Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepSpeak Dataset v1.0
Paper and Code
Aug 09, 2024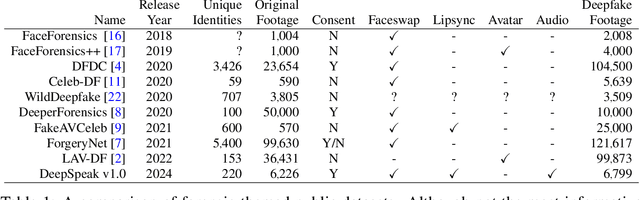

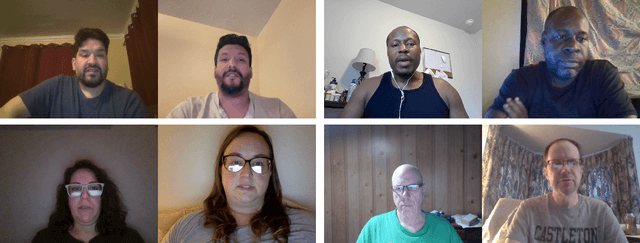
We describe a large-scale dataset--{\em DeepSpeak}--of real and deepfake footage of people talking and gesturing in front of their webcams. The real videos in this first version of the dataset consist of $9$ hours of footage from $220$ diverse individuals. Constituting more than 25 hours of footage, the fake videos consist of a range of different state-of-the-art face-swap and lip-sync deepfakes with natural and AI-generated voices. We expect to release future versions of this dataset with different and updated deepfake technologies. This dataset is made freely available for research and non-commercial uses; requests for commercial use will be considered.
View paper on