 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Content: Behavioral Policies Reveal Actors in Information Operations
Feb 02, 2026The detection of online influence operations -- coordinated campaigns by malicious actors to spread narratives -- has traditionally depended on content analysis or network features. These approaches are increasingly brittle as generative models produce convincing text, platforms restrict access to behavioral data, and actors migrate to less-regulated spaces. We introduce a platform-agnostic framework that identifies malicious actors from their behavioral policies by modeling user activity as sequential decision processes. We apply this approach to 12,064 Reddit users, including 99 accounts linked to the Russian Internet Research Agency in Reddit's 2017 transparency report, analyzing over 38 million activity steps from 2015-2018. Activity-based representations, which model how users act rather than what they post, consistently outperform content models in detecting malicious accounts. When distinguishing trolls -- users engaged in coordinated manipulation -- from ordinary users, policy-based classifiers achieve a median macro-$F_1$ of 94.9%, compared to 91.2% for text embeddings. Policy features also enable earlier detection from short traces and degrade more gracefully under evasion strategies or data corruption. These findings show that behavioral dynamics encode stable, discriminative signals of manipulation and point to resilient, cross-platform detection strategies in the era of synthetic content and limited data access.
Behavioral Homophily in Social Media via Inverse Reinforcement Learning: A Reddit Case Study
Feb 05, 2025



Online communities play a critical role in shaping societal discourse and influencing collective behavior in the real world. The tendency for people to connect with others who share similar characteristics and views, known as homophily, plays a key role in the formation of echo chambers which further amplify polarization and division. Existing works examining homophily in online communities traditionally infer it using content- or adjacency-based approaches, such as constructing explicit interaction networks or performing topic analysis. These methods fall short for platforms where interaction networks cannot be easily constructed and fail to capture the complex nature of user interactions across the platform. This work introduces a novel approach for quantifying user homophily. We first use an Inverse Reinforcement Learning (IRL) framework to infer users' policies, then use these policies as a measure of behavioral homophily. We apply our method to Reddit, conducting a case study across 5.9 million interactions over six years, demonstrating how this approach uncovers distinct behavioral patterns and user roles that vary across different communities. We further validate our behavioral homophily measure against traditional content-based homophily, offering a powerful method for analyzing social media dynamics and their broader societal implications. We find, among others, that users can behave very similarly (high behavioral homophily) when discussing entirely different topics like soccer vs e-sports (low topical homophily), and that there is an entire class of users on Reddit whose purpose seems to be to disagree with others.
Detect Hate Speech in Unseen Domains using Multi-Task Learning: A Case Study of Political Public Figures
Aug 22, 2022
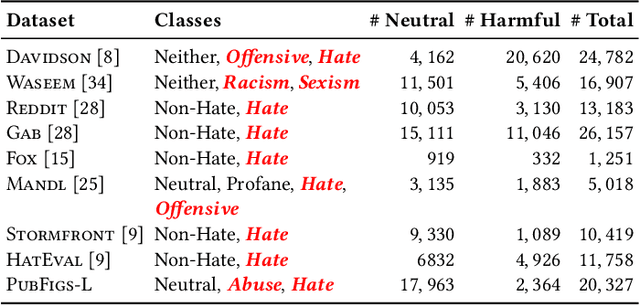
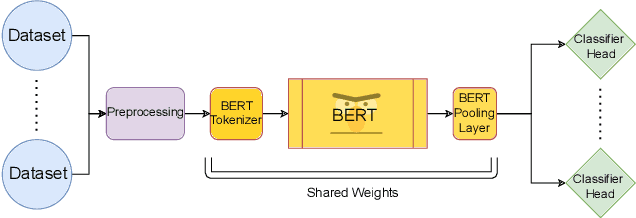
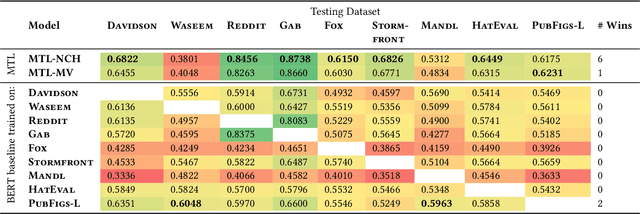
Automatic identification of hateful and abusive content is vital in combating the spread of harmful online content and its damaging effects. Most existing works evaluate models by examining the generalization error on train-test splits on hate speech datasets. These datasets often differ in their definitions and labeling criteria, leading to poor model performance when predicting across new domains and datasets. In this work, we propose a new Multi-task Learning (MTL) pipeline that utilizes MTL to train simultaneously across multiple hate speech datasets to construct a more encompassing classification model. We simulate evaluation on new previously unseen datasets by adopting a leave-one-out scheme in which we omit a target dataset from training and jointly train on the other datasets. Our results consistently outperform a large sample of existing work. We show strong results when examining generalization error in train-test splits and substantial improvements when predicting on previously unseen datasets. Furthermore, we assemble a novel dataset, dubbed PubFigs, focusing on the problematic speech of American Public Political Figures. We automatically detect problematic speech in the $305,235$ tweets in PubFigs, and we uncover insights into the posting behaviors of public figures.