 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttentionBender: Manipulating Cross-Attention in Video Diffusion Transformers as a Creative Probe
Apr 22, 2026We present AttentionBender, a tool that manipulates cross-attention in Video Diffusion Transformers to help artists probe the internal mechanics of black-box video generation. While generative outputs are increasingly realistic, prompt-only control limits artists' ability to build intuition for the model's material process or to work beyond its default tendencies. Using an autobiographical research-through-design approach, we built on Network Bending to design AttentionBender, which applies 2D transforms (rotation, scaling, translation, etc.) to cross-attention maps to modulate generation. We assess AttentionBender by visualizing 4,500+ video generations across prompts, operations, and layer targets. Our results suggest that cross-attention is highly entangled: targeted manipulations often resist clean, localized control, producing distributed distortions and glitch aesthetics over linear edits. AttentionBender contributes a tool that functions both as an Explainable AI style probe of transformer attention mechanisms, and as a creative technique for producing novel aesthetics beyond the model's learned representational space.
Guiding Generative Storytelling with Knowledge Graphs
May 30, 2025Large Language Models (LLMs) have shown great potential in automated story generation, but challenges remain in maintaining long-form coherence and providing users with intuitive and effective control. Retrieval-Augmented Generation (RAG) has proven effective in reducing hallucinations in text generation; however, the use of structured data to support generative storytelling remains underexplored. This paper investigates how knowledge graphs (KGs) can enhance LLM-based storytelling by improving narrative quality and enabling user-driven modifications. We propose a KG-assisted storytelling pipeline and evaluate its effectiveness through a user study with 15 participants. Participants created their own story prompts, generated stories, and edited knowledge graphs to shape their narratives. Through quantitative and qualitative analysis, our findings demonstrate that knowledge graphs significantly enhance story quality in action-oriented and structured narratives within our system settings. Additionally, editing the knowledge graph increases users' sense of control, making storytelling more engaging, interactive, and playful.
Coral Model Generation from Single Images for Virtual Reality Applications
Sep 04, 2024With the rapid development of VR technology, the demand for high-quality 3D models is increasing. Traditional methods struggle with efficiency and quality in large-scale customization. This paper introduces a deep-learning framework that generates high-precision 3D coral models from a single image. Using the Coral dataset, the framework extracts geometric and texture features, performs 3D reconstruction, and optimizes design and material blending. Advanced optimization and polygon count control ensure shape accuracy, detail retention, and flexible output for various complexities, catering to high-quality rendering and real-time interaction needs.The project incorporates Explainable AI (XAI) to transform AI-generated models into interactive "artworks," best viewed in VR and XR. This enhances model interpretability and human-machine collaboration. Real-time feedback in VR interactions displays information like coral species and habitat, enriching user experience. The generated models surpass traditional methods in detail, visual quality, and efficiency. This research offers an intelligent approach to 3D content creation for VR, lowering production barriers, and promoting widespread VR applications. Additionally, integrating XAI provides new insights into AI-generated visual content and advances research in 3D vision interpretability.
Active Divergence with Generative Deep Learning -- A Survey and Taxonomy
Jul 12, 2021
Generative deep learning systems offer powerful tools for artefact generation, given their ability to model distributions of data and generate high-fidelity results. In the context of computational creativity, however, a major shortcoming is that they are unable to explicitly diverge from the training data in creative ways and are limited to fitting the target data distribution. To address these limitations, there have been a growing number of approaches for optimising, hacking and rewriting these models in order to actively diverge from the training data. We present a taxonomy and comprehensive survey of the state of the art of active divergence techniques, highlighting the potential for computational creativity researchers to advance these methods and use deep generative models in truly creative systems.
Guru, Partner, or Pencil Sharpener? Understanding Designers' Attitudes Towards Intelligent Creativity Support Tools
Jul 09, 2020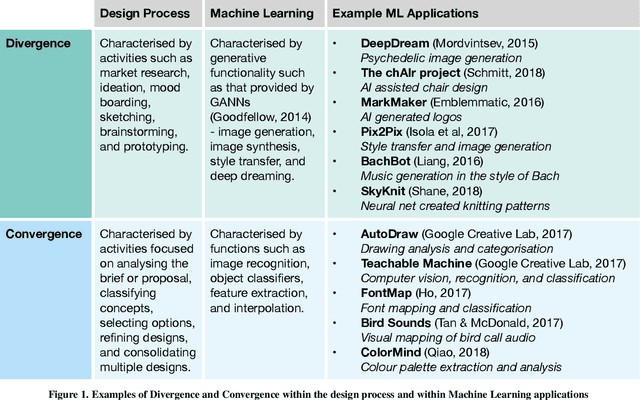
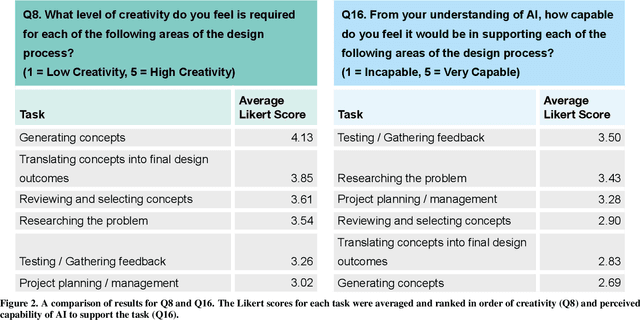
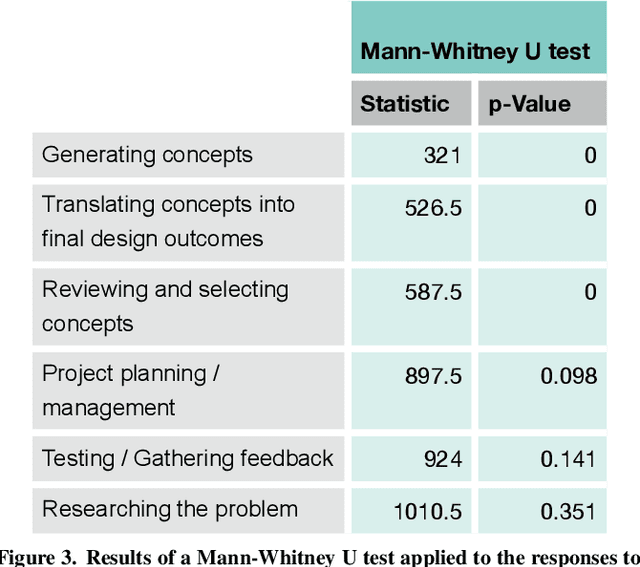
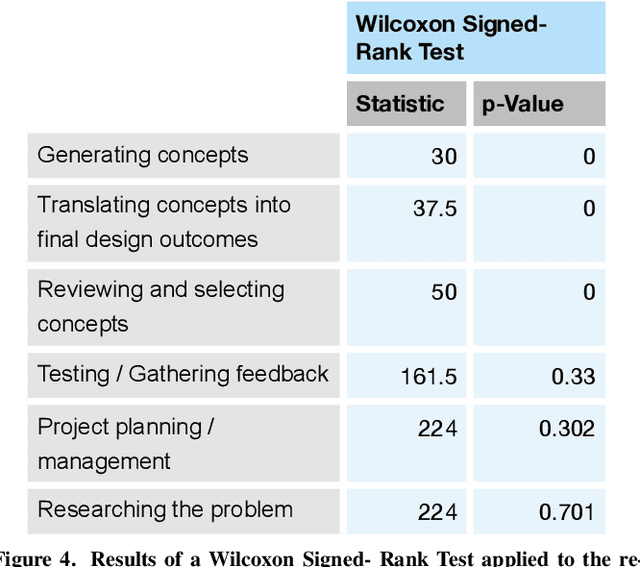
Creativity Support Tools (CST) aim to enhance human creativity, but the deeply personal and subjective nature of creativity makes the design of universal support tools challenging. Individuals develop personal approaches to creativity, particularly in the context of commercial design where signature styles and techniques are valuable commodities. Artificial Intelligence (AI) and Machine Learning (ML) techniques could provide a means of creating 'intelligent' CST which learn and adapt to personal styles of creativity. Identifying what kind of role such tools could play in the design process requires a better understanding of designers' attitudes towards working with AI, and their willingness to include it in their personal creative process. This paper details the results of a survey of professional designers which indicates a positive and pragmatic attitude towards collaborating with AI tools, and a particular opportunity for incorporating them in the research stages of a design project.
Network Bending: Manipulating The Inner Representations of Deep Generative Models
May 25, 2020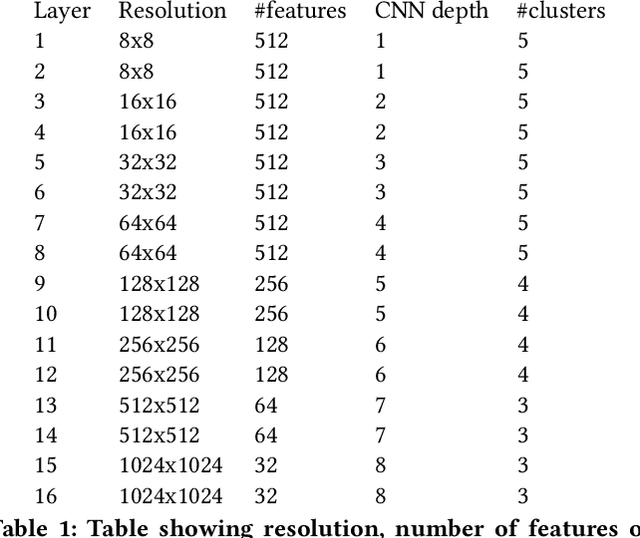
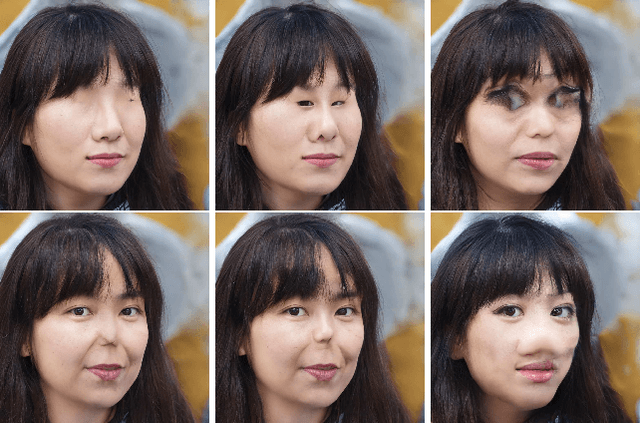


We introduce a new framework for interacting with and manipulating deep generative models that we call network bending. We present a comprehensive set of deterministic transformations that can be inserted as distinct layers into the computational graph of a trained generative neural network and applied during inference. In addition, we present a novel algorithm for clustering features based on their spatial activation maps. This allows features to be grouped together based on spatial similarity in an unsupervised fashion. This results in the meaningful manipulation of sets of features that correspond to the generation of a broad array of semantically significant aspects of the generated images. We demonstrate these transformations on the official pre-trained StyleGAN2 model trained on the FFHQ dataset. In doing so, we lay the groundwork for future interactive multimedia systems where the inner representation of deep generative models are manipulated for greater creative expression, whilst also increasing our understanding of how such "black-box systems" can be more meaningfully interpreted.
Learning to See: You Are What You See
Feb 28, 2020



The authors present a visual instrument developed as part of the creation of the artwork Learning to See. The artwork explores bias in artificial neural networks and provides mechanisms for the manipulation of specifically trained for real-world representations. The exploration of these representations acts as a metaphor for the process of developing a visual understanding and/or visual vocabulary of the world. These representations can be explored and manipulated in real time, and have been produced in such a way so as to reflect specific creative perspectives that call into question the relationship between how both artificial neural networks and humans may construct meaning.
* Presented as an Art Paper at SIGGRAPH 2019
Deep Meditations: Controlled navigation of latent space
Feb 27, 2020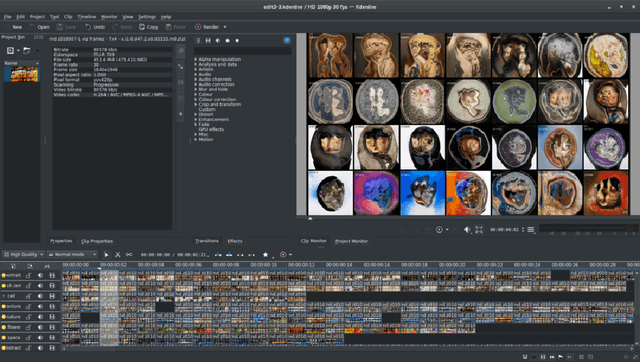



We introduce a method which allows users to creatively explore and navigate the vast latent spaces of deep generative models. Specifically, our method enables users to \textit{discover} and \textit{design} \textit{trajectories} in these high dimensional spaces, to construct stories, and produce time-based media such as videos---\textit{with meaningful control over narrative}. Our goal is to encourage and aid the use of deep generative models as a medium for creative expression and story telling with meaningful human control. Our method is analogous to traditional video production pipelines in that we use a conventional non-linear video editor with proxy clips, and conform with arrays of latent space vectors. Examples can be seen at \url{http://deepmeditations.ai}.
Amplifying The Uncanny
Feb 17, 2020



Deep neural networks have become remarkably good at producing realistic deepfakes, images of people that are (to the untrained eye) indistinguishable from real images. These are produced by algorithms that learn to distinguish between real and fake images and are optimised to generate samples that the system deems realistic. This paper, and the resulting series of artworks Being Foiled explore the aesthetic outcome of inverting this process and instead optimising the system to generate images that it sees as being fake. Maximising the unlikelihood of the data and in turn, amplifying the uncanny nature of these machine hallucinations.
Transforming the output of GANs by fine-tuning them with features from different datasets
Oct 06, 2019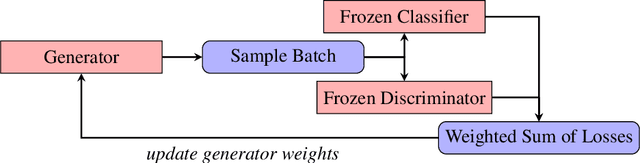



In this work we present a method for fine-tuning pre-trained GANs with features from different datasets, resulting in the transformation of the output distribution into a new distribution with novel characteristics. The weights of the generator are updated using the weighted sum of the losses from a cross-dataset classifier and the frozen weights of the pre-trained discriminator. We discuss details of the technical implementation and share some of the visual results from this training process.