 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRealistic Saliency Guided Image Enhancement
Jun 09, 2023



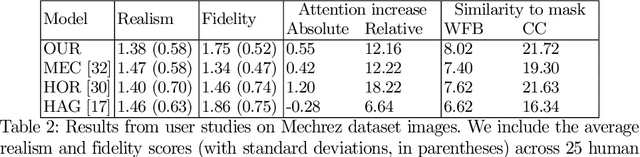
Common editing operations performed by professional photographers include the cleanup operations: de-emphasizing distracting elements and enhancing subjects. These edits are challenging, requiring a delicate balance between manipulating the viewer's attention while maintaining photo realism. While recent approaches can boast successful examples of attention attenuation or amplification, most of them also suffer from frequent unrealistic edits. We propose a realism loss for saliency-guided image enhancement to maintain high realism across varying image types, while attenuating distractors and amplifying objects of interest. Evaluations with professional photographers confirm that we achieve the dual objective of realism and effectiveness, and outperform the recent approaches on their own datasets, while requiring a smaller memory footprint and runtime. We thus offer a viable solution for automating image enhancement and photo cleanup operations.
* For more info visit http://yaksoy.github.io/realisticEditing/
Towards Better User Studies in Computer Graphics and Vision
Jun 23, 2022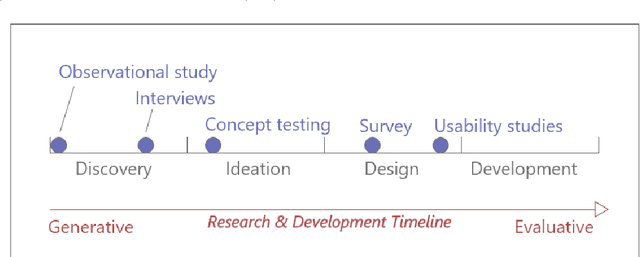
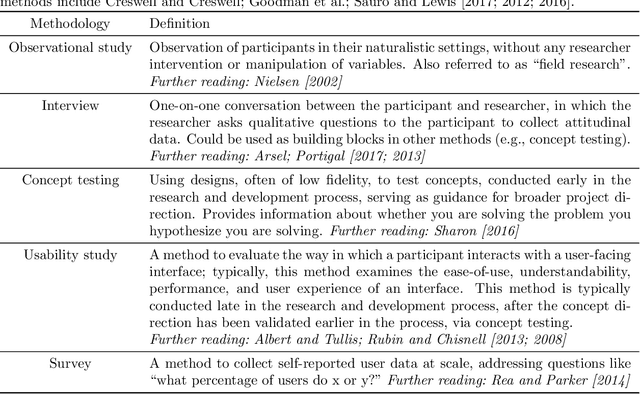
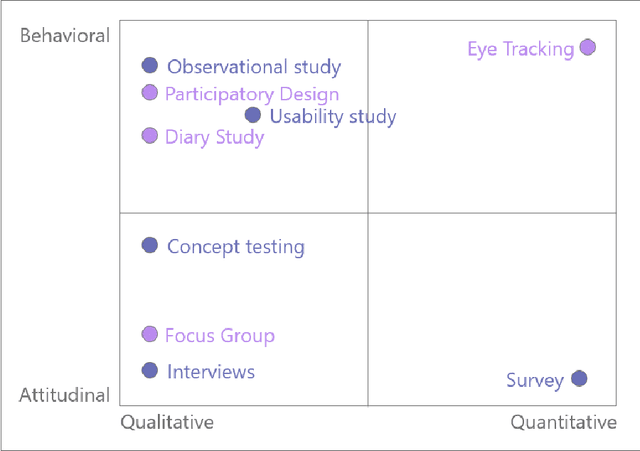
Online crowdsourcing platforms make it easy to perform evaluations of algorithm outputs with surveys that ask questions like "which image is better, A or B?") The proliferation of these "user studies" in vision and graphics research papers has led to an increase of hastily conducted studies that are sloppy and uninformative at best, and potentially harmful and misleading. We argue that more attention needs to be paid to both the design and reporting of user studies in computer vision and graphics papers. In an attempt to improve practitioners' knowledge and increase the trustworthiness and replicability of user studies, we provide an overview of methodologies from user experience research (UXR), human-computer interaction (HCI), and related fields. We discuss foundational user research methods (e.g., needfinding) that are presently underutilized in computer vision and graphics research, but can provide valuable guidance for research projects. We provide further pointers to the literature for readers interested in exploring other UXR methodologies. Finally, we describe broader open issues and recommendations for the research community. We encourage authors and reviewers alike to recognize that not every research contribution requires a user study, and that having no study at all is better than having a carelessly conducted one.
Memorability: An image-computable measure of information utility
Apr 01, 2021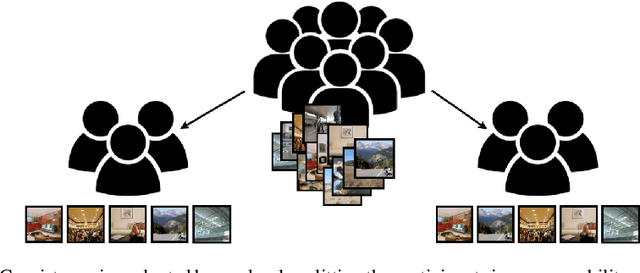
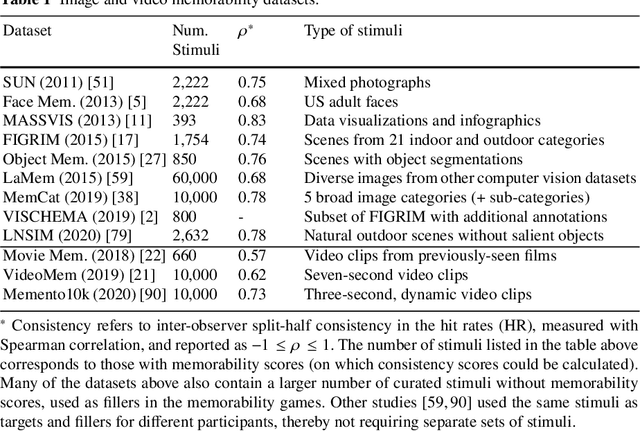

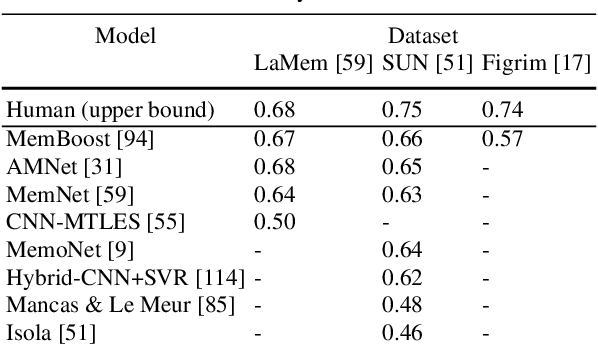
The pixels in an image, and the objects, scenes, and actions that they compose, determine whether an image will be memorable or forgettable. While memorability varies by image, it is largely independent of an individual observer. Observer independence is what makes memorability an image-computable measure of information, and eligible for automatic prediction. In this chapter, we zoom into memorability with a computational lens, detailing the state-of-the-art algorithms that accurately predict image memorability relative to human behavioral data, using image features at different scales from raw pixels to semantic labels. We discuss the design of algorithms and visualizations for face, object, and scene memorability, as well as algorithms that generalize beyond static scenes to actions and videos. We cover the state-of-the-art deep learning approaches that are the current front runners in the memorability prediction space. Beyond prediction, we show how recent A.I. approaches can be used to create and modify visual memorability. Finally, we preview the computational applications that memorability can power, from filtering visual streams to enhancing augmented reality interfaces.
Toward Quantifying Ambiguities in Artistic Images
Aug 21, 2020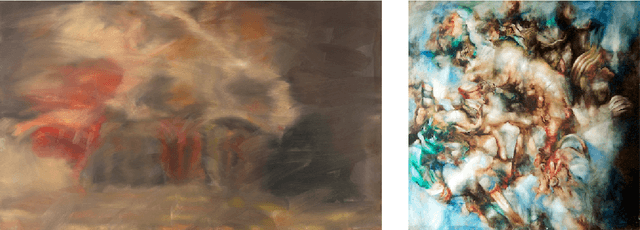
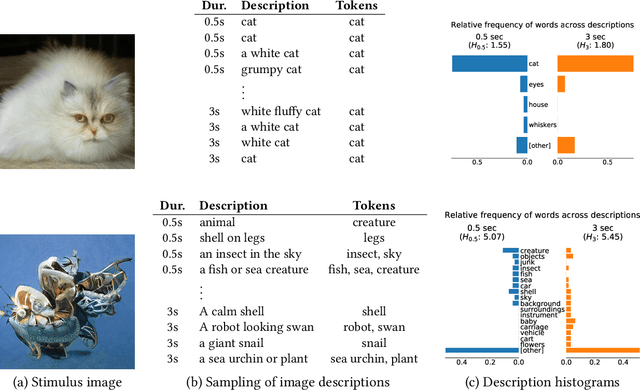


It has long been hypothesized that perceptual ambiguities play an important role in aesthetic experience: a work with some ambiguity engages a viewer more than one that does not. However, current frameworks for testing this theory are limited by the availability of stimuli and data collection methods. This paper presents an approach to measuring the perceptual ambiguity of a collection of images. Crowdworkers are asked to describe image content, after different viewing durations. Experiments are performed using images created with Generative Adversarial Networks, using the Artbreeder website. We show that text processing of viewer responses can provide a fine-grained way to measure and describe image ambiguities.
Look here! A parametric learning based approach to redirect visual attention
Aug 12, 2020

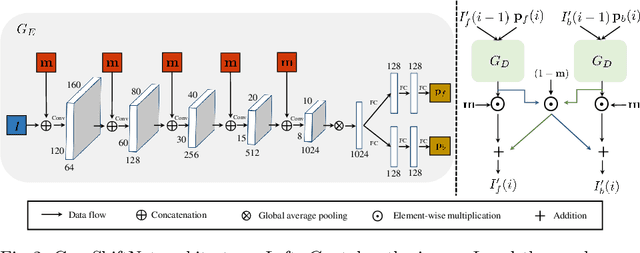
Across photography, marketing, and website design, being able to direct the viewer's attention is a powerful tool. Motivated by professional workflows, we introduce an automatic method to make an image region more attention-capturing via subtle image edits that maintain realism and fidelity to the original. From an input image and a user-provided mask, our GazeShiftNet model predicts a distinct set of global parametric transformations to be applied to the foreground and background image regions separately. We present the results of quantitative and qualitative experiments that demonstrate improvements over prior state-of-the-art. In contrast to existing attention shifting algorithms, our global parametric approach better preserves image semantics and avoids typical generative artifacts. Our edits enable inference at interactive rates on any image size, and easily generalize to videos. Extensions of our model allow for multi-style edits and the ability to both increase and attenuate attention in an image region. Furthermore, users can customize the edited images by dialing the edits up or down via interpolations in parameter space. This paper presents a practical tool that can simplify future image editing pipelines.
Predicting Visual Importance Across Graphic Design Types
Aug 07, 2020
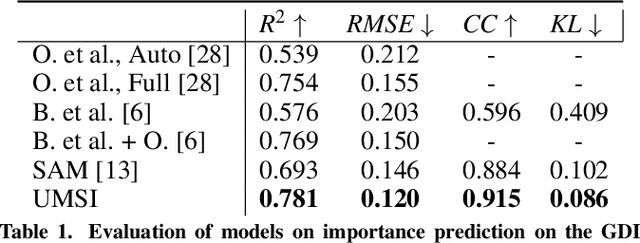
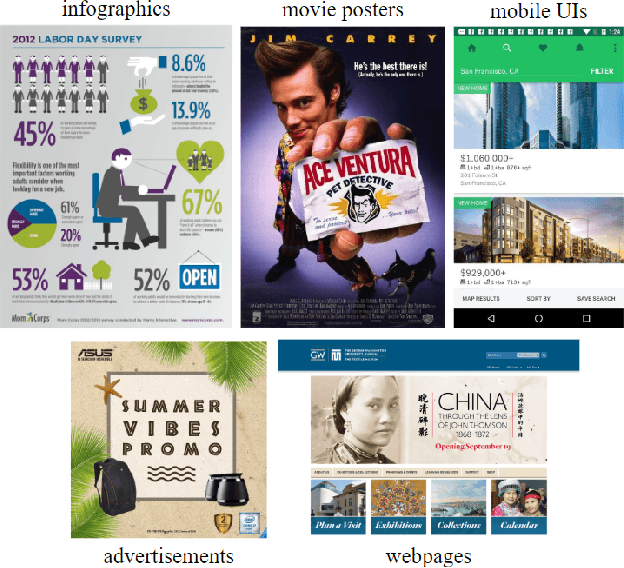
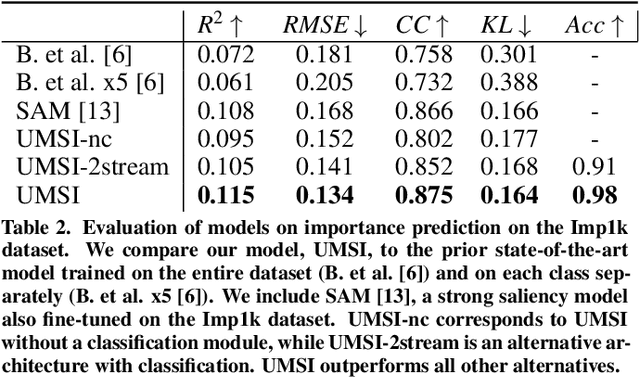
This paper introduces a Unified Model of Saliency and Importance (UMSI), which learns to predict visual importance in input graphic designs, and saliency in natural images, along with a new dataset and applications. Previous methods for predicting saliency or visual importance are trained individually on specialized datasets, making them limited in application and leading to poor generalization on novel image classes, while requiring a user to know which model to apply to which input. UMSI is a deep learning-based model simultaneously trained on images from different design classes, including posters, infographics, mobile UIs, as well as natural images, and includes an automatic classification module to classify the input. This allows the model to work more effectively without requiring a user to label the input. We also introduce Imp1k, a new dataset of designs annotated with importance information. We demonstrate two new design interfaces that use importance prediction, including a tool for adjusting the relative importance of design elements, and a tool for reflowing designs to new aspect ratios while preserving visual importance. The model, code, and importance dataset are available at https://predimportance.mit.edu .
Bottom-up Attention, Models of
Oct 11, 2018



In this review, we examine the recent progress in saliency prediction and proposed several avenues for future research. In spite of tremendous efforts and huge progress, there is still room for improvement in terms finer-grained analysis of deep saliency models, evaluation measures, datasets, annotation methods, cognitive studies, and new applications. This chapter will appear in Encyclopedia of Computational Neuroscience.
Synthetically Trained Icon Proposals for Parsing and Summarizing Infographics
Jul 27, 2018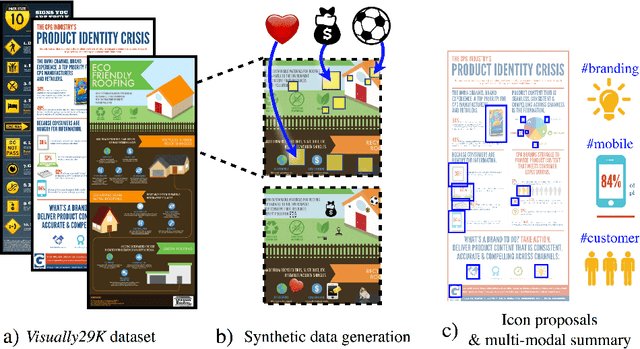
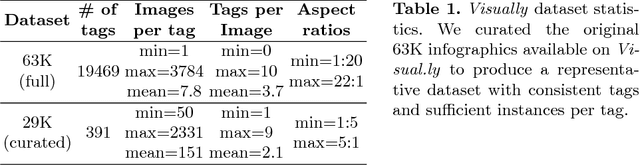

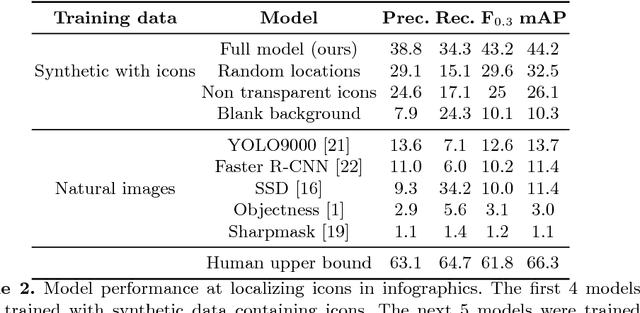
Widely used in news, business, and educational media, infographics are handcrafted to effectively communicate messages about complex and often abstract topics including `ways to conserve the environment' and `understanding the financial crisis'. Composed of stylistically and semantically diverse visual and textual elements, infographics pose new challenges for computer vision. While automatic text extraction works well on infographics, computer vision approaches trained on natural images fail to identify the stand-alone visual elements in infographics, or `icons'. To bridge this representation gap, we propose a synthetic data generation strategy: we augment background patches in infographics from our Visually29K dataset with Internet-scraped icons which we use as training data for an icon proposal mechanism. On a test set of 1K annotated infographics, icons are located with 38% precision and 34% recall (the best model trained with natural images achieves 14% precision and 7% recall). Combining our icon proposals with icon classification and text extraction, we present a multi-modal summarization application. Our application takes an infographic as input and automatically produces text tags and visual hashtags that are textually and visually representative of the infographic's topics respectively.
Understanding Infographics through Textual and Visual Tag Prediction
Sep 26, 2017



We introduce the problem of visual hashtag discovery for infographics: extracting visual elements from an infographic that are diagnostic of its topic. Given an infographic as input, our computational approach automatically outputs textual and visual elements predicted to be representative of the infographic content. Concretely, from a curated dataset of 29K large infographic images sampled across 26 categories and 391 tags, we present an automated two step approach. First, we extract the text from an infographic and use it to predict text tags indicative of the infographic content. And second, we use these predicted text tags as a supervisory signal to localize the most diagnostic visual elements from within the infographic i.e. visual hashtags. We report performances on a categorization and multi-label tag prediction problem and compare our proposed visual hashtags to human annotations.
BubbleView: an interface for crowdsourcing image importance maps and tracking visual attention
Aug 09, 2017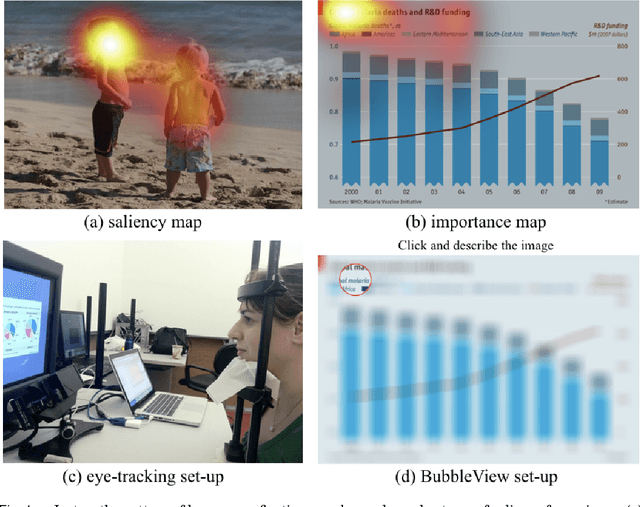
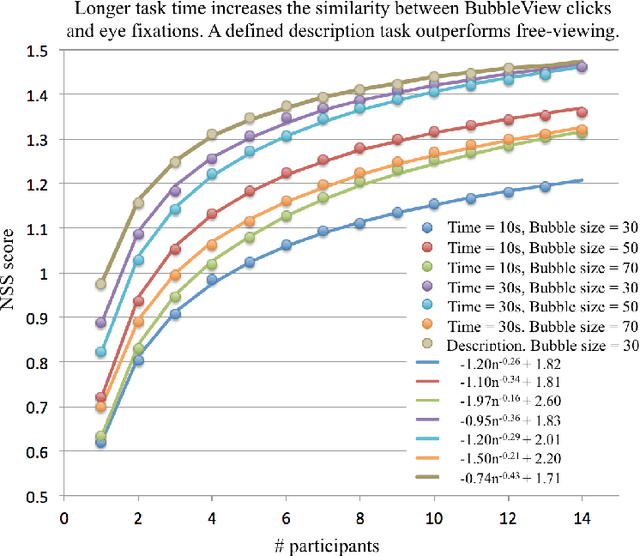

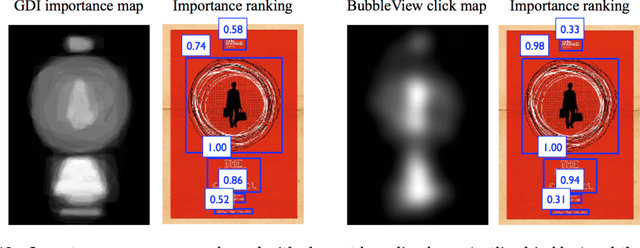
In this paper, we present BubbleView, an alternative methodology for eye tracking using discrete mouse clicks to measure which information people consciously choose to examine. BubbleView is a mouse-contingent, moving-window interface in which participants are presented with a series of blurred images and click to reveal "bubbles" - small, circular areas of the image at original resolution, similar to having a confined area of focus like the eye fovea. Across 10 experiments with 28 different parameter combinations, we evaluated BubbleView on a variety of image types: information visualizations, natural images, static webpages, and graphic designs, and compared the clicks to eye fixations collected with eye-trackers in controlled lab settings. We found that BubbleView clicks can both (i) successfully approximate eye fixations on different images, and (ii) be used to rank image and design elements by importance. BubbleView is designed to collect clicks on static images, and works best for defined tasks such as describing the content of an information visualization or measuring image importance. BubbleView data is cleaner and more consistent than related methodologies that use continuous mouse movements. Our analyses validate the use of mouse-contingent, moving-window methodologies as approximating eye fixations for different image and task types.