 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe DeepSpeak-Agentic Dataset
Jun 02, 2026We present DeepSpeak-Agentic, a dataset of videos comprising over 37 hours of semi-structured conversations between a human and an embodied AI agent. We use this dataset to evaluate the automatic forensic identification (audio, video, or text) of AI agents, study the nature of human-agent interactions, and provide a benchmark for future advances in the large-language models and AI-generated voices and faces that power embodied AI agents. We also contribute a scalable data-capture system that creates agents, automatically pairs them with human crowd workers, records audiovisual conversations across specified scenarios, and identifies and separates the human and agent in the combined stream.
AI-Powered Facial Mask Removal Is Not Suitable For Biometric Identification
Mar 29, 2026Recently, crowd-sourced online criminal investigations have used generative-AI to enhance low-quality visual evidence. In one high-profile case, social-media users circulated an "AI-unmasked" image of a federal agent involved in a fatal shooting, fueling a wide-spread misidentification. In response to this and similar incidents, we conducted a large-scale analysis evaluating the efficacy and risks of commercial AI-powered facial unmasking, specifically assessing whether the resulting faces can be reliably matched to true identities.
Has an AI model been trained on your images?
Jan 11, 2025
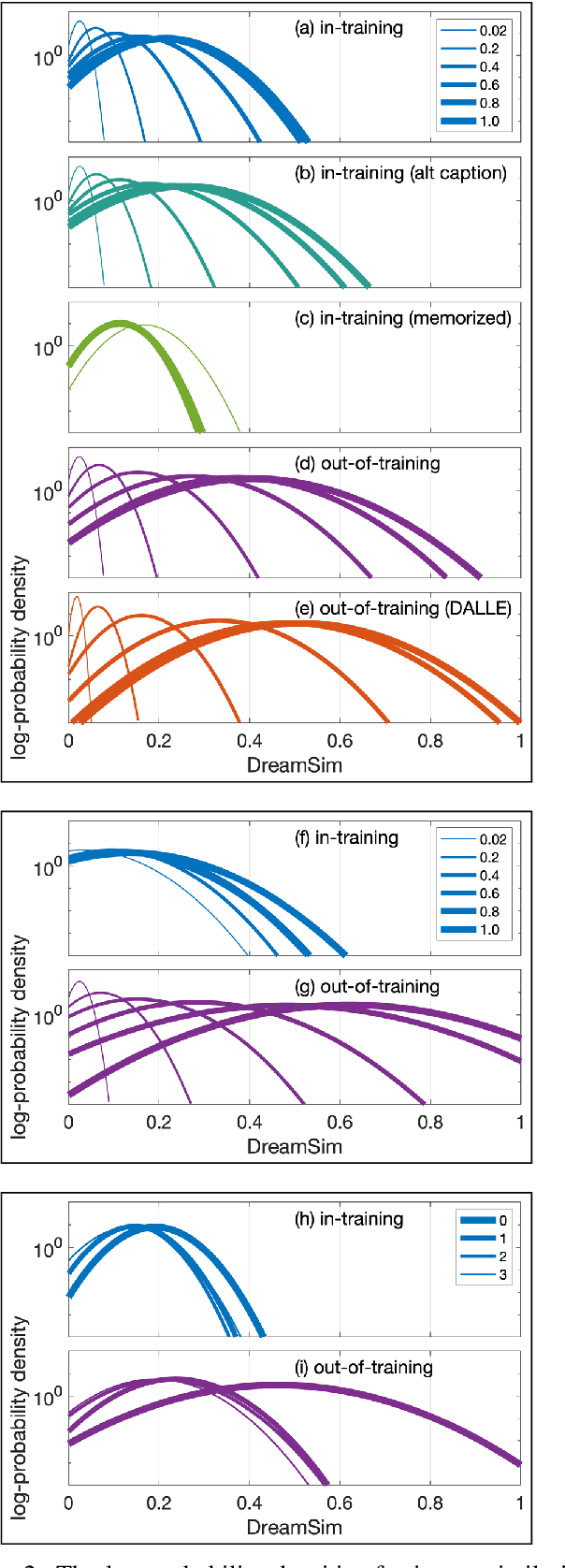

From a simple text prompt, generative-AI image models can create stunningly realistic and creative images bounded, it seems, by only our imagination. These models have achieved this remarkable feat thanks, in part, to the ingestion of billions of images collected from nearly every corner of the internet. Many creators have understandably expressed concern over how their intellectual property has been ingested without their permission or a mechanism to opt out of training. As a result, questions of fair use and copyright infringement have quickly emerged. We describe a method that allows us to determine if a model was trained on a specific image or set of images. This method is computationally efficient and assumes no explicit knowledge of the model architecture or weights (so-called black-box membership inference). We anticipate that this method will be crucial for auditing existing models and, looking ahead, ensuring the fairer development and deployment of generative AI models.
Human Action CLIPS: Detecting AI-generated Human Motion
Nov 30, 2024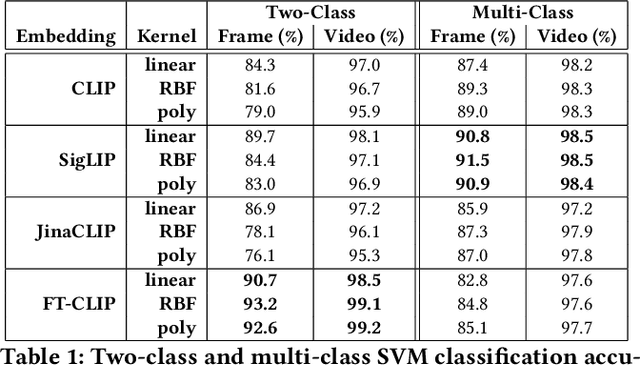

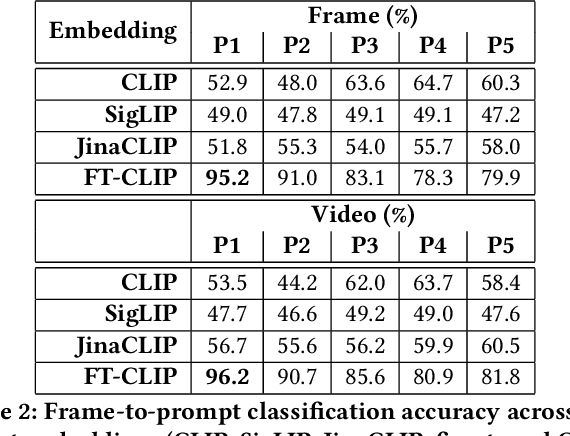
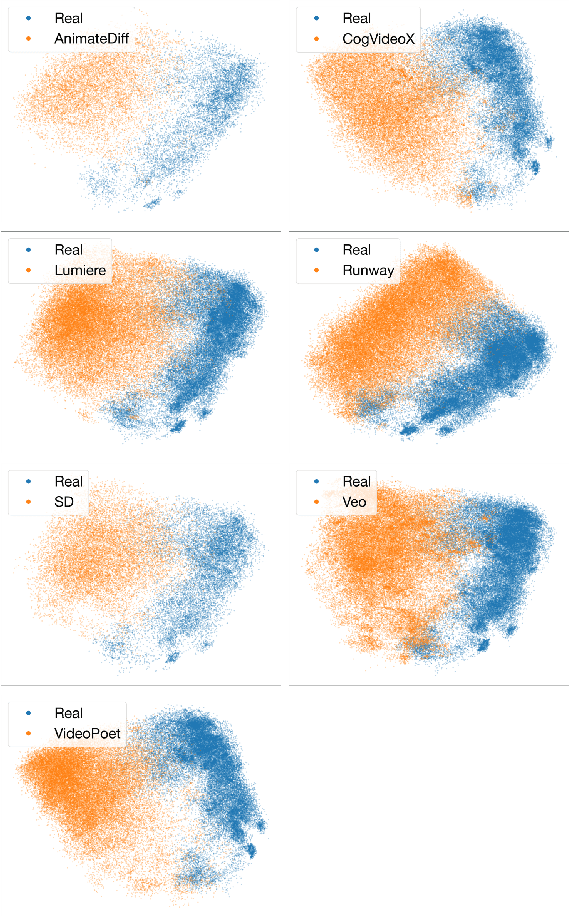
Full-blown AI-generated video generation continues its journey through the uncanny valley to produce content that is perceptually indistinguishable from reality. Intermixed with many exciting and creative applications are malicious applications that harm individuals, organizations, and democracies. We describe an effective and robust technique for distinguishing real from AI-generated human motion. This technique leverages a multi-modal semantic embedding, making it robust to the types of laundering that typically confound more low- to mid-level approaches. This method is evaluated against a custom-built dataset of video clips with human actions generated by seven text-to-video AI models and matching real footage.
People are poorly equipped to detect AI-powered voice clones
Oct 03, 2024As generative AI continues its ballistic trajectory, everything from text to audio, image, and video generation continues to improve in mimicking human-generated content. Through a series of perceptual studies, we report on the realism of AI-generated voices in terms of identity matching and naturalness. We find human participants cannot reliably identify short recordings (less than 20 seconds) of AI-generated voices. Specifically, participants mistook the identity of an AI-voice for its real counterpart 80% of the time, and correctly identified a voice as AI-generated only 60% of the time. In all cases, performance is independent of the demographics of the speaker or listener.
DeepSpeak Dataset v1.0
Aug 09, 2024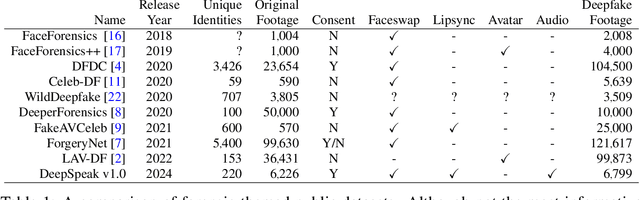

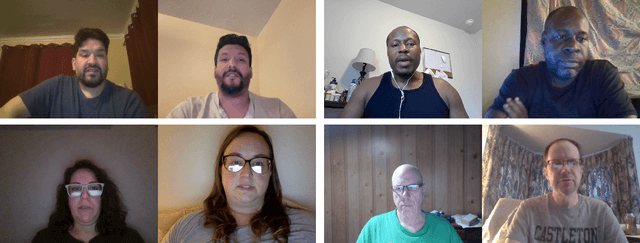
We describe a large-scale dataset--{\em DeepSpeak}--of real and deepfake footage of people talking and gesturing in front of their webcams. The real videos in this first version of the dataset consist of $9$ hours of footage from $220$ diverse individuals. Constituting more than 25 hours of footage, the fake videos consist of a range of different state-of-the-art face-swap and lip-sync deepfakes with natural and AI-generated voices. We expect to release future versions of this dataset with different and updated deepfake technologies. This dataset is made freely available for research and non-commercial uses; requests for commercial use will be considered.
Misinformation is not about Bad Facts: An Analysis of the Production and Consumption of Fringe Content
Mar 13, 2024What if misinformation is not an information problem at all? Our findings suggest that online fringe ideologies spread through the use of content that is consensus-based and "factually correct". We found that Australian news publishers with both moderate and far-right political leanings contain comparable levels of information completeness and quality; and furthermore, that far-right Twitter users often share from moderate sources. However, a stark difference emerges when we consider two additional factors: 1) the narrow topic selection of articles by far-right users, suggesting that they cherrypick only news articles that engage with specific topics of their concern, and 2) the difference between moderate and far-right publishers when we examine the writing style of their articles. Furthermore, we can even identify users prone to sharing misinformation based on their communication style. These findings have important implications for countering online misinformation, as they highlight the powerful role that users' personal bias towards specific topics, and publishers' writing styles, have in amplifying fringe ideologies online.
Finding AI-Generated Faces in the Wild
Nov 20, 2023



AI-based image generation has continued to rapidly improve, producing increasingly more realistic images with fewer obvious visual flaws. AI-generated images are being used to create fake online profiles which in turn are being used for spam, fraud, and disinformation campaigns. As the general problem of detecting any type of manipulated or synthesized content is receiving increasing attention, here we focus on a more narrow task of distinguishing a real face from an AI-generated face. This is particularly applicable when tackling inauthentic online accounts with a fake user profile photo. We show that by focusing on only faces, a more resilient and general-purpose artifact can be detected that allows for the detection of AI-generated faces from a variety of GAN- and diffusion-based synthesis engines, and across image resolutions (as low as 128 x 128 pixels) and qualities.
Nepotistically Trained Generative-AI Models Collapse
Nov 20, 2023

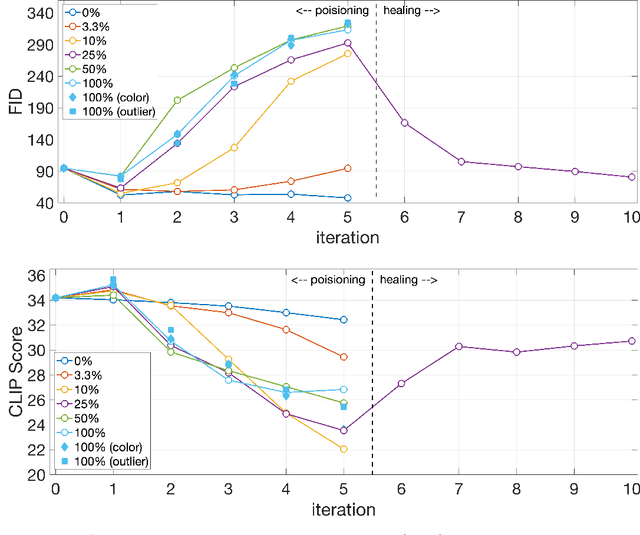
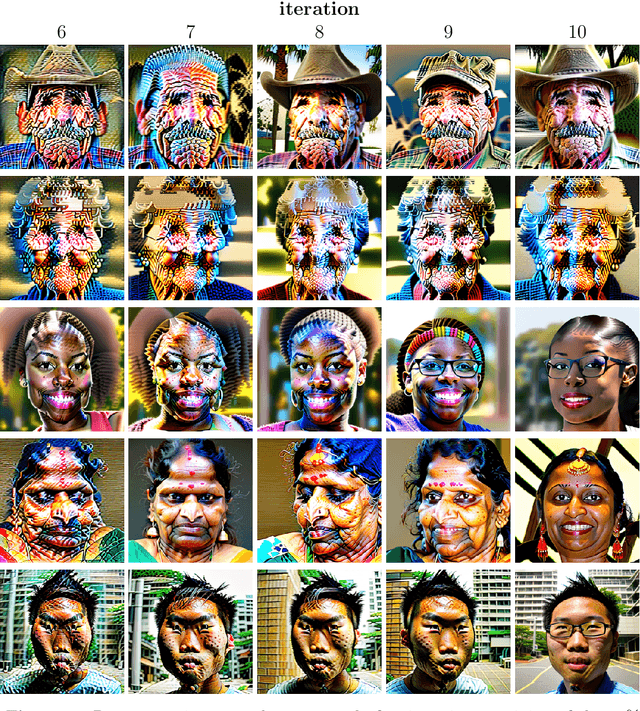
Trained on massive amounts of human-generated content, AI (artificial intelligence) image synthesis is capable of reproducing semantically coherent images that match the visual appearance of its training data. We show that when retrained on even small amounts of their own creation, these generative-AI models produce highly distorted images. We also show that this distortion extends beyond the text prompts used in retraining, and that once poisoned, the models struggle to fully heal even after retraining on only real images.
An Evaluation of Forensic Facial Recognition
Nov 10, 2023Recent advances in machine learning and computer vision have led to reported facial recognition accuracies surpassing human performance. We question if these systems will translate to real-world forensic scenarios in which a potentially low-resolution, low-quality, partially-occluded image is compared against a standard facial database. We describe the construction of a large-scale synthetic facial dataset along with a controlled facial forensic lineup, the combination of which allows for a controlled evaluation of facial recognition under a range of real-world conditions. Using this synthetic dataset, and a popular dataset of real faces, we evaluate the accuracy of two popular neural-based recognition systems. We find that previously reported face recognition accuracies of more than 95% drop to as low as 65% in this more challenging forensic scenario.