 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe DeepSpeak-Agentic Dataset
Jun 02, 2026We present DeepSpeak-Agentic, a dataset of videos comprising over 37 hours of semi-structured conversations between a human and an embodied AI agent. We use this dataset to evaluate the automatic forensic identification (audio, video, or text) of AI agents, study the nature of human-agent interactions, and provide a benchmark for future advances in the large-language models and AI-generated voices and faces that power embodied AI agents. We also contribute a scalable data-capture system that creates agents, automatically pairs them with human crowd workers, records audiovisual conversations across specified scenarios, and identifies and separates the human and agent in the combined stream.
People are poorly equipped to detect AI-powered voice clones
Oct 03, 2024As generative AI continues its ballistic trajectory, everything from text to audio, image, and video generation continues to improve in mimicking human-generated content. Through a series of perceptual studies, we report on the realism of AI-generated voices in terms of identity matching and naturalness. We find human participants cannot reliably identify short recordings (less than 20 seconds) of AI-generated voices. Specifically, participants mistook the identity of an AI-voice for its real counterpart 80% of the time, and correctly identified a voice as AI-generated only 60% of the time. In all cases, performance is independent of the demographics of the speaker or listener.
DeepSpeak Dataset v1.0
Aug 09, 2024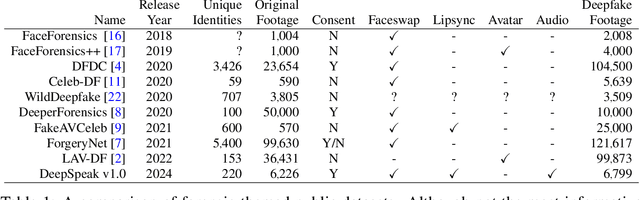

We describe a large-scale dataset--{\em DeepSpeak}--of real and deepfake footage of people talking and gesturing in front of their webcams. The real videos in this first version of the dataset consist of $9$ hours of footage from $220$ diverse individuals. Constituting more than 25 hours of footage, the fake videos consist of a range of different state-of-the-art face-swap and lip-sync deepfakes with natural and AI-generated voices. We expect to release future versions of this dataset with different and updated deepfake technologies. This dataset is made freely available for research and non-commercial uses; requests for commercial use will be considered.
Single and Multi-Speaker Cloned Voice Detection: From Perceptual to Learned Features
Jul 15, 2023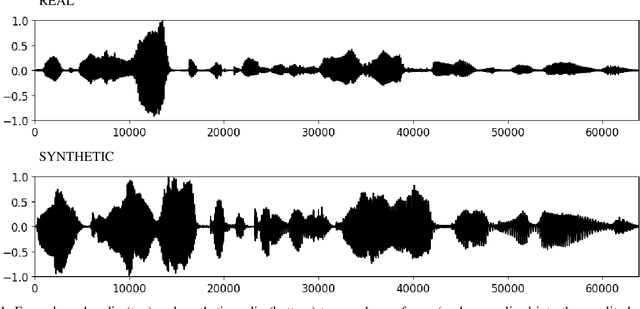


Synthetic-voice cloning technologies have seen significant advances in recent years, giving rise to a range of potential harms. From small- and large-scale financial fraud to disinformation campaigns, the need for reliable methods to differentiate real and synthesized voices is imperative. We describe three techniques for differentiating a real from a cloned voice designed to impersonate a specific person. These three approaches differ in their feature extraction stage with low-dimensional perceptual features offering high interpretability but lower accuracy, to generic spectral features, and end-to-end learned features offering less interpretability but higher accuracy. We show the efficacy of these approaches when trained on a single speaker's voice and when trained on multiple voices. The learned features consistently yield an equal error rate between $0\%$ and $4\%$, and are reasonably robust to adversarial laundering.
The Role of Metadata in Non-Fungible Tokens: Marketplace Analysis and Collection Organization
Sep 28, 2022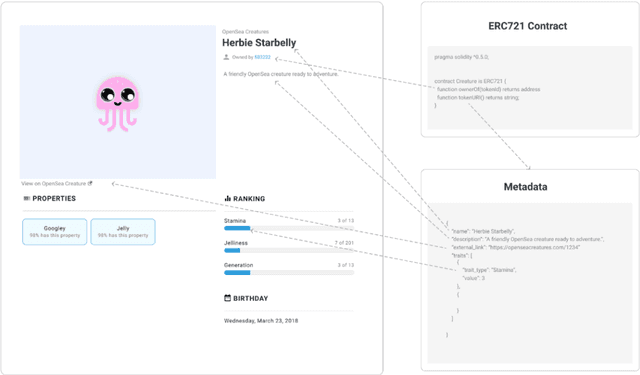

An explosion of interest in Non-Fungible Tokens (NFTs) has led to the emergence of vibrant online marketplaces that enable users to buy, sell and create digital assets. Largely considered contractual representations of digital artworks, NFTs allow ownership and authenticity to be proven through storing an asset and its associated metadata on a Blockchain. Yet, variation exists between chains, token protocols (such as the ERC-721 NFT standard) and marketplaces, leading to inconsistencies in the definitions and roles of token metadata. This research thus aims to define metadata in the context of NFTs, explore the boundary of metadata and asset data within tokens, and understand the variances and impacts these structures have on the curation of NFTs within online marketplaces and collections.