 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSceneCrafter: Controllable Multi-View Driving Scene Editing
Jun 24, 2025Simulation is crucial for developing and evaluating autonomous vehicle (AV) systems. Recent literature builds on a new generation of generative models to synthesize highly realistic images for full-stack simulation. However, purely synthetically generated scenes are not grounded in reality and have difficulty in inspiring confidence in the relevance of its outcomes. Editing models, on the other hand, leverage source scenes from real driving logs, and enable the simulation of different traffic layouts, behaviors, and operating conditions such as weather and time of day. While image editing is an established topic in computer vision, it presents fresh sets of challenges in driving simulation: (1) the need for cross-camera 3D consistency, (2) learning ``empty street" priors from driving data with foreground occlusions, and (3) obtaining paired image tuples of varied editing conditions while preserving consistent layout and geometry. To address these challenges, we propose SceneCrafter, a versatile editor for realistic 3D-consistent manipulation of driving scenes captured from multiple cameras. We build on recent advancements in multi-view diffusion models, using a fully controllable framework that scales seamlessly to multi-modality conditions like weather, time of day, agent boxes and high-definition maps. To generate paired data for supervising the editing model, we propose a novel framework on top of Prompt-to-Prompt to generate geometrically consistent synthetic paired data with global edits. We also introduce an alpha-blending framework to synthesize data with local edits, leveraging a model trained on empty street priors through novel masked training and multi-view repaint paradigm. SceneCrafter demonstrates powerful editing capabilities and achieves state-of-the-art realism, controllability, 3D consistency, and scene editing quality compared to existing baselines.
Instance Segmentation with Cross-Modal Consistency
Oct 14, 2022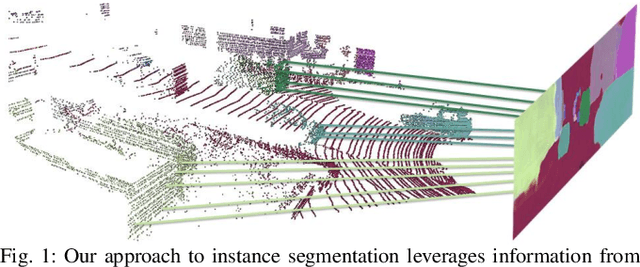
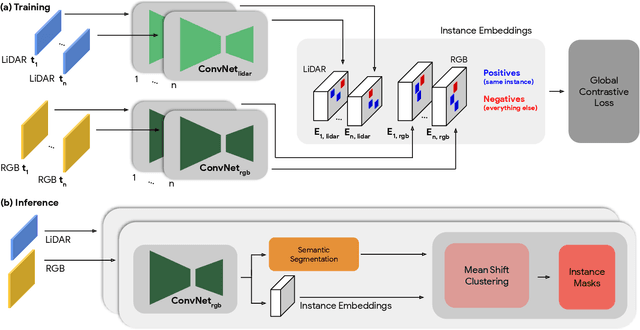

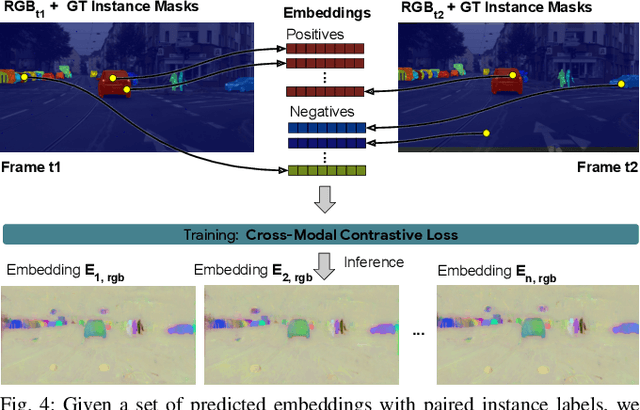
Segmenting object instances is a key task in machine perception, with safety-critical applications in robotics and autonomous driving. We introduce a novel approach to instance segmentation that jointly leverages measurements from multiple sensor modalities, such as cameras and LiDAR. Our method learns to predict embeddings for each pixel or point that give rise to a dense segmentation of the scene. Specifically, our technique applies contrastive learning to points in the scene both across sensor modalities and the temporal domain. We demonstrate that this formulation encourages the models to learn embeddings that are invariant to viewpoint variations and consistent across sensor modalities. We further demonstrate that the embeddings are stable over time as objects move around the scene. This not only provides stable instance masks, but can also provide valuable signals to downstream tasks, such as object tracking. We evaluate our method on the Cityscapes and KITTI-360 datasets. We further conduct a number of ablation studies, demonstrating benefits when applying additional inputs for the contrastive loss.
LET-3D-AP: Longitudinal Error Tolerant 3D Average Precision for Camera-Only 3D Detection
Jun 15, 2022



The popular object detection metric 3D Average Precision (3D AP) relies on the intersection over union between predicted bounding boxes and ground truth bounding boxes. However, depth estimation based on cameras has limited accuracy, which may cause otherwise reasonable predictions that suffer from such longitudinal localization errors to be treated as false positives and false negatives. We therefore propose variants of the popular 3D AP metric that are designed to be more permissive with respect to depth estimation errors. Specifically, our novel longitudinal error tolerant metrics, LET-3D-AP and LET-3D-APL, allow longitudinal localization errors of the predicted bounding boxes up to a given tolerance. The proposed metrics have been used in the Waymo Open Dataset 3D Camera-Only Detection Challenge. We believe that they will facilitate advances in the field of camera-only 3D detection by providing more informative performance signals.
Block-NeRF: Scalable Large Scene Neural View Synthesis
Feb 10, 2022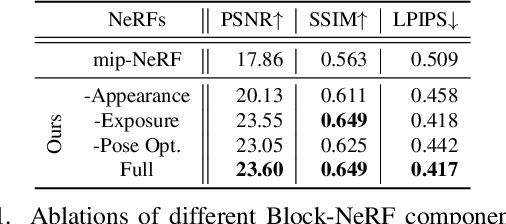



We present Block-NeRF, a variant of Neural Radiance Fields that can represent large-scale environments. Specifically, we demonstrate that when scaling NeRF to render city-scale scenes spanning multiple blocks, it is vital to decompose the scene into individually trained NeRFs. This decomposition decouples rendering time from scene size, enables rendering to scale to arbitrarily large environments, and allows per-block updates of the environment. We adopt several architectural changes to make NeRF robust to data captured over months under different environmental conditions. We add appearance embeddings, learned pose refinement, and controllable exposure to each individual NeRF, and introduce a procedure for aligning appearance between adjacent NeRFs so that they can be seamlessly combined. We build a grid of Block-NeRFs from 2.8 million images to create the largest neural scene representation to date, capable of rendering an entire neighborhood of San Francisco.
GradTail: Learning Long-Tailed Data Using Gradient-based Sample Weighting
Jan 19, 2022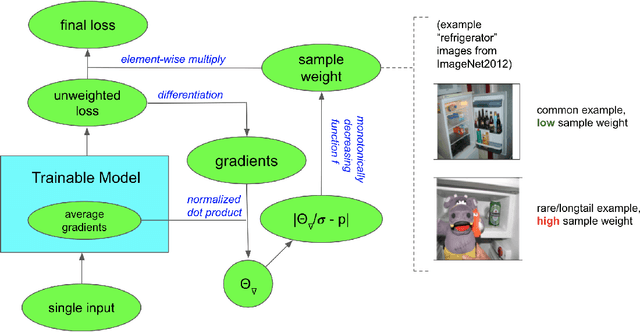
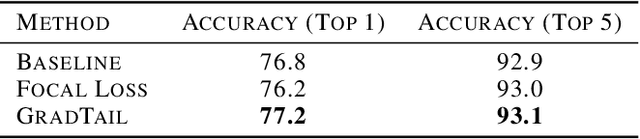
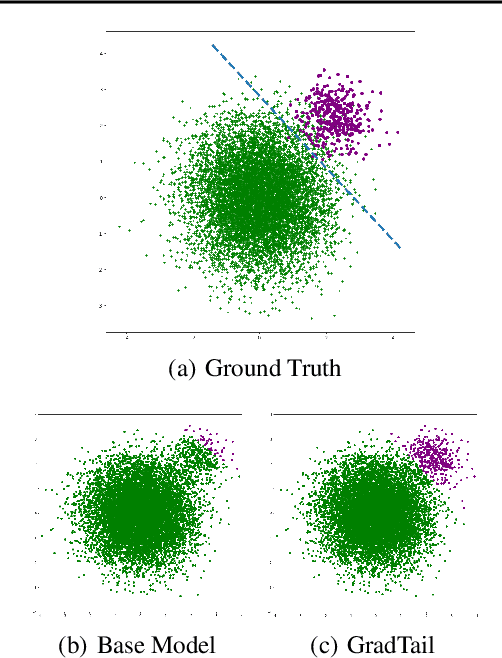

We propose GradTail, an algorithm that uses gradients to improve model performance on the fly in the face of long-tailed training data distributions. Unlike conventional long-tail classifiers which operate on converged - and possibly overfit - models, we demonstrate that an approach based on gradient dot product agreement can isolate long-tailed data early on during model training and improve performance by dynamically picking higher sample weights for that data. We show that such upweighting leads to model improvements for both classification and regression models, the latter of which are relatively unexplored in the long-tail literature, and that the long-tail examples found by gradient alignment are consistent with our semantic expectations.
4D-Net for Learned Multi-Modal Alignment
Sep 02, 2021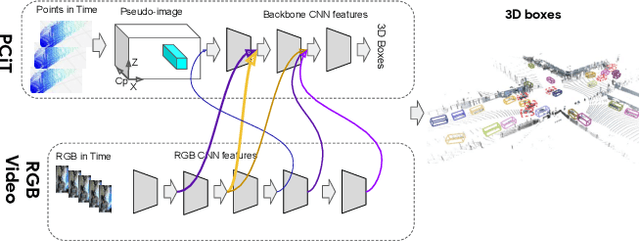
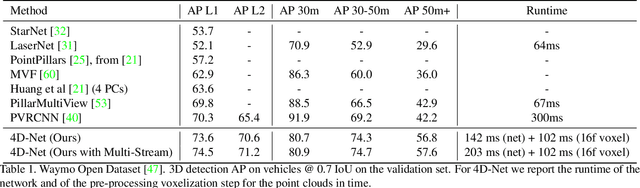
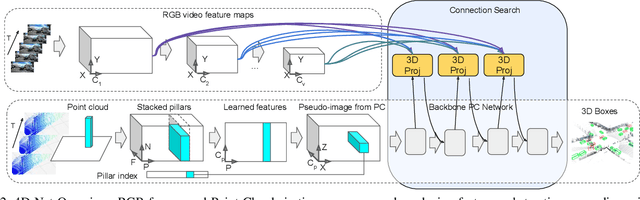
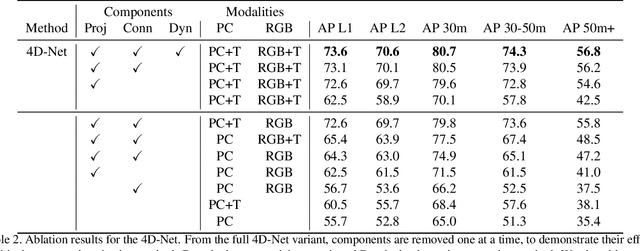
We present 4D-Net, a 3D object detection approach, which utilizes 3D Point Cloud and RGB sensing information, both in time. We are able to incorporate the 4D information by performing a novel dynamic connection learning across various feature representations and levels of abstraction, as well as by observing geometric constraints. Our approach outperforms the state-of-the-art and strong baselines on the Waymo Open Dataset. 4D-Net is better able to use motion cues and dense image information to detect distant objects more successfully.
Unsupervised Monocular Depth Learning in Dynamic Scenes
Nov 07, 2020


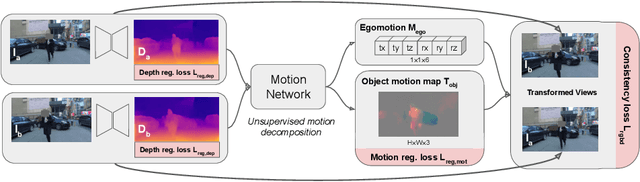
We present a method for jointly training the estimation of depth, ego-motion, and a dense 3D translation field of objects relative to the scene, with monocular photometric consistency being the sole source of supervision. We show that this apparently heavily underdetermined problem can be regularized by imposing the following prior knowledge about 3D translation fields: they are sparse, since most of the scene is static, and they tend to be constant for rigid moving objects. We show that this regularization alone is sufficient to train monocular depth prediction models that exceed the accuracy achieved in prior work for dynamic scenes, including methods that require semantic input. Code is at https://github.com/google-research/google-research/tree/master/depth_and_motion_learning .
Multimodal Memorability: Modeling Effects of Semantics and Decay on Video Memorability
Sep 05, 2020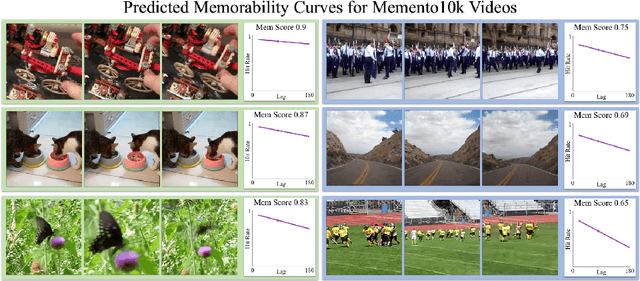
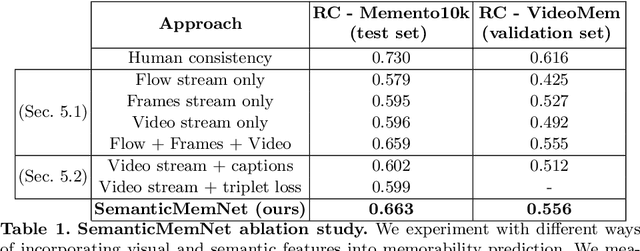


A key capability of an intelligent system is deciding when events from past experience must be remembered and when they can be forgotten. Towards this goal, we develop a predictive model of human visual event memory and how those memories decay over time. We introduce Memento10k, a new, dynamic video memorability dataset containing human annotations at different viewing delays. Based on our findings we propose a new mathematical formulation of memorability decay, resulting in a model that is able to produce the first quantitative estimation of how a video decays in memory over time. In contrast with previous work, our model can predict the probability that a video will be remembered at an arbitrary delay. Importantly, our approach combines visual and semantic information (in the form of textual captions) to fully represent the meaning of events. Our experiments on two video memorability benchmarks, including Memento10k, show that our model significantly improves upon the best prior approach (by 12% on average).
Predicting Visual Importance Across Graphic Design Types
Aug 07, 2020
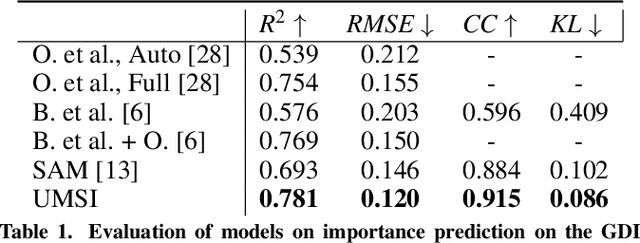
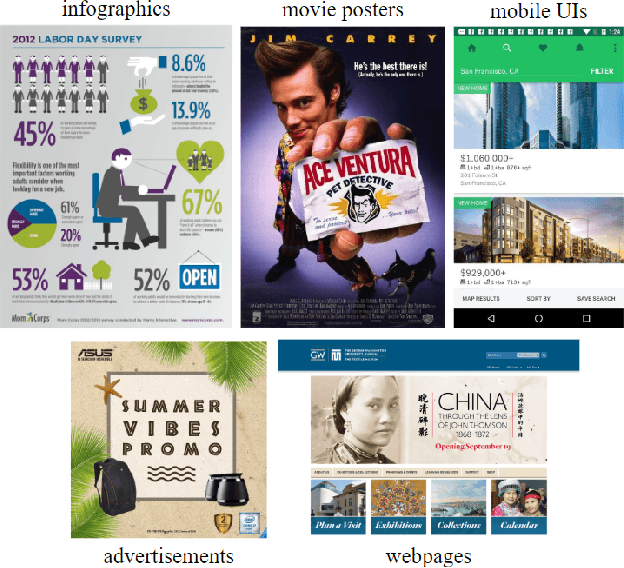
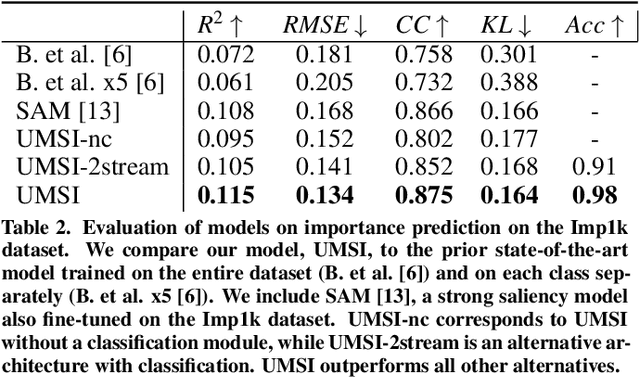
This paper introduces a Unified Model of Saliency and Importance (UMSI), which learns to predict visual importance in input graphic designs, and saliency in natural images, along with a new dataset and applications. Previous methods for predicting saliency or visual importance are trained individually on specialized datasets, making them limited in application and leading to poor generalization on novel image classes, while requiring a user to know which model to apply to which input. UMSI is a deep learning-based model simultaneously trained on images from different design classes, including posters, infographics, mobile UIs, as well as natural images, and includes an automatic classification module to classify the input. This allows the model to work more effectively without requiring a user to label the input. We also introduce Imp1k, a new dataset of designs annotated with importance information. We demonstrate two new design interfaces that use importance prediction, including a tool for adjusting the relative importance of design elements, and a tool for reflowing designs to new aspect ratios while preserving visual importance. The model, code, and importance dataset are available at https://predimportance.mit.edu .
Taskology: Utilizing Task Relations at Scale
May 14, 2020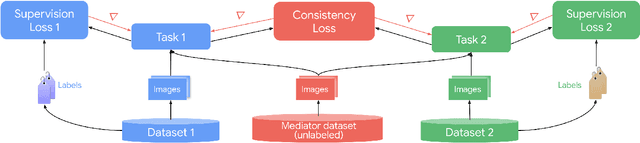
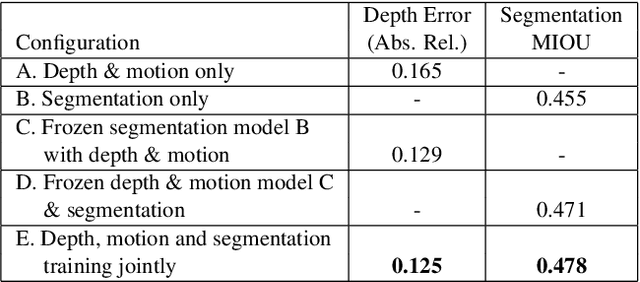
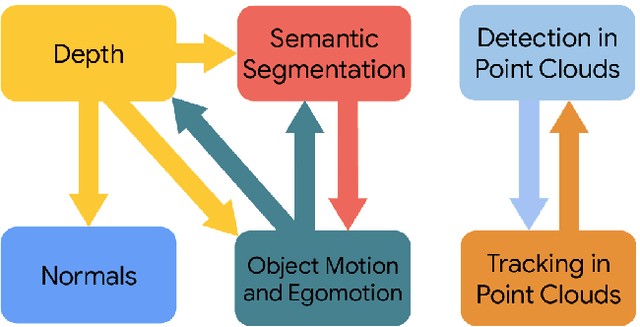
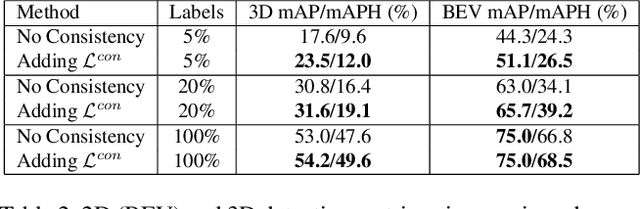
It has been recognized that the joint training of computer vision tasks with shared network components enables higher performance for each individual task. Training tasks together allows learning the inherent relationships among them; however, this requires large sets of labeled data. Instead, we argue that utilizing the known relationships between tasks explicitly allows improving their performance with less labeled data. To this end, we aim to establish and explore a novel approach for the collective training of computer vision tasks. In particular, we focus on utilizing the inherent relations of tasks by employing consistency constraints derived from physics, geometry, and logic. We show that collections of models can be trained without shared components, interacting only through the consistency constraints as supervision (peer-supervision). The consistency constraints enforce the structural priors between tasks, which enables their mutually consistent training, and -- in turn -- leads to overall higher performance. Treating individual tasks as modules, agnostic to their implementation, reduces the engineering overhead to collectively train many tasks to a minimum. Furthermore, the collective training can be distributed among multiple compute nodes, which further facilitates training at scale. We demonstrate our framework on subsets of the following collection of tasks: depth and normal prediction, semantic segmentation, 3D motion estimation, and object tracking and detection in point clouds.