 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemorability: An image-computable measure of information utility
Apr 01, 2021
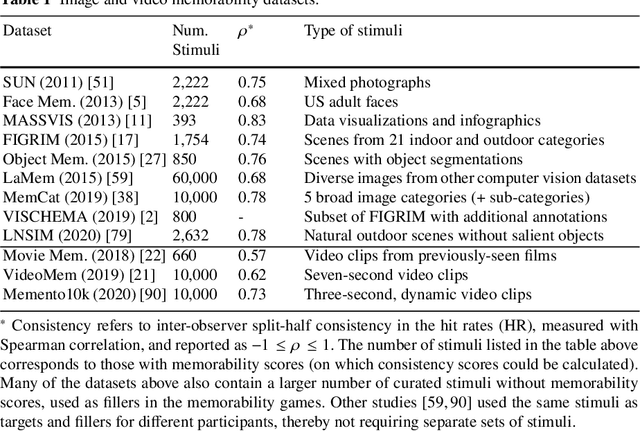

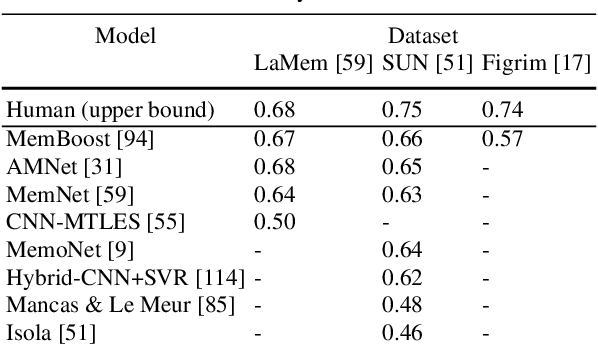
The pixels in an image, and the objects, scenes, and actions that they compose, determine whether an image will be memorable or forgettable. While memorability varies by image, it is largely independent of an individual observer. Observer independence is what makes memorability an image-computable measure of information, and eligible for automatic prediction. In this chapter, we zoom into memorability with a computational lens, detailing the state-of-the-art algorithms that accurately predict image memorability relative to human behavioral data, using image features at different scales from raw pixels to semantic labels. We discuss the design of algorithms and visualizations for face, object, and scene memorability, as well as algorithms that generalize beyond static scenes to actions and videos. We cover the state-of-the-art deep learning approaches that are the current front runners in the memorability prediction space. Beyond prediction, we show how recent A.I. approaches can be used to create and modify visual memorability. Finally, we preview the computational applications that memorability can power, from filtering visual streams to enhancing augmented reality interfaces.
Multimodal Memorability: Modeling Effects of Semantics and Decay on Video Memorability
Sep 05, 2020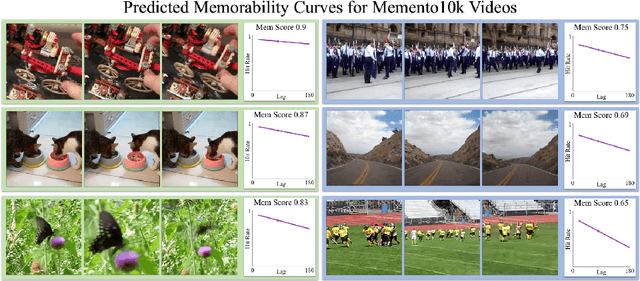
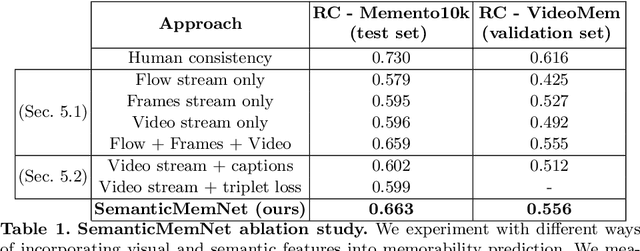


A key capability of an intelligent system is deciding when events from past experience must be remembered and when they can be forgotten. Towards this goal, we develop a predictive model of human visual event memory and how those memories decay over time. We introduce Memento10k, a new, dynamic video memorability dataset containing human annotations at different viewing delays. Based on our findings we propose a new mathematical formulation of memorability decay, resulting in a model that is able to produce the first quantitative estimation of how a video decays in memory over time. In contrast with previous work, our model can predict the probability that a video will be remembered at an arbitrary delay. Importantly, our approach combines visual and semantic information (in the form of textual captions) to fully represent the meaning of events. Our experiments on two video memorability benchmarks, including Memento10k, show that our model significantly improves upon the best prior approach (by 12% on average).