 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Data Attribution for Text-to-Image Models
Nov 13, 2025Data attribution for text-to-image models aims to identify the training images that most significantly influenced a generated output. Existing attribution methods involve considerable computational resources for each query, making them impractical for real-world applications. We propose a novel approach for scalable and efficient data attribution. Our key idea is to distill a slow, unlearning-based attribution method to a feature embedding space for efficient retrieval of highly influential training images. During deployment, combined with efficient indexing and search methods, our method successfully finds highly influential images without running expensive attribution algorithms. We show extensive results on both medium-scale models trained on MSCOCO and large-scale Stable Diffusion models trained on LAION, demonstrating that our method can achieve better or competitive performance in a few seconds, faster than existing methods by 2,500x - 400,000x. Our work represents a meaningful step towards the large-scale application of data attribution methods on real-world models such as Stable Diffusion.
Identifying Prompted Artist Names from Generated Images
Jul 24, 2025A common and controversial use of text-to-image models is to generate pictures by explicitly naming artists, such as "in the style of Greg Rutkowski". We introduce a benchmark for prompted-artist recognition: predicting which artist names were invoked in the prompt from the image alone. The dataset contains 1.95M images covering 110 artists and spans four generalization settings: held-out artists, increasing prompt complexity, multiple-artist prompts, and different text-to-image models. We evaluate feature similarity baselines, contrastive style descriptors, data attribution methods, supervised classifiers, and few-shot prototypical networks. Generalization patterns vary: supervised and few-shot models excel on seen artists and complex prompts, whereas style descriptors transfer better when the artist's style is pronounced; multi-artist prompts remain the most challenging. Our benchmark reveals substantial headroom and provides a public testbed to advance the responsible moderation of text-to-image models. We release the dataset and benchmark to foster further research: https://graceduansu.github.io/IdentifyingPromptedArtists/
Data Attribution for Text-to-Image Models by Unlearning Synthesized Images
Jun 13, 2024The goal of data attribution for text-to-image models is to identify the training images that most influence the generation of a new image. We can define "influence" by saying that, for a given output, if a model is retrained from scratch without that output's most influential images, the model should then fail to generate that output image. Unfortunately, directly searching for these influential images is computationally infeasible, since it would require repeatedly retraining from scratch. We propose a new approach that efficiently identifies highly-influential images. Specifically, we simulate unlearning the synthesized image, proposing a method to increase the training loss on the output image, without catastrophic forgetting of other, unrelated concepts. Then, we find training images that are forgotten by proxy, identifying ones with significant loss deviations after the unlearning process, and label these as influential. We evaluate our method with a computationally intensive but "gold-standard" retraining from scratch and demonstrate our method's advantages over previous methods.
Segmentation-Based Parametric Painting
Nov 24, 2023We introduce a novel image-to-painting method that facilitates the creation of large-scale, high-fidelity paintings with human-like quality and stylistic variation. To process large images and gain control over the painting process, we introduce a segmentation-based painting process and a dynamic attention map approach inspired by human painting strategies, allowing optimization of brush strokes to proceed in batches over different image regions, thereby capturing both large-scale structure and fine details, while also allowing stylistic control over detail. Our optimized batch processing and patch-based loss framework enable efficient handling of large canvases, ensuring our painted outputs are both aesthetically compelling and functionally superior as compared to previous methods, as confirmed by rigorous evaluations. Code available at: https://github.com/manuelladron/semantic\_based\_painting.git
Art and the science of generative AI: A deeper dive
Jun 07, 2023A new class of tools, colloquially called generative AI, can produce high-quality artistic media for visual arts, concept art, music, fiction, literature, video, and animation. The generative capabilities of these tools are likely to fundamentally alter the creative processes by which creators formulate ideas and put them into production. As creativity is reimagined, so too may be many sectors of society. Understanding the impact of generative AI - and making policy decisions around it - requires new interdisciplinary scientific inquiry into culture, economics, law, algorithms, and the interaction of technology and creativity. We argue that generative AI is not the harbinger of art's demise, but rather is a new medium with its own distinct affordances. In this vein, we consider the impacts of this new medium on creators across four themes: aesthetics and culture, legal questions of ownership and credit, the future of creative work, and impacts on the contemporary media ecosystem. Across these themes, we highlight key research questions and directions to inform policy and beneficial uses of the technology.
Towards Better User Studies in Computer Graphics and Vision
Jun 23, 2022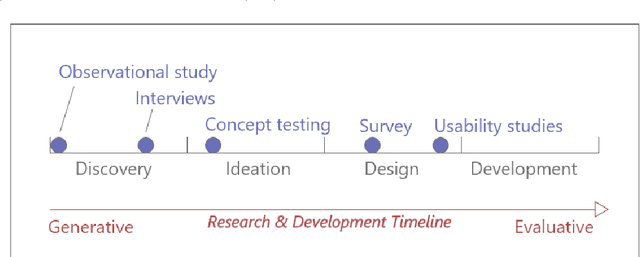
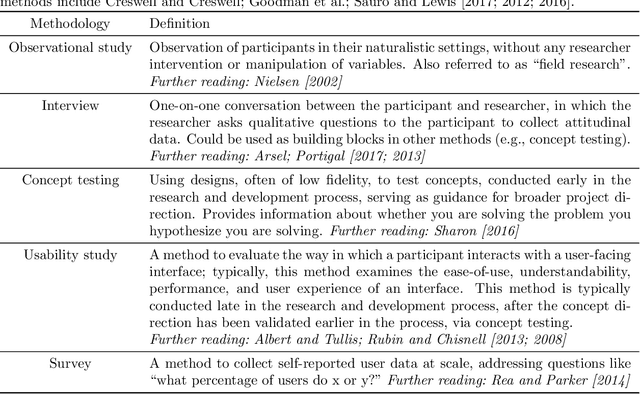
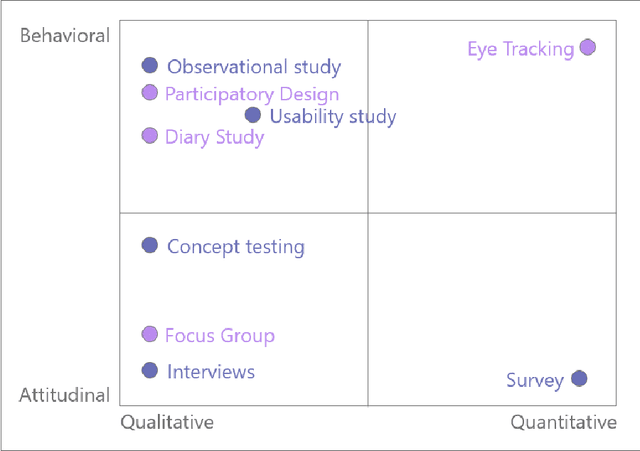
Online crowdsourcing platforms make it easy to perform evaluations of algorithm outputs with surveys that ask questions like "which image is better, A or B?") The proliferation of these "user studies" in vision and graphics research papers has led to an increase of hastily conducted studies that are sloppy and uninformative at best, and potentially harmful and misleading. We argue that more attention needs to be paid to both the design and reporting of user studies in computer vision and graphics papers. In an attempt to improve practitioners' knowledge and increase the trustworthiness and replicability of user studies, we provide an overview of methodologies from user experience research (UXR), human-computer interaction (HCI), and related fields. We discuss foundational user research methods (e.g., needfinding) that are presently underutilized in computer vision and graphics research, but can provide valuable guidance for research projects. We provide further pointers to the literature for readers interested in exploring other UXR methodologies. Finally, we describe broader open issues and recommendations for the research community. We encourage authors and reviewers alike to recognize that not every research contribution requires a user study, and that having no study at all is better than having a carelessly conducted one.
Toward Modeling Creative Processes for Algorithmic Painting
May 03, 2022



This paper proposes a framework for computational modeling of artistic painting algorithms, inspired by human creative practices. Based on examples from expert artists and from the author's own experience, the paper argues that creative processes often involve two important components: vague, high-level goals (e.g., "make a good painting"), and exploratory processes for discovering new ideas. This paper then sketches out possible computational mechanisms for imitating those elements of the painting process, including underspecified loss functions and iterative painting procedures with explicit task decompositions.
Neural Strokes: Stylized Line Drawing of 3D Shapes
Oct 08, 2021
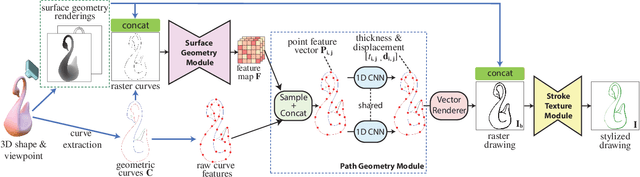


This paper introduces a model for producing stylized line drawings from 3D shapes. The model takes a 3D shape and a viewpoint as input, and outputs a drawing with textured strokes, with variations in stroke thickness, deformation, and color learned from an artist's style. The model is fully differentiable. We train its parameters from a single training drawing of another 3D shape. We show that, in contrast to previous image-based methods, the use of a geometric representation of 3D shape and 2D strokes allows the model to transfer important aspects of shape and texture style while preserving contours. Our method outputs the resulting drawing in a vector representation, enabling richer downstream analysis or editing in interactive applications.
Contact-Aware Retargeting of Skinned Motion
Sep 15, 2021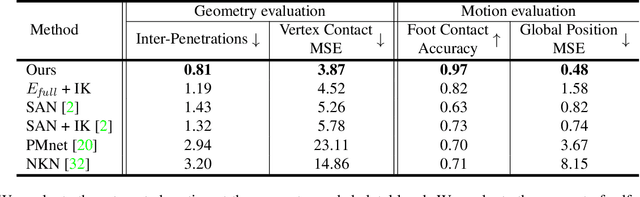
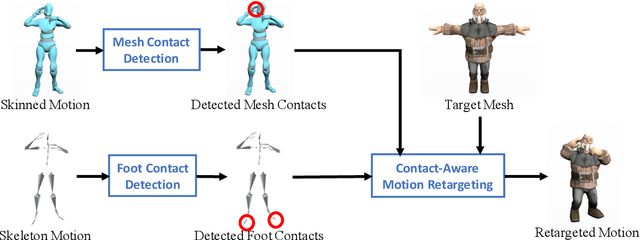

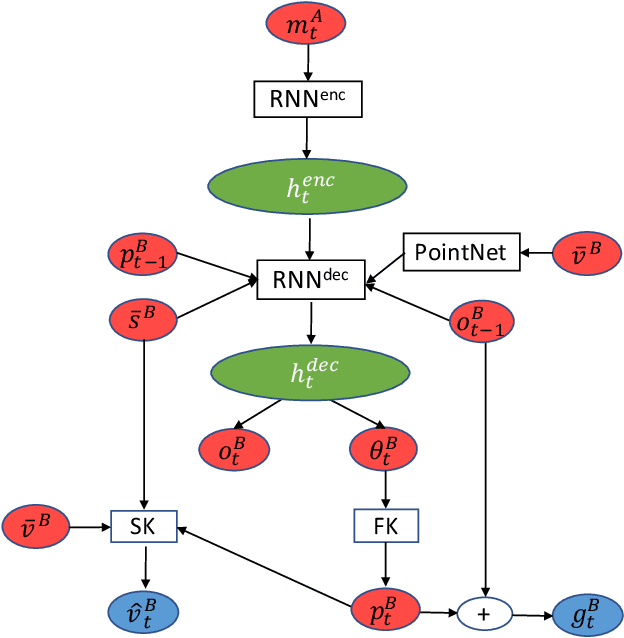
This paper introduces a motion retargeting method that preserves self-contacts and prevents interpenetration. Self-contacts, such as when hands touch each other or the torso or the head, are important attributes of human body language and dynamics, yet existing methods do not model or preserve these contacts. Likewise, interpenetration, such as a hand passing into the torso, are a typical artifact of motion estimation methods. The input to our method is a human motion sequence and a target skeleton and character geometry. The method identifies self-contacts and ground contacts in the input motion, and optimizes the motion to apply to the output skeleton, while preserving these contacts and reducing interpenetration. We introduce a novel geometry-conditioned recurrent network with an encoder-space optimization strategy that achieves efficient retargeting while satisfying contact constraints. In experiments, our results quantitatively outperform previous methods and we conduct a user study where our retargeted motions are rated as higher-quality than those produced by recent works. We also show our method generalizes to motion estimated from human videos where we improve over previous works that produce noticeable interpenetration.
HuMoR: 3D Human Motion Model for Robust Pose Estimation
May 10, 2021
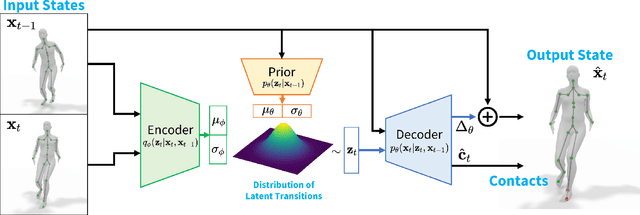


We introduce HuMoR: a 3D Human Motion Model for Robust Estimation of temporal pose and shape. Though substantial progress has been made in estimating 3D human motion and shape from dynamic observations, recovering plausible pose sequences in the presence of noise and occlusions remains a challenge. For this purpose, we propose an expressive generative model in the form of a conditional variational autoencoder, which learns a distribution of the change in pose at each step of a motion sequence. Furthermore, we introduce a flexible optimization-based approach that leverages HuMoR as a motion prior to robustly estimate plausible pose and shape from ambiguous observations. Through extensive evaluations, we demonstrate that our model generalizes to diverse motions and body shapes after training on a large motion capture dataset, and enables motion reconstruction from multiple input modalities including 3D keypoints and RGB(-D) videos.