 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAchieving Human Level Competitive Robot Table Tennis
Aug 07, 2024



Achieving human-level speed and performance on real world tasks is a north star for the robotics research community. This work takes a step towards that goal and presents the first learned robot agent that reaches amateur human-level performance in competitive table tennis. Table tennis is a physically demanding sport which requires human players to undergo years of training to achieve an advanced level of proficiency. In this paper, we contribute (1) a hierarchical and modular policy architecture consisting of (i) low level controllers with their detailed skill descriptors which model the agent's capabilities and help to bridge the sim-to-real gap and (ii) a high level controller that chooses the low level skills, (2) techniques for enabling zero-shot sim-to-real including an iterative approach to defining the task distribution that is grounded in the real-world and defines an automatic curriculum, and (3) real time adaptation to unseen opponents. Policy performance was assessed through 29 robot vs. human matches of which the robot won 45% (13/29). All humans were unseen players and their skill level varied from beginner to tournament level. Whilst the robot lost all matches vs. the most advanced players it won 100% matches vs. beginners and 55% matches vs. intermediate players, demonstrating solidly amateur human-level performance. Videos of the matches can be viewed at https://sites.google.com/view/competitive-robot-table-tennis
VisionTrap: Vision-Augmented Trajectory Prediction Guided by Textual Descriptions
Jul 17, 2024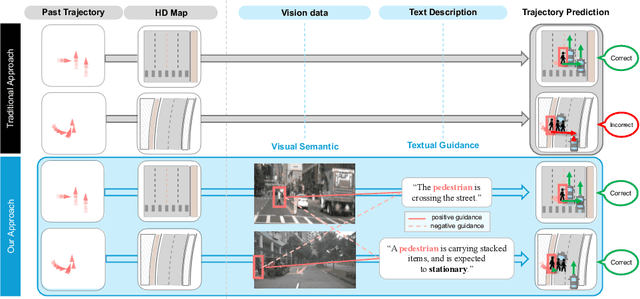
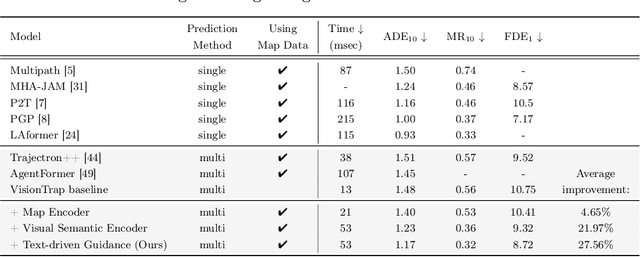

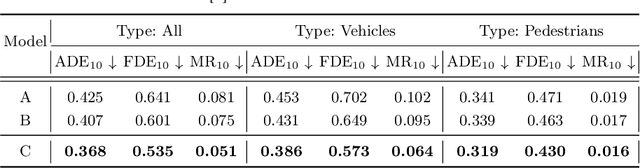
Predicting future trajectories for other road agents is an essential task for autonomous vehicles. Established trajectory prediction methods primarily use agent tracks generated by a detection and tracking system and HD map as inputs. In this work, we propose a novel method that also incorporates visual input from surround-view cameras, allowing the model to utilize visual cues such as human gazes and gestures, road conditions, vehicle turn signals, etc, which are typically hidden from the model in prior methods. Furthermore, we use textual descriptions generated by a Vision-Language Model (VLM) and refined by a Large Language Model (LLM) as supervision during training to guide the model on what to learn from the input data. Despite using these extra inputs, our method achieves a latency of 53 ms, making it feasible for real-time processing, which is significantly faster than that of previous single-agent prediction methods with similar performance. Our experiments show that both the visual inputs and the textual descriptions contribute to improvements in trajectory prediction performance, and our qualitative analysis highlights how the model is able to exploit these additional inputs. Lastly, in this work we create and release the nuScenes-Text dataset, which augments the established nuScenes dataset with rich textual annotations for every scene, demonstrating the positive impact of utilizing VLM on trajectory prediction. Our project page is at https://moonseokha.github.io/VisionTrap/
UniGen: Unified Modeling of Initial Agent States and Trajectories for Generating Autonomous Driving Scenarios
May 06, 2024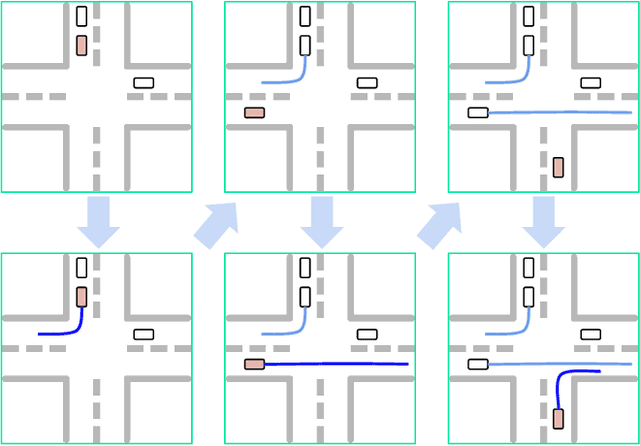
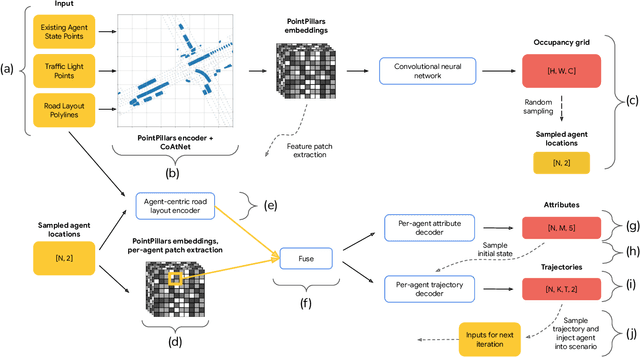
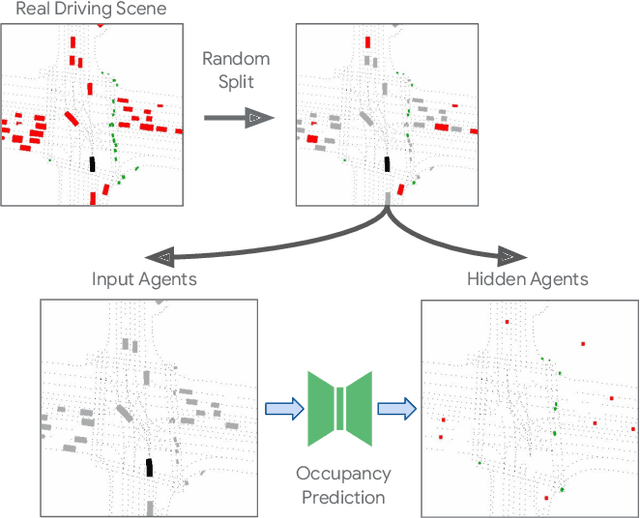

This paper introduces UniGen, a novel approach to generating new traffic scenarios for evaluating and improving autonomous driving software through simulation. Our approach models all driving scenario elements in a unified model: the position of new agents, their initial state, and their future motion trajectories. By predicting the distributions of all these variables from a shared global scenario embedding, we ensure that the final generated scenario is fully conditioned on all available context in the existing scene. Our unified modeling approach, combined with autoregressive agent injection, conditions the placement and motion trajectory of every new agent on all existing agents and their trajectories, leading to realistic scenarios with low collision rates. Our experimental results show that UniGen outperforms prior state of the art on the Waymo Open Motion Dataset.
Robotic Table Tennis: A Case Study into a High Speed Learning System
Sep 06, 2023



We present a deep-dive into a real-world robotic learning system that, in previous work, was shown to be capable of hundreds of table tennis rallies with a human and has the ability to precisely return the ball to desired targets. This system puts together a highly optimized perception subsystem, a high-speed low-latency robot controller, a simulation paradigm that can prevent damage in the real world and also train policies for zero-shot transfer, and automated real world environment resets that enable autonomous training and evaluation on physical robots. We complement a complete system description, including numerous design decisions that are typically not widely disseminated, with a collection of studies that clarify the importance of mitigating various sources of latency, accounting for training and deployment distribution shifts, robustness of the perception system, sensitivity to policy hyper-parameters, and choice of action space. A video demonstrating the components of the system and details of experimental results can be found at https://youtu.be/uFcnWjB42I0.
Instance Segmentation with Cross-Modal Consistency
Oct 14, 2022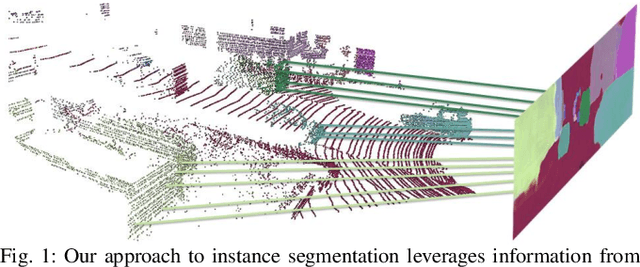
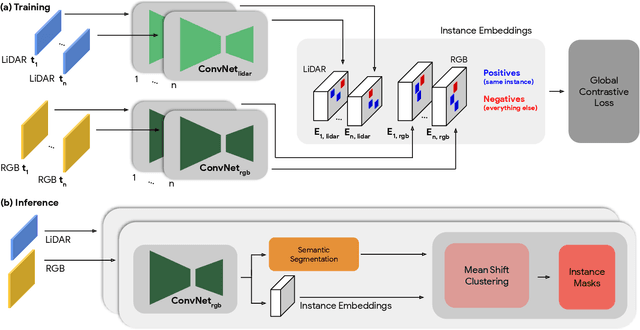

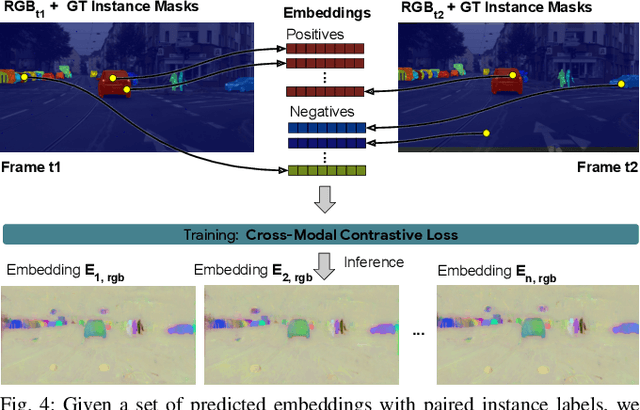
Segmenting object instances is a key task in machine perception, with safety-critical applications in robotics and autonomous driving. We introduce a novel approach to instance segmentation that jointly leverages measurements from multiple sensor modalities, such as cameras and LiDAR. Our method learns to predict embeddings for each pixel or point that give rise to a dense segmentation of the scene. Specifically, our technique applies contrastive learning to points in the scene both across sensor modalities and the temporal domain. We demonstrate that this formulation encourages the models to learn embeddings that are invariant to viewpoint variations and consistent across sensor modalities. We further demonstrate that the embeddings are stable over time as objects move around the scene. This not only provides stable instance masks, but can also provide valuable signals to downstream tasks, such as object tracking. We evaluate our method on the Cityscapes and KITTI-360 datasets. We further conduct a number of ablation studies, demonstrating benefits when applying additional inputs for the contrastive loss.
StopNet: Scalable Trajectory and Occupancy Prediction for Urban Autonomous Driving
Jun 02, 2022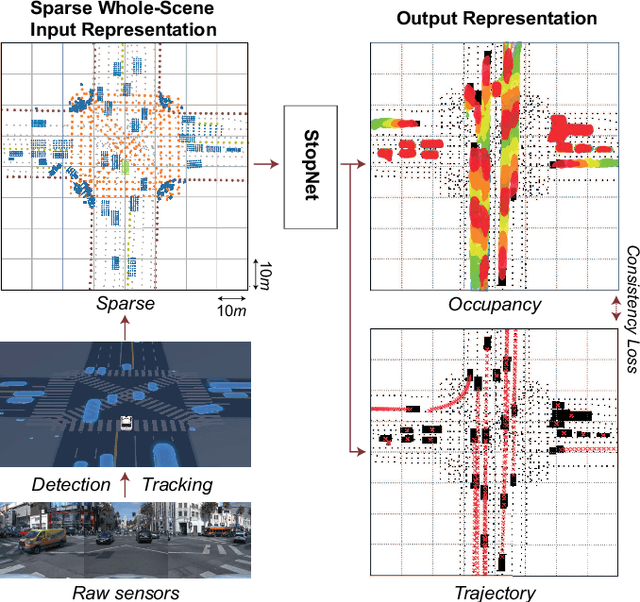
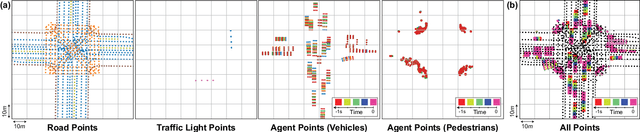
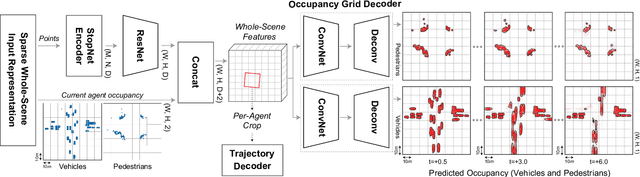
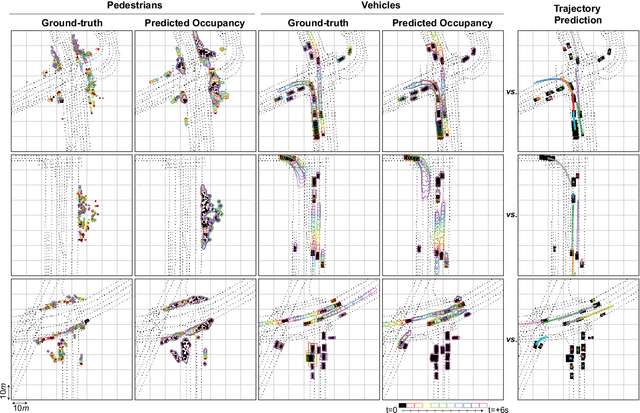
We introduce a motion forecasting (behavior prediction) method that meets the latency requirements for autonomous driving in dense urban environments without sacrificing accuracy. A whole-scene sparse input representation allows StopNet to scale to predicting trajectories for hundreds of road agents with reliable latency. In addition to predicting trajectories, our scene encoder lends itself to predicting whole-scene probabilistic occupancy grids, a complementary output representation suitable for busy urban environments. Occupancy grids allow the AV to reason collectively about the behavior of groups of agents without processing their individual trajectories. We demonstrate the effectiveness of our sparse input representation and our model in terms of computation and accuracy over three datasets. We further show that co-training consistent trajectory and occupancy predictions improves upon state-of-the-art performance under standard metrics.
Occupancy Flow Fields for Motion Forecasting in Autonomous Driving
Mar 08, 2022

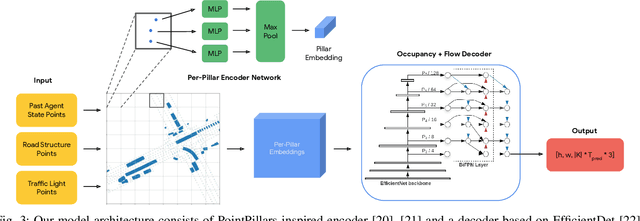

We propose Occupancy Flow Fields, a new representation for motion forecasting of multiple agents, an important task in autonomous driving. Our representation is a spatio-temporal grid with each grid cell containing both the probability of the cell being occupied by any agent, and a two-dimensional flow vector representing the direction and magnitude of the motion in that cell. Our method successfully mitigates shortcomings of the two most commonly-used representations for motion forecasting: trajectory sets and occupancy grids. Although occupancy grids efficiently represent the probabilistic location of many agents jointly, they do not capture agent motion and lose the agent identities. To this end, we propose a deep learning architecture that generates Occupancy Flow Fields with the help of a new flow trace loss that establishes consistency between the occupancy and flow predictions. We demonstrate the effectiveness of our approach using three metrics on occupancy prediction, motion estimation, and agent ID recovery. In addition, we introduce the problem of predicting speculative agents, which are currently-occluded agents that may appear in the future through dis-occlusion or by entering the field of view. We report experimental results on a large in-house autonomous driving dataset and the public INTERACTION dataset, and show that our model outperforms state-of-the-art models.
Identifying Driver Interactions via Conditional Behavior Prediction
Apr 20, 2021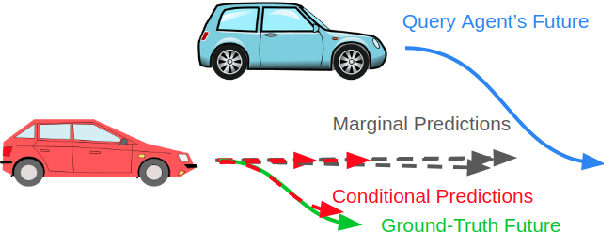
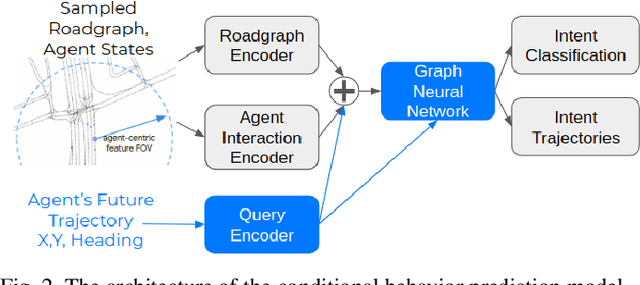
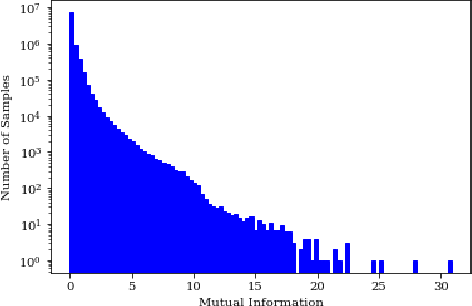
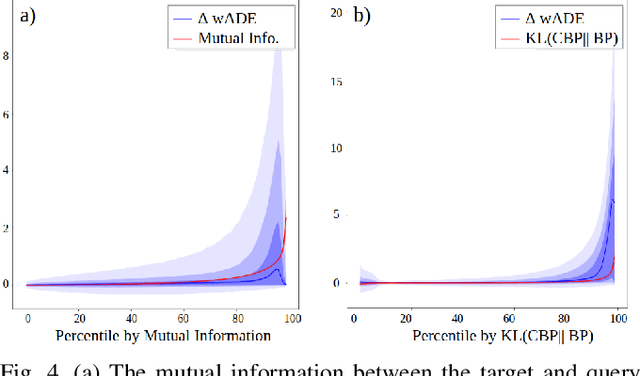
Interactive driving scenarios, such as lane changes, merges and unprotected turns, are some of the most challenging situations for autonomous driving. Planning in interactive scenarios requires accurately modeling the reactions of other agents to different future actions of the ego agent. We develop end-to-end models for conditional behavior prediction (CBP) that take as an input a query future trajectory for an ego-agent, and predict distributions over future trajectories for other agents conditioned on the query. Leveraging such a model, we develop a general-purpose agent interactivity score derived from probabilistic first principles. The interactivity score allows us to find interesting interactive scenarios for training and evaluating behavior prediction models. We further demonstrate that the proposed score is effective for agent prioritization under computational budget constraints.
Unsupervised Monocular Depth and Ego-motion Learning with Structure and Semantics
Jun 12, 2019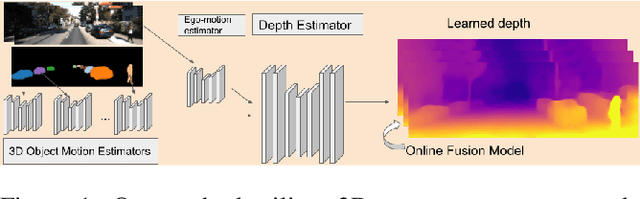
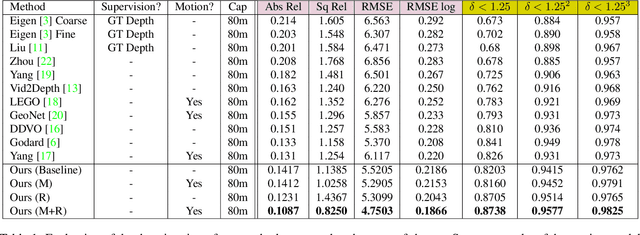
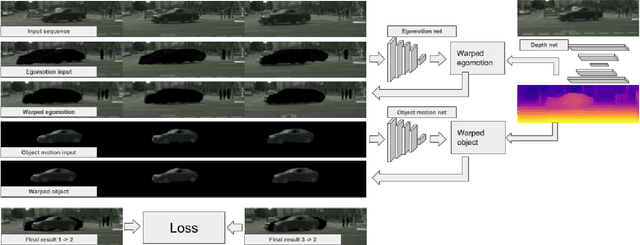

We present an approach which takes advantage of both structure and semantics for unsupervised monocular learning of depth and ego-motion. More specifically, we model the motion of individual objects and learn their 3D motion vector jointly with depth and ego-motion. We obtain more accurate results, especially for challenging dynamic scenes not addressed by previous approaches. This is an extended version of Casser et al. [AAAI'19]. Code and models have been open sourced at https://sites.google.com/corp/view/struct2depth.
Hierarchical Policy Design for Sample-Efficient Learning of Robot Table Tennis Through Self-Play
Feb 17, 2019


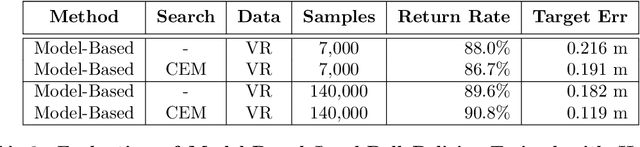
Training robots with physical bodies requires developing new methods and action representations that allow the learning agents to explore the space of policies efficiently. This work studies sample-efficient learning of complex policies in the context of robot table tennis. It incorporates learning into a hierarchical control framework using a model-free strategy layer (which requires complex reasoning about opponents that is difficult to do in a model-based way), model-based prediction of external objects (which are difficult to control directly with analytic control methods, but governed by learnable and relatively simple laws of physics), and analytic controllers for the robot itself. Human demonstrations are used to train dynamics models, which together with the analytic controller allow any robot that is physically capable to play table tennis without training episodes. Using only about 7,000 demonstrated trajectories, a striking policy can hit ball targets with about 20 cm error. Self-play is used to train cooperative and adversarial strategies on top of model-based striking skills trained from human demonstrations. After only about 24,000 strikes in self-play the agent learns to best exploit the human dynamics models for longer cooperative games. Further experiments demonstrate that more flexible variants of the policy can discover new strikes not demonstrated by humans and achieve higher performance at the expense of lower sample-efficiency. Experiments are carried out in a virtual reality environment using sensory observations that are obtainable in the real world. The high sample-efficiency demonstrated in the evaluations show that the proposed method is suitable for learning directly on physical robots without transfer of models or policies from simulation. Supplementary material available at https://sites.google.com/view/robottabletennis