 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFire as a Service: Augmenting Robot Simulators with Thermally and Visually Accurate Fire Dynamics
Mar 19, 2026Most existing robot simulators prioritize rigid-body dynamics and photorealistic rendering, but largely neglect the thermally and optically complex phenomena that characterize real-world fire environments. For robots envisioned as future firefighters, this limitation hinders both reliable capability evaluation and the generation of representative training data prior to deployment in hazardous scenarios. To address these challenges, we introduce Fire as a Service (FaaS), a novel, asynchronous co-simulation framework that augments existing robot simulators with high-fidelity and computationally efficient fire simulations. Our pipeline enables robots to experience accurate, multi-species thermodynamic heat transfer and visually consistent volumetric smoke without disrupting high-frequency rigid-body control loops. We demonstrate that our framework can be integrated with diverse robot simulators to generate physically accurate fire behavior, benchmark thermal hazards encountered by robotic platforms, and collect realistic multimodal perceptual data. Crucially, its real-time performance supports human-in-the-loop teleoperation, enabling the successful training of reactive, multimodal policies via Behavioral Cloning. By adding fire dynamics to robot simulations, FaaS provides a scalable pathway toward safer, more reliable deployment of robots in fire scenarios.
Understanding Fire Through Thermal Radiation Fields for Mobile Robots
Feb 22, 2026Safely moving through environments affected by fire is a critical capability for autonomous mobile robots deployed in disaster response. In this work, we present a novel approach for mobile robots to understand fire through building real-time thermal radiation fields. We register depth and thermal images to obtain a 3D point cloud annotated with temperature values. From these data, we identify fires and use the Stefan-Boltzmann law to approximate the thermal radiation in empty spaces. This enables the construction of a continuous thermal radiation field over the environment. We show that this representation can be used for robot navigation, where we embed thermal constraints into the cost map to compute collision-free and thermally safe paths. We validate our approach on a Boston Dynamics Spot robot in controlled experimental settings. Our experiments demonstrate the robot's ability to avoid hazardous regions while still reaching navigation goals. Our approach paves the way toward mobile robots that can be autonomously deployed in fire-affected environments, with potential applications in search-and-rescue, firefighting, and hazardous material response.
Prompt Pirates Need a Map: Stealing Seeds helps Stealing Prompts
Sep 11, 2025Diffusion models have significantly advanced text-to-image generation, enabling the creation of highly realistic images conditioned on textual prompts and seeds. Given the considerable intellectual and economic value embedded in such prompts, prompt theft poses a critical security and privacy concern. In this paper, we investigate prompt-stealing attacks targeting diffusion models. We reveal that numerical optimization-based prompt recovery methods are fundamentally limited as they do not account for the initial random noise used during image generation. We identify and exploit a noise-generation vulnerability (CWE-339), prevalent in major image-generation frameworks, originating from PyTorch's restriction of seed values to a range of $2^{32}$ when generating the initial random noise on CPUs. Through a large-scale empirical analysis conducted on images shared via the popular platform CivitAI, we demonstrate that approximately 95% of these images' seed values can be effectively brute-forced in 140 minutes per seed using our seed-recovery tool, SeedSnitch. Leveraging the recovered seed, we propose PromptPirate, a genetic algorithm-based optimization method explicitly designed for prompt stealing. PromptPirate surpasses state-of-the-art methods, i.e., PromptStealer, P2HP, and CLIP-Interrogator, achieving an 8-11% improvement in LPIPS similarity. Furthermore, we introduce straightforward and effective countermeasures that render seed stealing, and thus optimization-based prompt stealing, ineffective. We have disclosed our findings responsibly and initiated coordinated mitigation efforts with the developers to address this critical vulnerability.
Perm: A Parametric Representation for Multi-Style 3D Hair Modeling
Jul 31, 2024We present Perm, a learned parametric model of human 3D hair designed to facilitate various hair-related applications. Unlike previous work that jointly models the global hair shape and local strand details, we propose to disentangle them using a PCA-based strand representation in the frequency domain, thereby allowing more precise editing and output control. Specifically, we leverage our strand representation to fit and decompose hair geometry textures into low- to high-frequency hair structures. These decomposed textures are later parameterized with different generative models, emulating common stages in the hair modeling process. We conduct extensive experiments to validate the architecture design of \textsc{Perm}, and finally deploy the trained model as a generic prior to solve task-agnostic problems, further showcasing its flexibility and superiority in tasks such as 3D hair parameterization, hairstyle interpolation, single-view hair reconstruction, and hair-conditioned image generation. Our code and data will be available at: https://github.com/c-he/perm.
\textsc{Perm}: A Parametric Representation for Multi-Style 3D Hair Modeling
Jul 28, 2024We present \textsc{Perm}, a learned parametric model of human 3D hair designed to facilitate various hair-related applications. Unlike previous work that jointly models the global hair shape and local strand details, we propose to disentangle them using a PCA-based strand representation in the frequency domain, thereby allowing more precise editing and output control. Specifically, we leverage our strand representation to fit and decompose hair geometry textures into low- to high-frequency hair structures. These decomposed textures are later parameterized with different generative models, emulating common stages in the hair modeling process. We conduct extensive experiments to validate the architecture design of \textsc{Perm}, and finally deploy the trained model as a generic prior to solve task-agnostic problems, further showcasing its flexibility and superiority in tasks such as 3D hair parameterization, hairstyle interpolation, single-view hair reconstruction, and hair-conditioned image generation. Our code and data will be available at: \url{https://github.com/c-he/perm}.
LRM-Zero: Training Large Reconstruction Models with Synthesized Data
Jun 13, 2024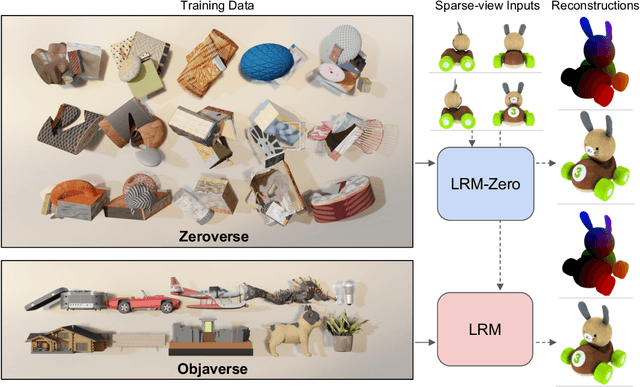
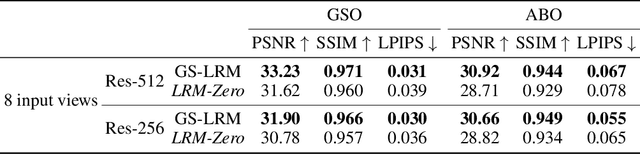
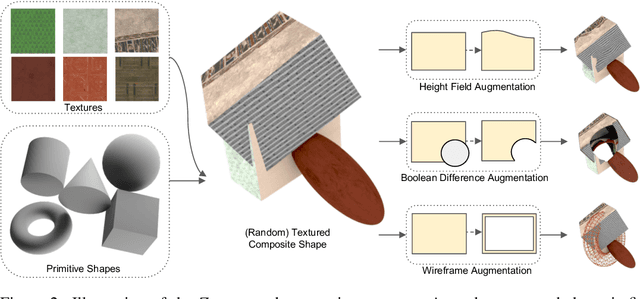
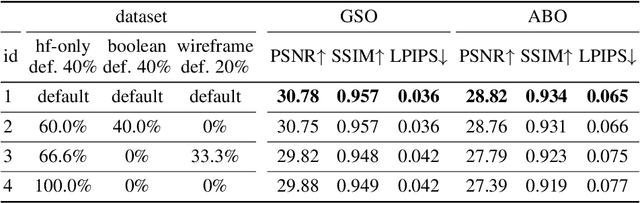
We present LRM-Zero, a Large Reconstruction Model (LRM) trained entirely on synthesized 3D data, achieving high-quality sparse-view 3D reconstruction. The core of LRM-Zero is our procedural 3D dataset, Zeroverse, which is automatically synthesized from simple primitive shapes with random texturing and augmentations (e.g., height fields, boolean differences, and wireframes). Unlike previous 3D datasets (e.g., Objaverse) which are often captured or crafted by humans to approximate real 3D data, Zeroverse completely ignores realistic global semantics but is rich in complex geometric and texture details that are locally similar to or even more intricate than real objects. We demonstrate that our LRM-Zero, trained with our fully synthesized Zeroverse, can achieve high visual quality in the reconstruction of real-world objects, competitive with models trained on Objaverse. We also analyze several critical design choices of Zeroverse that contribute to LRM-Zero's capability and training stability. Our work demonstrates that 3D reconstruction, one of the core tasks in 3D vision, can potentially be addressed without the semantics of real-world objects. The Zeroverse's procedural synthesis code and interactive visualization are available at: https://desaixie.github.io/lrm-zero/.
LAESI: Leaf Area Estimation with Synthetic Imagery
Mar 31, 2024We introduce LAESI, a Synthetic Leaf Dataset of 100,000 synthetic leaf images on millimeter paper, each with semantic masks and surface area labels. This dataset provides a resource for leaf morphology analysis primarily aimed at beech and oak leaves. We evaluate the applicability of the dataset by training machine learning models for leaf surface area prediction and semantic segmentation, using real images for validation. Our validation shows that these models can be trained to predict leaf surface area with a relative error not greater than an average human annotator. LAESI also provides an efficient framework based on 3D procedural models and generative AI for the large-scale, controllable generation of data with potential further applications in agriculture and biology. We evaluate the inclusion of generative AI in our procedural data generation pipeline and show how data filtering based on annotation consistency results in datasets which allow training the highest performing vision models.
Generating Diverse Agricultural Data for Vision-Based Farming Applications
Mar 27, 2024



We present a specialized procedural model for generating synthetic agricultural scenes, focusing on soybean crops, along with various weeds. This model is capable of simulating distinct growth stages of these plants, diverse soil conditions, and randomized field arrangements under varying lighting conditions. The integration of real-world textures and environmental factors into the procedural generation process enhances the photorealism and applicability of the synthetic data. Our dataset includes 12,000 images with semantic labels, offering a comprehensive resource for computer vision tasks in precision agriculture, such as semantic segmentation for autonomous weed control. We validate our model's effectiveness by comparing the synthetic data against real agricultural images, demonstrating its potential to significantly augment training data for machine learning models in agriculture. This approach not only provides a cost-effective solution for generating high-quality, diverse data but also addresses specific needs in agricultural vision tasks that are not fully covered by general-purpose models.
A Lennard-Jones Layer for Distribution Normalization
Feb 05, 2024

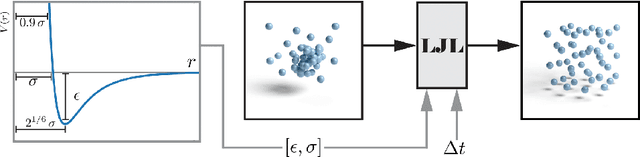

We introduce the Lennard-Jones layer (LJL) for the equalization of the density of 2D and 3D point clouds through systematically rearranging points without destroying their overall structure (distribution normalization). LJL simulates a dissipative process of repulsive and weakly attractive interactions between individual points by considering the nearest neighbor of each point at a given moment in time. This pushes the particles into a potential valley, reaching a well-defined stable configuration that approximates an equidistant sampling after the stabilization process. We apply LJLs to redistribute randomly generated point clouds into a randomized uniform distribution. Moreover, LJLs are embedded in the generation process of point cloud networks by adding them at later stages of the inference process. The improvements in 3D point cloud generation utilizing LJLs are evaluated qualitatively and quantitatively. Finally, we apply LJLs to improve the point distribution of a score-based 3D point cloud denoising network. In general, we demonstrate that LJLs are effective for distribution normalization which can be applied at negligible cost without retraining the given neural network.
Gazebo Plants: Simulating Plant-Robot Interaction with Cosserat Rods
Feb 04, 2024
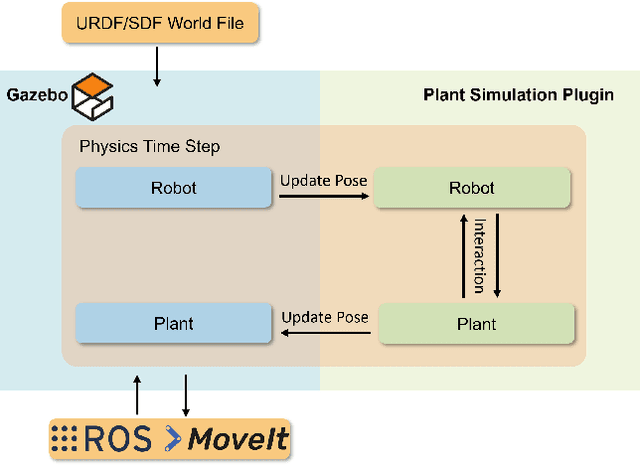
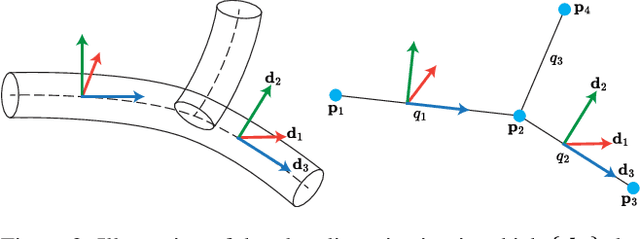
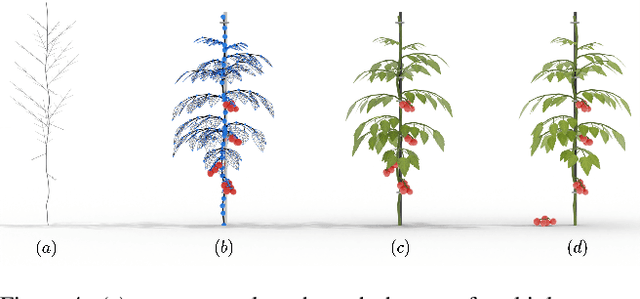
Robotic harvesting has the potential to positively impact agricultural productivity, reduce costs, improve food quality, enhance sustainability, and to address labor shortage. In the rapidly advancing field of agricultural robotics, the necessity of training robots in a virtual environment has become essential. Generating training data to automatize the underlying computer vision tasks such as image segmentation, object detection and classification, also heavily relies on such virtual environments as synthetic data is often required to overcome the shortage and lack of variety of real data sets. However, physics engines commonly employed within the robotics community, such as ODE, Simbody, Bullet, and DART, primarily support motion and collision interaction of rigid bodies. This inherent limitation hinders experimentation and progress in handling non-rigid objects such as plants and crops. In this contribution, we present a plugin for the Gazebo simulation platform based on Cosserat rods to model plant motion. It enables the simulation of plants and their interaction with the environment. We demonstrate that, using our plugin, users can conduct harvesting simulations in Gazebo by simulating a robotic arm picking fruits and achieve results comparable to real-world experiments.