 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArt and the science of generative AI: A deeper dive
Jun 07, 2023A new class of tools, colloquially called generative AI, can produce high-quality artistic media for visual arts, concept art, music, fiction, literature, video, and animation. The generative capabilities of these tools are likely to fundamentally alter the creative processes by which creators formulate ideas and put them into production. As creativity is reimagined, so too may be many sectors of society. Understanding the impact of generative AI - and making policy decisions around it - requires new interdisciplinary scientific inquiry into culture, economics, law, algorithms, and the interaction of technology and creativity. We argue that generative AI is not the harbinger of art's demise, but rather is a new medium with its own distinct affordances. In this vein, we consider the impacts of this new medium on creators across four themes: aesthetics and culture, legal questions of ownership and credit, the future of creative work, and impacts on the contemporary media ecosystem. Across these themes, we highlight key research questions and directions to inform policy and beneficial uses of the technology.
Learning to See: You Are What You See
Feb 28, 2020



The authors present a visual instrument developed as part of the creation of the artwork Learning to See. The artwork explores bias in artificial neural networks and provides mechanisms for the manipulation of specifically trained for real-world representations. The exploration of these representations acts as a metaphor for the process of developing a visual understanding and/or visual vocabulary of the world. These representations can be explored and manipulated in real time, and have been produced in such a way so as to reflect specific creative perspectives that call into question the relationship between how both artificial neural networks and humans may construct meaning.
* Presented as an Art Paper at SIGGRAPH 2019
Deep Meditations: Controlled navigation of latent space
Feb 27, 2020



We introduce a method which allows users to creatively explore and navigate the vast latent spaces of deep generative models. Specifically, our method enables users to \textit{discover} and \textit{design} \textit{trajectories} in these high dimensional spaces, to construct stories, and produce time-based media such as videos---\textit{with meaningful control over narrative}. Our goal is to encourage and aid the use of deep generative models as a medium for creative expression and story telling with meaningful human control. Our method is analogous to traditional video production pipelines in that we use a conventional non-linear video editor with proxy clips, and conform with arrays of latent space vectors. Examples can be seen at \url{http://deepmeditations.ai}.
Calligraphic Stylisation Learning with a Physiologically Plausible Model of Movement and Recurrent Neural Networks
Sep 24, 2017
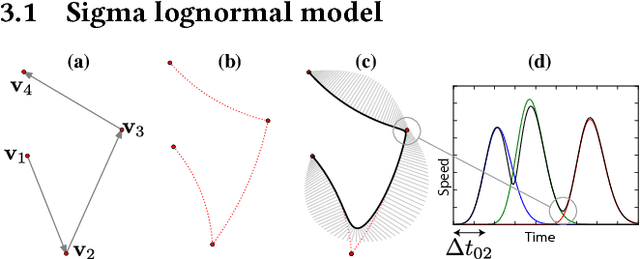
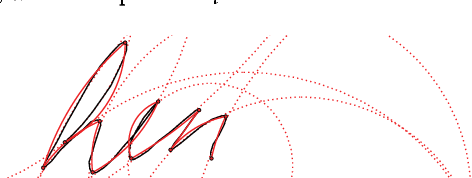
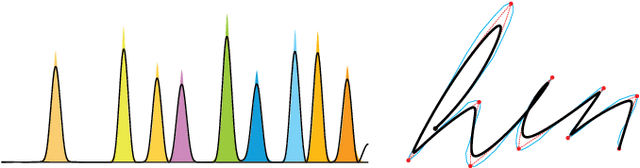
We propose a computational framework to learn stylisation patterns from example drawings or writings, and then generate new trajectories that possess similar stylistic qualities. We particularly focus on the generation and stylisation of trajectories that are similar to the ones that can be seen in calligraphy and graffiti art. Our system is able to extract and learn dynamic and visual qualities from a small number of user defined examples which can be recorded with a digitiser device, such as a tablet, mouse or motion capture sensors. Our system is then able to transform new user drawn traces to be kinematically and stylistically similar to the training examples. We implement the system using a Recurrent Mixture Density Network (RMDN) combined with a representation given by the parameters of the Sigma Lognormal model, a physiologically plausible model of movement that has been shown to closely reproduce the velocity and trace of human handwriting gestures.
Real-time interactive sequence generation and control with Recurrent Neural Network ensembles
Feb 09, 2017

Recurrent Neural Networks (RNN), particularly Long Short Term Memory (LSTM) RNNs, are a popular and very successful method for learning and generating sequences. However, current generative RNN techniques do not allow real-time interactive control of the sequence generation process, thus aren't well suited for live creative expression. We propose a method of real-time continuous control and 'steering' of sequence generation using an ensemble of RNNs and dynamically altering the mixture weights of the models. We demonstrate the method using character based LSTM networks and a gestural interface allowing users to 'conduct' the generation of text.
Collaborative creativity with Monte-Carlo Tree Search and Convolutional Neural Networks
Dec 14, 2016

We investigate a human-machine collaborative drawing environment in which an autonomous agent sketches images while optionally allowing a user to directly influence the agent's trajectory. We combine Monte Carlo Tree Search with image classifiers and test both shallow models (e.g. multinomial logistic regression) and deep Convolutional Neural Networks (e.g. LeNet, Inception v3). We found that using the shallow model, the agent produces a limited variety of images, which are noticably recogonisable by humans. However, using the deeper models, the agent produces a more diverse range of images, and while the agent remains very confident (99.99%) in having achieved its objective, to humans they mostly resemble unrecognisable 'random' noise. We relate this to recent research which also discovered that 'deep neural networks are easily fooled' \cite{Nguyen2015} and we discuss possible solutions and future directions for the research.