 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepfake Caricatures: Amplifying attention to artifacts increases deepfake detection by humans and machines
Jun 02, 2022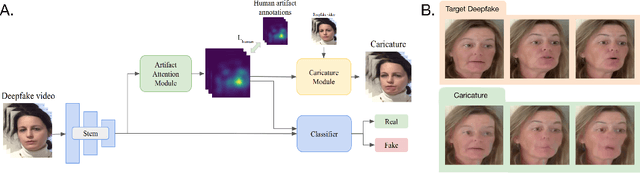
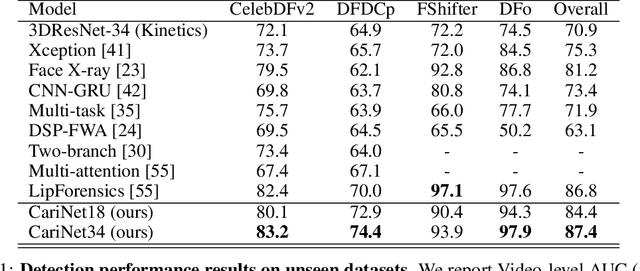

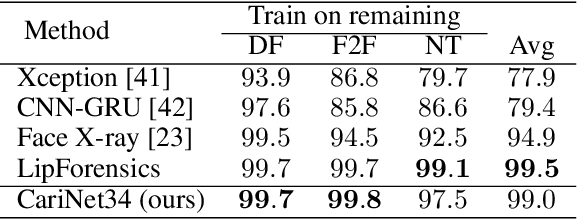
Deepfakes pose a serious threat to our digital society by fueling the spread of misinformation. It is essential to develop techniques that both detect them, and effectively alert the human user to their presence. Here, we introduce a novel deepfake detection framework that meets both of these needs. Our approach learns to generate attention maps of video artifacts, semi-supervised on human annotations. These maps make two contributions. First, they improve the accuracy and generalizability of a deepfake classifier, demonstrated across several deepfake detection datasets. Second, they allow us to generate an intuitive signal for the human user, in the form of "Deepfake Caricatures": transformations of the original deepfake video where attended artifacts are exacerbated to improve human recognition. Our approach, based on a mixture of human and artificial supervision, aims to further the development of countermeasures against fake visual content, and grants humans the ability to make their own judgment when presented with dubious visual media.
Multimodal Memorability: Modeling Effects of Semantics and Decay on Video Memorability
Sep 05, 2020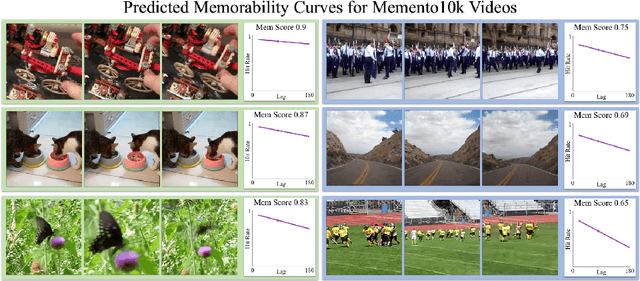
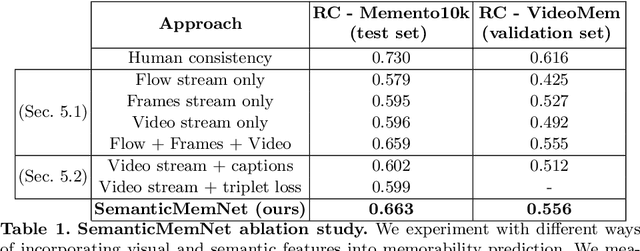


A key capability of an intelligent system is deciding when events from past experience must be remembered and when they can be forgotten. Towards this goal, we develop a predictive model of human visual event memory and how those memories decay over time. We introduce Memento10k, a new, dynamic video memorability dataset containing human annotations at different viewing delays. Based on our findings we propose a new mathematical formulation of memorability decay, resulting in a model that is able to produce the first quantitative estimation of how a video decays in memory over time. In contrast with previous work, our model can predict the probability that a video will be remembered at an arbitrary delay. Importantly, our approach combines visual and semantic information (in the form of textual captions) to fully represent the meaning of events. Our experiments on two video memorability benchmarks, including Memento10k, show that our model significantly improves upon the best prior approach (by 12% on average).
We Have So Much In Common: Modeling Semantic Relational Set Abstractions in Videos
Aug 12, 2020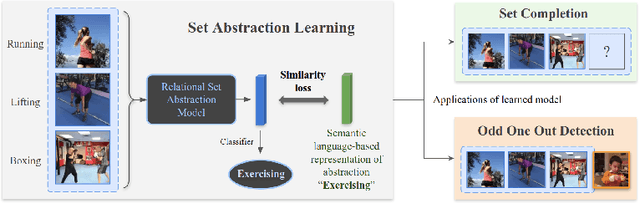
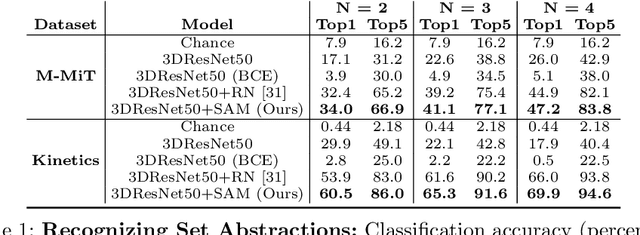

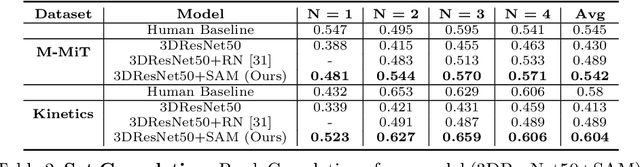
Identifying common patterns among events is a key ability in human and machine perception, as it underlies intelligent decision making. We propose an approach for learning semantic relational set abstractions on videos, inspired by human learning. We combine visual features with natural language supervision to generate high-level representations of similarities across a set of videos. This allows our model to perform cognitive tasks such as set abstraction (which general concept is in common among a set of videos?), set completion (which new video goes well with the set?), and odd one out detection (which video does not belong to the set?). Experiments on two video benchmarks, Kinetics and Multi-Moments in Time, show that robust and versatile representations emerge when learning to recognize commonalities among sets. We compare our model to several baseline algorithms and show that significant improvements result from explicitly learning relational abstractions with semantic supervision.