Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman Action CLIPS: Detecting AI-generated Human Motion
Paper and Code
Nov 30, 2024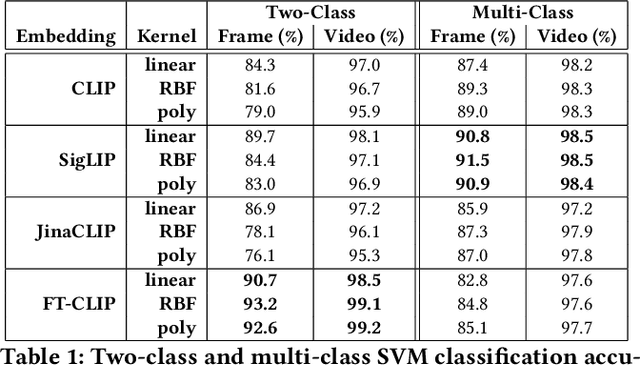

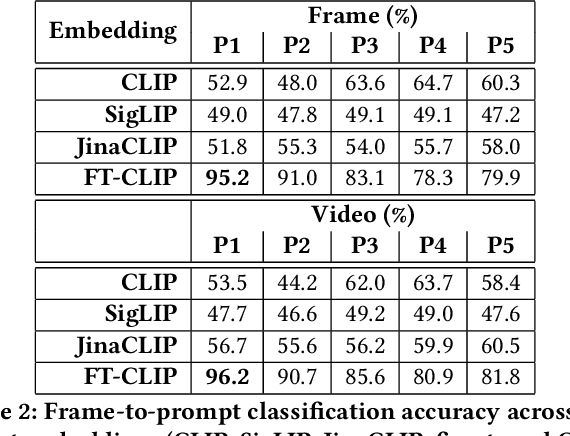
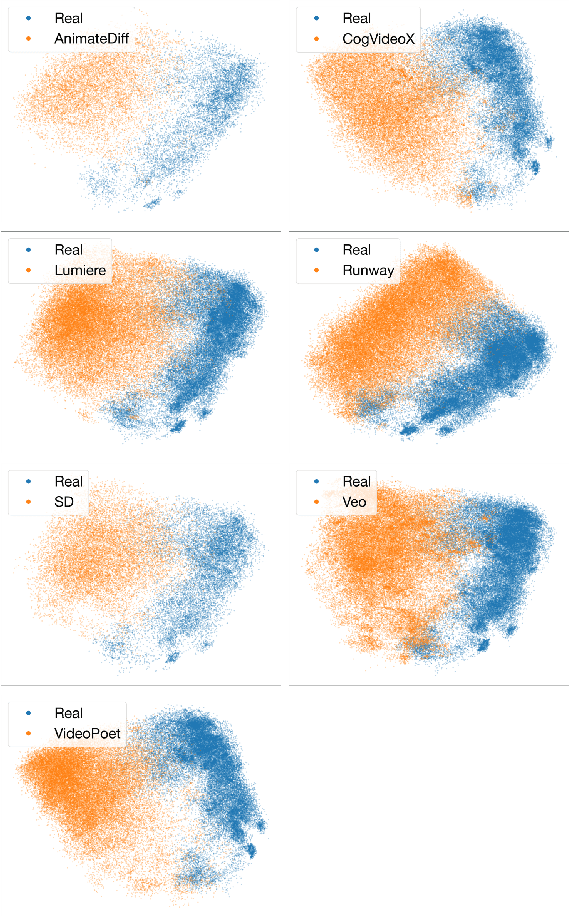
Full-blown AI-generated video generation continues its journey through the uncanny valley to produce content that is perceptually indistinguishable from reality. Intermixed with many exciting and creative applications are malicious applications that harm individuals, organizations, and democracies. We describe an effective and robust technique for distinguishing real from AI-generated human motion. This technique leverages a multi-modal semantic embedding, making it robust to the types of laundering that typically confound more low- to mid-level approaches. This method is evaluated against a custom-built dataset of video clips with human actions generated by seven text-to-video AI models and matching real footage.
View paper on