 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Image Abstraction Using Long Smoothing B-Splines
Nov 07, 2025We integrate smoothing B-splines into a standard differentiable vector graphics (DiffVG) pipeline through linear mapping, and show how this can be used to generate smooth and arbitrarily long paths within image-based deep learning systems. We take advantage of derivative-based smoothing costs for parametric control of fidelity vs. simplicity tradeoffs, while also enabling stylization control in geometric and image spaces. The proposed pipeline is compatible with recent vector graphics generation and vectorization methods. We demonstrate the versatility of our approach with four applications aimed at the generation of stylized vector graphics: stylized space-filling path generation, stroke-based image abstraction, closed-area image abstraction, and stylized text generation.
Network Bending: Manipulating The Inner Representations of Deep Generative Models
May 25, 2020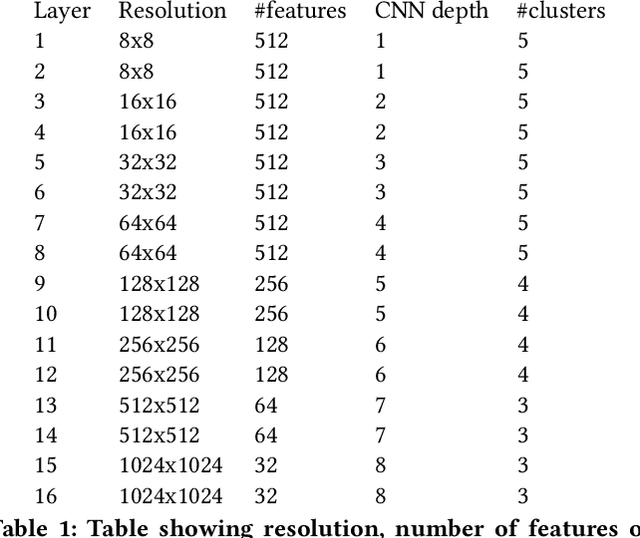
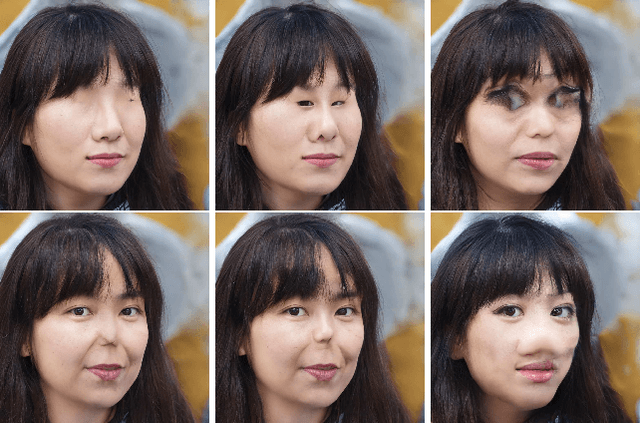


We introduce a new framework for interacting with and manipulating deep generative models that we call network bending. We present a comprehensive set of deterministic transformations that can be inserted as distinct layers into the computational graph of a trained generative neural network and applied during inference. In addition, we present a novel algorithm for clustering features based on their spatial activation maps. This allows features to be grouped together based on spatial similarity in an unsupervised fashion. This results in the meaningful manipulation of sets of features that correspond to the generation of a broad array of semantically significant aspects of the generated images. We demonstrate these transformations on the official pre-trained StyleGAN2 model trained on the FFHQ dataset. In doing so, we lay the groundwork for future interactive multimedia systems where the inner representation of deep generative models are manipulated for greater creative expression, whilst also increasing our understanding of how such "black-box systems" can be more meaningfully interpreted.
Amplifying The Uncanny
Feb 17, 2020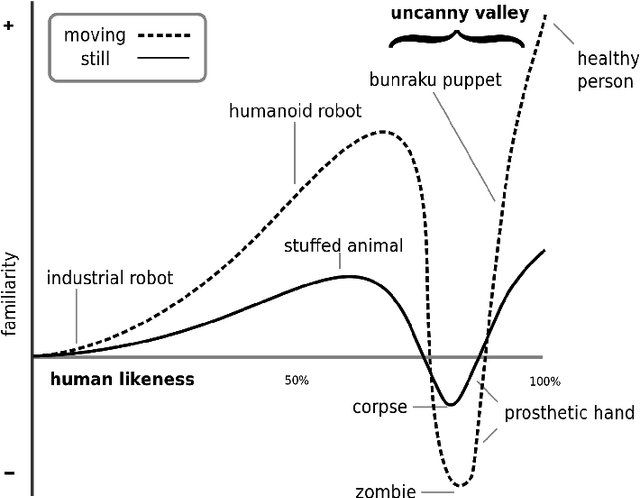



Deep neural networks have become remarkably good at producing realistic deepfakes, images of people that are (to the untrained eye) indistinguishable from real images. These are produced by algorithms that learn to distinguish between real and fake images and are optimised to generate samples that the system deems realistic. This paper, and the resulting series of artworks Being Foiled explore the aesthetic outcome of inverting this process and instead optimising the system to generate images that it sees as being fake. Maximising the unlikelihood of the data and in turn, amplifying the uncanny nature of these machine hallucinations.
Calligraphic Stylisation Learning with a Physiologically Plausible Model of Movement and Recurrent Neural Networks
Sep 24, 2017
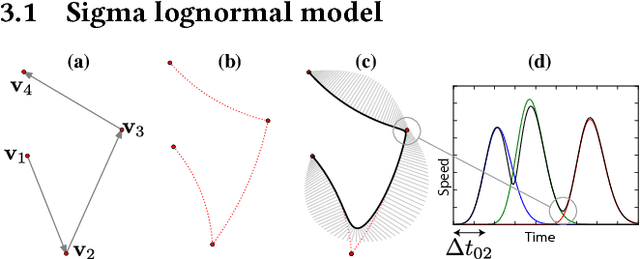
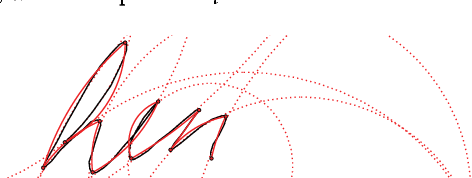
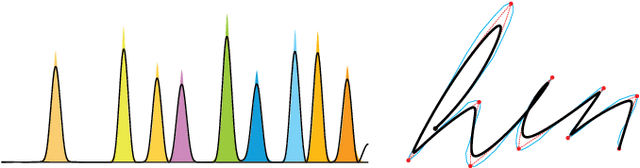
We propose a computational framework to learn stylisation patterns from example drawings or writings, and then generate new trajectories that possess similar stylistic qualities. We particularly focus on the generation and stylisation of trajectories that are similar to the ones that can be seen in calligraphy and graffiti art. Our system is able to extract and learn dynamic and visual qualities from a small number of user defined examples which can be recorded with a digitiser device, such as a tablet, mouse or motion capture sensors. Our system is then able to transform new user drawn traces to be kinematically and stylistically similar to the training examples. We implement the system using a Recurrent Mixture Density Network (RMDN) combined with a representation given by the parameters of the Sigma Lognormal model, a physiologically plausible model of movement that has been shown to closely reproduce the velocity and trace of human handwriting gestures.