 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong Live Fine-Tuning: Task-Specific Transformers Outperform Zero-Shot LLMs for Misinformation Response Classification on Reddit
Jun 02, 2026As large language models (LLMs) become default tools for online information verification, an implicit assumption follows them: that scale and general capability are sufficient for nuanced classification of misinformation discourse. We test this assumption directly on 900 Reddit comments spanning three PolitiFact-verified misinformation claims (environment, health, immigration), labelled as belief (propagates the claim), fact-check (corrects it), or other. We compare nine models across three paradigms -- BART-MNLI, three Llama variants, three commercial frontier LLMs (Claude Haiku 4.5, Gemini Flash Lite 2.5, Claude Sonnet 4.6), and fine-tuned DistilBERT and RoBERTa -- under universal and topic-specific label schemas. The assumption does not hold. Fine-tuned RoBERTa reaches 0.62 macro-$F_1$ against a best zero-shot result of 0.50 (Claude Haiku 4.5), at a fraction of the per-query cost; the supervised advantage is concentrated on the belief class, the implicit, affective category every zero-shot model under-detects. Scaling does not help: Llama-3-8B matches Llama-3-70B, and Claude Sonnet 4.6 underperforms the smaller Haiku under generic labels, collapsing belief detection to 0.17 and refusing outright on a subset of comments flagged as sensitive. This is a safety-alignment artefact, not a capacity limit. Label schema and topic jointly shape zero-shot performance, with the same model varying by more than 0.13 macro-$F_1$ across topics under matched labels. In a verification context, where missing belief is the costlier error, task-specific fine-tuning remains the more reliable choice despite the proliferation of large generative models.
UTS at PsyDefDetect: Multi-Agent Councils and Absence-Based Reasoning for Defense Mechanism Classification
May 10, 2026This paper describes our system for classifying psychological defense mechanisms in emotional support dialogues using the Defense Mechanism Rating Scales (DMRS), placing second (F1 0.406) among 64 teams.1 A central insight is that defense mechanisms are defined by what is absent: missing affect, blocked cognition, denied reality. We encode this as an affect-cognition integration spectrum in prompt-level clinical rules, which account for the largest single gain (+11.4pp F1). Our architecture is a multi-phase deliberative council of Gemini 2.5 agents where class-specific advocates rate evidence strength rather than voting, achieving F1 0.382 with no fine-tuning - a top-5 result on its own. We find, however, that the council is confidently wrong about minority classes: 59-80% of stable minority predictions are incorrect, driven by a systematic "L7 attractor" in which emotional content defaults to the majority class. A targeted override ensemble from three fine-tuned Qwen3.5 models applies 16 overrides (+2.4pp), selected by a structured multi-agent system (builder, critic, regression guard) that produced a larger F1 gain in one iteration than 8 prior attempts combined.
Beyond Content: Behavioral Policies Reveal Actors in Information Operations
Feb 02, 2026The detection of online influence operations -- coordinated campaigns by malicious actors to spread narratives -- has traditionally depended on content analysis or network features. These approaches are increasingly brittle as generative models produce convincing text, platforms restrict access to behavioral data, and actors migrate to less-regulated spaces. We introduce a platform-agnostic framework that identifies malicious actors from their behavioral policies by modeling user activity as sequential decision processes. We apply this approach to 12,064 Reddit users, including 99 accounts linked to the Russian Internet Research Agency in Reddit's 2017 transparency report, analyzing over 38 million activity steps from 2015-2018. Activity-based representations, which model how users act rather than what they post, consistently outperform content models in detecting malicious accounts. When distinguishing trolls -- users engaged in coordinated manipulation -- from ordinary users, policy-based classifiers achieve a median macro-$F_1$ of 94.9%, compared to 91.2% for text embeddings. Policy features also enable earlier detection from short traces and degrade more gracefully under evasion strategies or data corruption. These findings show that behavioral dynamics encode stable, discriminative signals of manipulation and point to resilient, cross-platform detection strategies in the era of synthetic content and limited data access.
DREAMS: A Social Exchange Theory-Informed Modeling of Misinformation Engagement on Social Media
Feb 02, 2026Social media engagement prediction is a central challenge in computational social science, particularly for understanding how users interact with misinformation. Existing approaches often treat engagement as a homogeneous time-series signal, overlooking the heterogeneous social mechanisms and platform designs that shape how misinformation spreads. In this work, we ask: ``Can neural architectures discover social exchange principles from behavioral data alone?'' We introduce \textsc{Dreams} (\underline{D}isentangled \underline{R}epresentations and \underline{E}pisodic \underline{A}daptive \underline{M}odeling for \underline{S}ocial media misinformation engagements), a social exchange theory-guided framework that models misinformation engagement as a dynamic process of social exchange. Rather than treating engagement as a static outcome, \textsc{Dreams} models it as a sequence-to-sequence adaptation problem, where each action reflects an evolving negotiation between user effort and social reward conditioned by platform context. It integrates adaptive mechanisms to learn how emotional and contextual signals propagate through time and across platforms. On a cross-platform dataset spanning $7$ platforms and 2.37M posts collected between 2021 and 2025, \textsc{Dreams} achieves state-of-the-art performance in predicting misinformation engagements, reaching a mean absolute percentage error of $19.25$\%. This is a $43.6$\% improvement over the strongest baseline. Beyond predictive gains, the model reveals consistent cross-platform patterns that align with social exchange principles, suggesting that integrating behavioral theory can enhance empirical modeling of online misinformation engagement. The source code is available at: https://github.com/ltian678/DREAMS.
Learning to Make Friends: Coaching LLM Agents toward Emergent Social Ties
Oct 22, 2025Can large language model (LLM) agents reproduce the complex social dynamics that characterize human online behavior -- shaped by homophily, reciprocity, and social validation -- and what memory and learning mechanisms enable such dynamics to emerge? We present a multi-agent LLM simulation framework in which agents repeatedly interact, evaluate one another, and adapt their behavior through in-context learning accelerated by a coaching signal. To model human social behavior, we design behavioral reward functions that capture core drivers of online engagement, including social interaction, information seeking, self-presentation, coordination, and emotional support. These rewards align agent objectives with empirically observed user motivations, enabling the study of how network structures and group formations emerge from individual decision-making. Our experiments show that coached LLM agents develop stable interaction patterns and form emergent social ties, yielding network structures that mirror properties of real online communities. By combining behavioral rewards with in-context adaptation, our framework establishes a principled testbed for investigating collective dynamics in LLM populations and reveals how artificial agents may approximate or diverge from human-like social behavior.
Estimating Online Influence Needs Causal Modeling! Counterfactual Analysis of Social Media Engagement
May 25, 2025Understanding true influence in social media requires distinguishing correlation from causation--particularly when analyzing misinformation spread. While existing approaches focus on exposure metrics and network structures, they often fail to capture the causal mechanisms by which external temporal signals trigger engagement. We introduce a novel joint treatment-outcome framework that leverages existing sequential models to simultaneously adapt to both policy timing and engagement effects. Our approach adapts causal inference techniques from healthcare to estimate Average Treatment Effects (ATE) within the sequential nature of social media interactions, tackling challenges from external confounding signals. Through our experiments on real-world misinformation and disinformation datasets, we show that our models outperform existing benchmarks by 15--22% in predicting engagement across diverse counterfactual scenarios, including exposure adjustment, timing shifts, and varied intervention durations. Case studies on 492 social media users show our causal effect measure aligns strongly with the gold standard in influence estimation, the expert-based empirical influence.
Before It's Too Late: A State Space Model for the Early Prediction of Misinformation and Disinformation Engagement
Feb 07, 2025In today's digital age, conspiracies and information campaigns can emerge rapidly and erode social and democratic cohesion. While recent deep learning approaches have made progress in modeling engagement through language and propagation models, they struggle with irregularly sampled data and early trajectory assessment. We present IC-Mamba, a novel state space model that forecasts social media engagement by modeling interval-censored data with integrated temporal embeddings. Our model excels at predicting engagement patterns within the crucial first 15-30 minutes of posting (RMSE 0.118-0.143), enabling rapid assessment of content reach. By incorporating interval-censored modeling into the state space framework, IC-Mamba captures fine-grained temporal dynamics of engagement growth, achieving a 4.72% improvement over state-of-the-art across multiple engagement metrics (likes, shares, comments, and emojis). Our experiments demonstrate IC-Mamba's effectiveness in forecasting both post-level dynamics and broader narrative patterns (F1 0.508-0.751 for narrative-level predictions). The model maintains strong predictive performance across extended time horizons, successfully forecasting opinion-level engagement up to 28 days ahead using observation windows of 3-10 days. These capabilities enable earlier identification of potentially problematic content, providing crucial lead time for designing and implementing countermeasures. Code is available at: https://github.com/ltian678/ic-mamba. An interactive dashboard demonstrating our results is available at: https://ic-mamba.behavioral-ds.science.
Behavioral Homophily in Social Media via Inverse Reinforcement Learning: A Reddit Case Study
Feb 05, 2025



Online communities play a critical role in shaping societal discourse and influencing collective behavior in the real world. The tendency for people to connect with others who share similar characteristics and views, known as homophily, plays a key role in the formation of echo chambers which further amplify polarization and division. Existing works examining homophily in online communities traditionally infer it using content- or adjacency-based approaches, such as constructing explicit interaction networks or performing topic analysis. These methods fall short for platforms where interaction networks cannot be easily constructed and fail to capture the complex nature of user interactions across the platform. This work introduces a novel approach for quantifying user homophily. We first use an Inverse Reinforcement Learning (IRL) framework to infer users' policies, then use these policies as a measure of behavioral homophily. We apply our method to Reddit, conducting a case study across 5.9 million interactions over six years, demonstrating how this approach uncovers distinct behavioral patterns and user roles that vary across different communities. We further validate our behavioral homophily measure against traditional content-based homophily, offering a powerful method for analyzing social media dynamics and their broader societal implications. We find, among others, that users can behave very similarly (high behavioral homophily) when discussing entirely different topics like soccer vs e-sports (low topical homophily), and that there is an entire class of users on Reddit whose purpose seems to be to disagree with others.
What Drives Online Popularity: Author, Content or Sharers? Estimating Spread Dynamics with Bayesian Mixture Hawkes
Jun 12, 2024


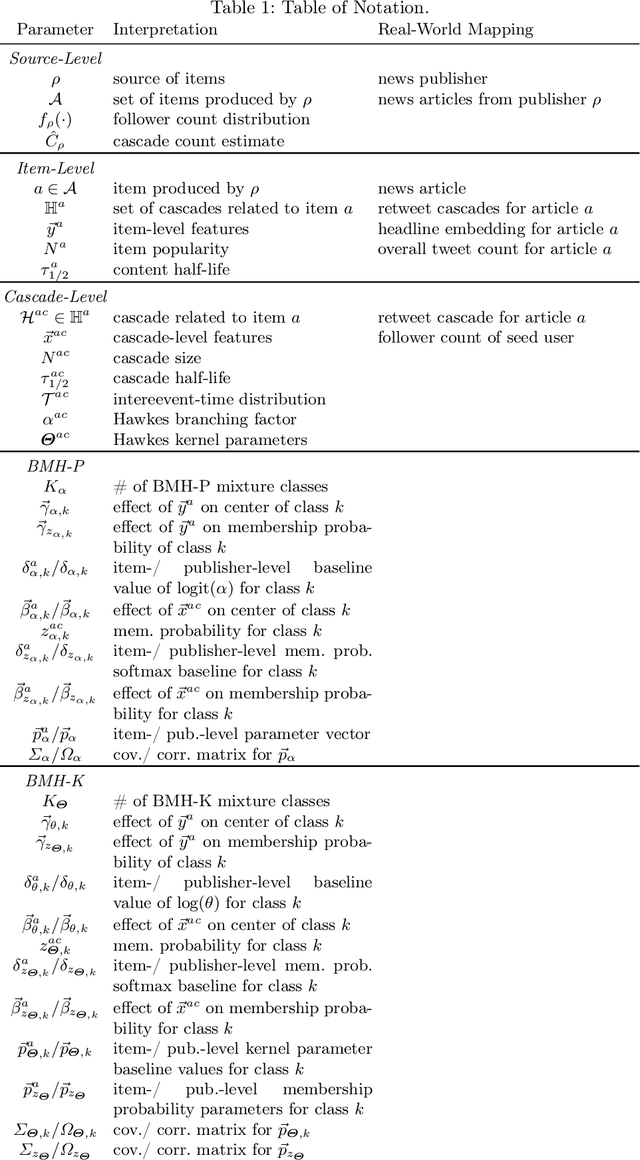
The spread of content on social media is shaped by intertwining factors on three levels: the source, the content itself, and the pathways of content spread. At the lowest level, the popularity of the sharing user determines its eventual reach. However, higher-level factors such as the nature of the online item and the credibility of its source also play crucial roles in determining how widely and rapidly the online item spreads. In this work, we propose the Bayesian Mixture Hawkes (BMH) model to jointly learn the influence of source, content and spread. We formulate the BMH model as a hierarchical mixture model of separable Hawkes processes, accommodating different classes of Hawkes dynamics and the influence of feature sets on these classes. We test the BMH model on two learning tasks, cold-start popularity prediction and temporal profile generalization performance, applying to two real-world retweet cascade datasets referencing articles from controversial and traditional media publishers. The BMH model outperforms the state-of-the-art models and predictive baselines on both datasets and utilizes cascade- and item-level information better than the alternatives. Lastly, we perform a counter-factual analysis where we apply the trained publisher-level BMH models to a set of article headlines and show that effectiveness of headline writing style (neutral, clickbait, inflammatory) varies across publishers. The BMH model unveils differences in style effectiveness between controversial and reputable publishers, where we find clickbait to be notably more effective for reputable publishers as opposed to controversial ones, which links to the latter's overuse of clickbait.
Author, Content or Sharers? Estimating Spread Dynamics with Bayesian Mixture Hawkes
Jun 05, 2024The spread of content on social media is shaped by intertwining factors on three levels: the source, the content itself, and the pathways of content spread. At the lowest level, the popularity of the sharing user determines its eventual reach. However, higher-level factors such as the nature of the online item and the credibility of its source also play crucial roles in determining how widely and rapidly the online item spreads. In this work, we propose the Bayesian Mixture Hawkes (BMH) model to jointly learn the influence of source, content and spread. We formulate the BMH model as a hierarchical mixture model of separable Hawkes processes, accommodating different classes of Hawkes dynamics and the influence of feature sets on these classes. We test the BMH model on two learning tasks, cold-start popularity prediction and temporal profile generalization performance, applying to two real-world retweet cascade datasets referencing articles from controversial and traditional media publishers. The BMH model outperforms the state-of-the-art models and predictive baselines on both datasets and utilizes cascade- and item-level information better than the alternatives. Lastly, we perform a counter-factual analysis where we apply the trained publisher-level BMH models to a set of article headlines and show that effectiveness of headline writing style (neutral, clickbait, inflammatory) varies across publishers. The BMH model unveils differences in style effectiveness between controversial and reputable publishers, where we find clickbait to be notably more effective for reputable publishers as opposed to controversial ones, which links to the latter's overuse of clickbait.