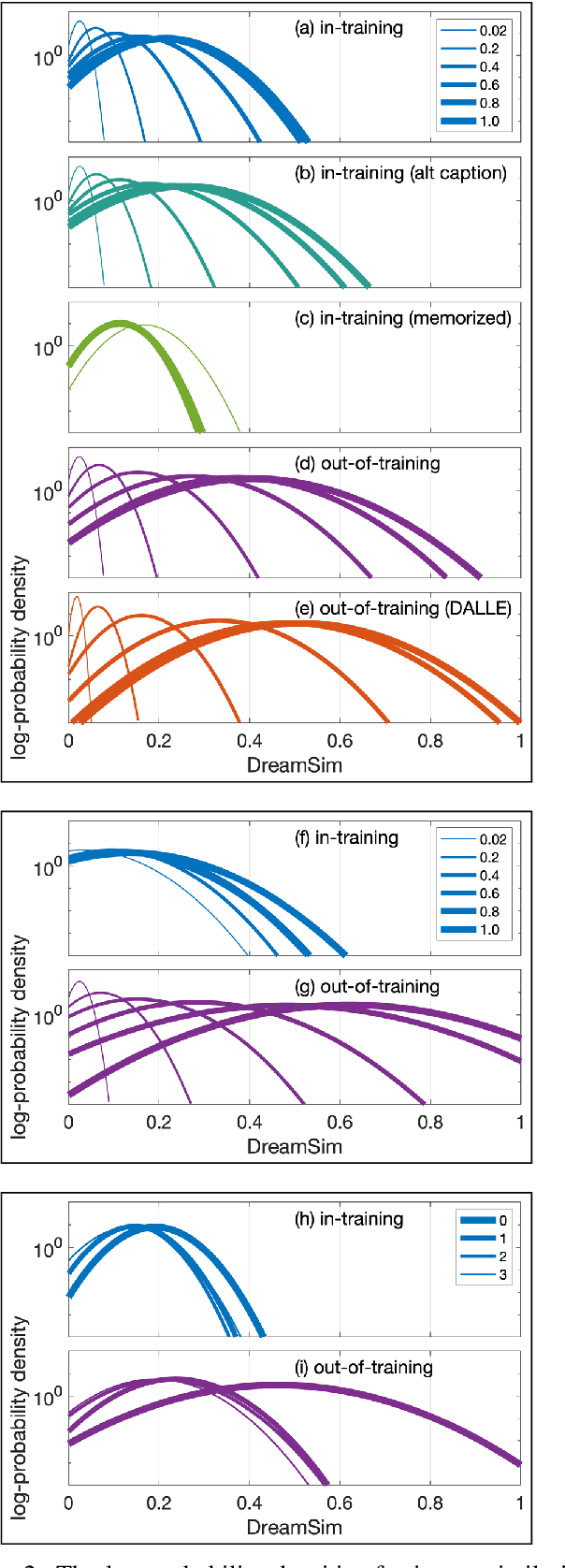

From a simple text prompt, generative-AI image models can create stunningly realistic and creative images bounded, it seems, by only our imagination. These models have achieved this remarkable feat thanks, in part, to the ingestion of billions of images collected from nearly every corner of the internet. Many creators have understandably expressed concern over how their intellectual property has been ingested without their permission or a mechanism to opt out of training. As a result, questions of fair use and copyright infringement have quickly emerged. We describe a method that allows us to determine if a model was trained on a specific image or set of images. This method is computationally efficient and assumes no explicit knowledge of the model architecture or weights (so-called black-box membership inference). We anticipate that this method will be crucial for auditing existing models and, looking ahead, ensuring the fairer development and deployment of generative AI models.
Human Action CLIPS: Detecting AI-generated Human Motion
Nov 30, 2024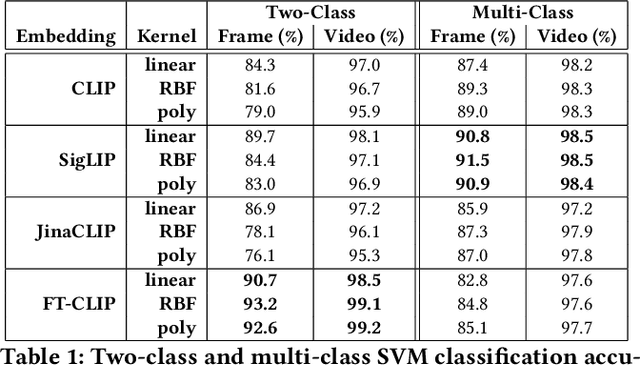

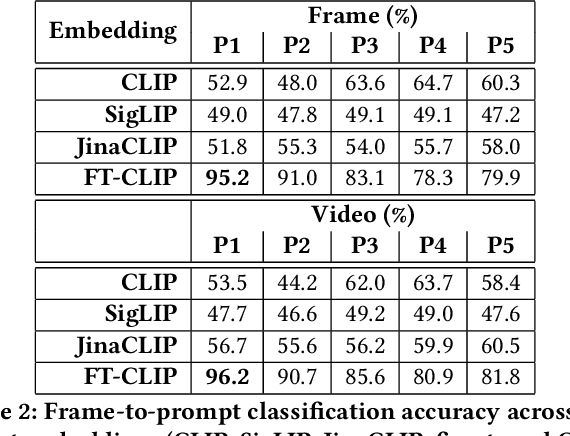
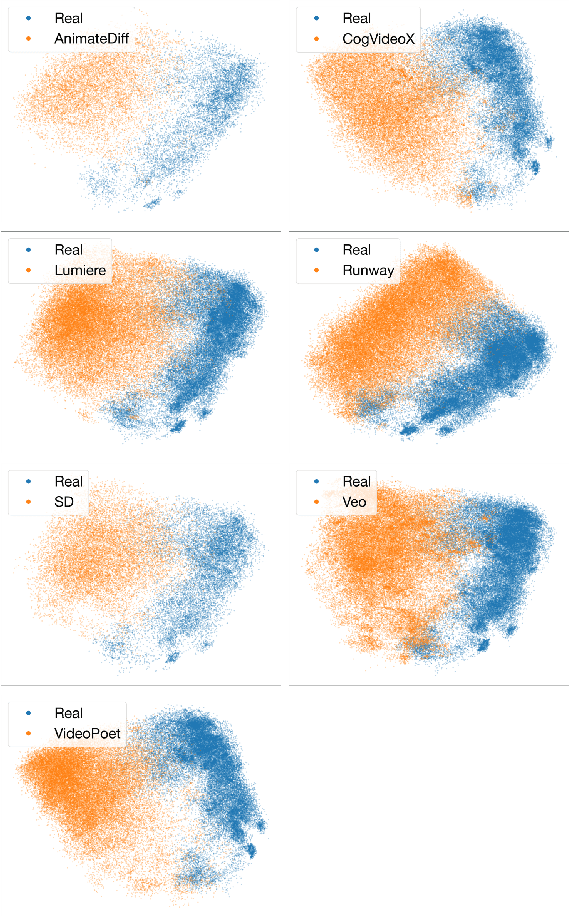
Full-blown AI-generated video generation continues its journey through the uncanny valley to produce content that is perceptually indistinguishable from reality. Intermixed with many exciting and creative applications are malicious applications that harm individuals, organizations, and democracies. We describe an effective and robust technique for distinguishing real from AI-generated human motion. This technique leverages a multi-modal semantic embedding, making it robust to the types of laundering that typically confound more low- to mid-level approaches. This method is evaluated against a custom-built dataset of video clips with human actions generated by seven text-to-video AI models and matching real footage.
DeepSpeak Dataset v1.0
Aug 09, 2024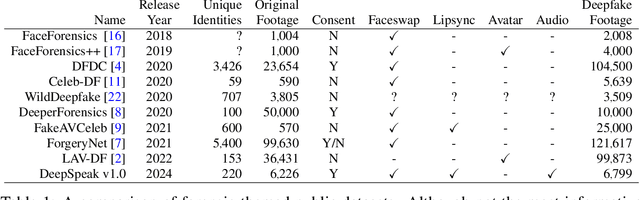

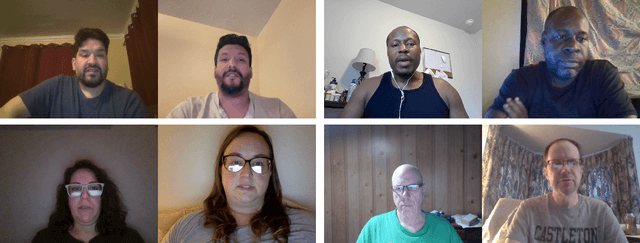
We describe a large-scale dataset--{\em DeepSpeak}--of real and deepfake footage of people talking and gesturing in front of their webcams. The real videos in this first version of the dataset consist of $9$ hours of footage from $220$ diverse individuals. Constituting more than 25 hours of footage, the fake videos consist of a range of different state-of-the-art face-swap and lip-sync deepfakes with natural and AI-generated voices. We expect to release future versions of this dataset with different and updated deepfake technologies. This dataset is made freely available for research and non-commercial uses; requests for commercial use will be considered.