 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSECOND-Grasp: Semantic Contact-guided Dexterous Grasping
May 13, 2026Achieving reliable robotic manipulation, such as dexterous grasping, requires a synergy between physically stable interactions and semantic task guidance, yet these objectives are often treated as separate, disjoint goals. In this paper, we investigate how to integrate dexterous grasping techniques, i.e., physically stable grasps for object lifting and language-guided grasp generation, to achieve both physical stability and semantic understanding. To this end, we propose SECOND-Grasp (SEmantic CONtact-guided Dexterous Grasping), a unified framework that enables robotic hands to dynamically adjust grasping strategies based on semantic reasoning while ensuring physical feasibility. We begin by obtaining coarse contact proposals through vision-language reasoning to infer where contacts should occur based on object properties, followed by segmentation to localize these regions across views. To further ensure consistency across multiple viewpoints, we introduce Semantic-Geometric Consistency Refinement (SGCR), which refines initial contact predictions by enforcing semantic consistency across views and removing geometrically invalid regions, yielding reliable 3D contact maps. Then, we derive a feasible hand pose for each contact map via inverse kinematics, generating a supervision signal for policy learning. Our approach, trained on DexGraspNet, consistently outperforms baselines in lifting success rate on both seen and unseen categories, achieving 98.2% and 97.7%, respectively, while also improving intent-aware grasping by 12.8% and 26.2%. We further show promising results on additional datasets and robotic hands, including Shadow Hand and Allegro Hand.
GuardMarkGS: Unified Ownership Tracing and Edit Deterrence for 3D Gaussian Splatting
May 13, 20263D Gaussian Splatting (3DGS) is becoming a practical representation for novel view synthesis, but its growing adoption, together with rapid advances in instruction-driven 3DGS editing, also exposes a dual copyright risk: once a 3DGS-based asset is released, it can be used without permission and manipulated through 3D editing. Existing protection methods address only one side of this problem. Watermarking can trace ownership after unauthorized use, but it cannot prevent malicious editing. Adversarial edit-deterrence methods can disrupt editing, but they do not provide evidence of ownership. To the best of our knowledge, we present the first unified protection framework for 3DGS that jointly optimizes ownership tracing and unauthorized editing deterrence. Our framework combines a scene-wide watermarking objective over all Gaussians with an adversarial objective for edit deterrence. The adversarial branch combines latent-anchor separation, denoising-trajectory diversion, and cross-attention diversion to divert the editing trajectory, while an update-saliency-motivated Gaussian selection strategy assigns stronger adversarial updates to mask-selected Gaussians, improving the balance among watermark recovery, edit deterrence, and rendering fidelity. Experiments on scenes from Mip-NeRF 360 and Instruct-NeRF2NeRF demonstrate that the proposed framework achieves a favorable balance among bit accuracy, edit deterrence, and rendering quality. These results suggest that practical copyright protection of 3DGS-based assets can be more effectively addressed by integrating ownership tracing and unauthorized editing deterrence into a single optimization framework.
Your Vision-Language-Action Model Already Has Attention Heads For Path Deviation Detection
Mar 14, 2026Vision-Language-Action (VLA) models have demonstrated strong potential for predicting semantic actions in navigation tasks, demonstrating the ability to reason over complex linguistic instructions and visual contexts. However, they are fundamentally hindered by visual-reasoning hallucinations that lead to trajectory deviations. Addressing this issue has conventionally required training external critic modules or relying on complex uncertainty heuristics. In this work, we discover that monitoring a few attention heads within a frozen VLA model can accurately detect path deviations without incurring additional computational overhead. We refer to these heads, which inherently capture the spatiotemporal causality between historical visual sequences and linguistic instructions, as Navigation Heads. Using these heads, we propose an intuitive, training-free anomaly-detection framework that monitors their signals to detect hallucinations in real time. Surprisingly, among over a thousand attention heads, a combination of just three is sufficient to achieve a 44.6 % deviation detection rate with a low false-positive rate of 11.7 %. Furthermore, upon detecting a deviation, we bypass the heavy VLA model and trigger a lightweight Reinforcement Learning (RL) policy to safely execute a shortest-path rollback. By integrating this entire detection-to-recovery pipeline onto a physical robot, we demonstrate its practical robustness. All source code will be publicly available.
High-Precision 6DOF Pose Estimation via Global Phase Retrieval in Fringe Projection Profilometry for 3D Mapping
Mar 12, 2026Digital fringe projection (DFP) enables micrometer-level 3D reconstruction, yet extending it to large-scale mapping remains challenging because six-degree-of-freedom pose estimation often cannot match the reconstruction's precision. Conventional iterative closest point (ICP) registration becomes inefficient on multi-million-point clouds and typically relies on downsampling or feature-based selection, which can reduce local detail and degrade pose precision. Drift-correction methods improve long-term consistency but do not resolve sampling sensitivity in dense DFP point clouds.We propose a high-precision pose estimation method that augments a moving DFP system with a fixed, intrinsically calibrated global projector. Using the global projector's phase-derived pixel constraints and a PnP-style reprojection objective, the method estimates the DFP system pose in a fixed reference frame without relying on deterministic feature extraction, and we experimentally demonstrate sampling invariance under coordinate-preserving subsampling. Experiments demonstrate sub-millimeter pose accuracy against a reference with quantified uncertainty bounds, high repeatability under aggressive subsampling, robust operation on homogeneous surfaces and low-overlap views, and reduced error accumulation when used to correct ICP-based trajectories. The method extends DFP toward accurate 3D mapping in quasi-static scenarios such as inspection and metrology, with the trade-off of time-multiplexed acquisition for the additional projector measurements.
M$^3$KG-RAG: Multi-hop Multimodal Knowledge Graph-enhanced Retrieval-Augmented Generation
Dec 24, 2025Retrieval-Augmented Generation (RAG) has recently been extended to multimodal settings, connecting multimodal large language models (MLLMs) with vast corpora of external knowledge such as multimodal knowledge graphs (MMKGs). Despite their recent success, multimodal RAG in the audio-visual domain remains challenging due to 1) limited modality coverage and multi-hop connectivity of existing MMKGs, and 2) retrieval based solely on similarity in a shared multimodal embedding space, which fails to filter out off-topic or redundant knowledge. To address these limitations, we propose M$^3$KG-RAG, a Multi-hop Multimodal Knowledge Graph-enhanced RAG that retrieves query-aligned audio-visual knowledge from MMKGs, improving reasoning depth and answer faithfulness in MLLMs. Specifically, we devise a lightweight multi-agent pipeline to construct multi-hop MMKG (M$^3$KG), which contains context-enriched triplets of multimodal entities, enabling modality-wise retrieval based on input queries. Furthermore, we introduce GRASP (Grounded Retrieval And Selective Pruning), which ensures precise entity grounding to the query, evaluates answer-supporting relevance, and prunes redundant context to retain only knowledge essential for response generation. Extensive experiments across diverse multimodal benchmarks demonstrate that M$^3$KG-RAG significantly enhances MLLMs' multimodal reasoning and grounding over existing approaches.
HyGE-Occ: Hybrid View-Transformation with 3D Gaussian and Edge Priors for 3D Panoptic Occupancy Prediction
Dec 22, 20253D Panoptic Occupancy Prediction aims to reconstruct a dense volumetric scene map by predicting the semantic class and instance identity of every occupied region in 3D space. Achieving such fine-grained 3D understanding requires precise geometric reasoning and spatially consistent scene representation across complex environments. However, existing approaches often struggle to maintain precise geometry and capture the precise spatial range of 3D instances critical for robust panoptic separation. To overcome these limitations, we introduce HyGE-Occ, a novel framework that leverages a hybrid view-transformation branch with 3D Gaussian and edge priors to enhance both geometric consistency and boundary awareness in 3D panoptic occupancy prediction. HyGE-Occ employs a hybrid view-transformation branch that fuses a continuous Gaussian-based depth representation with a discretized depth-bin formulation, producing BEV features with improved geometric consistency and structural coherence. In parallel, we extract edge maps from BEV features and use them as auxiliary information to learn edge cues. In our extensive experiments on the Occ3D-nuScenes dataset, HyGE-Occ outperforms existing work, demonstrating superior 3D geometric reasoning.
WaTeRFlow: Watermark Temporal Robustness via Flow Consistency
Dec 22, 2025Image watermarking supports authenticity and provenance, yet many schemes are still easy to bypass with various distortions and powerful generative edits. Deep learning-based watermarking has improved robustness to diffusion-based image editing, but a gap remains when a watermarked image is converted to video by image-to-video (I2V), in which per-frame watermark detection weakens. I2V has quickly advanced from short, jittery clips to multi-second, temporally coherent scenes, and it now serves not only content creation but also world-modeling and simulation workflows, making cross-modal watermark recovery crucial. We present WaTeRFlow, a framework tailored for robustness under I2V. It consists of (i) FUSE (Flow-guided Unified Synthesis Engine), which exposes the encoder-decoder to realistic distortions via instruction-driven edits and a fast video diffusion proxy during training, (ii) optical-flow warping with a Temporal Consistency Loss (TCL) that stabilizes per-frame predictions, and (iii) a semantic preservation loss that maintains the conditioning signal. Experiments across representative I2V models show accurate watermark recovery from frames, with higher first-frame and per-frame bit accuracy and resilience when various distortions are applied before or after video generation.
ICP-4D: Bridging Iterative Closest Point and LiDAR Panoptic Segmentation
Dec 22, 2025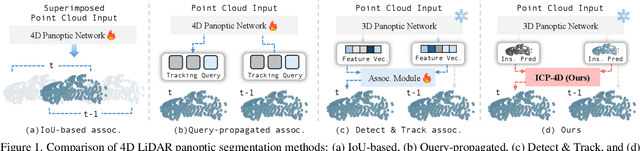
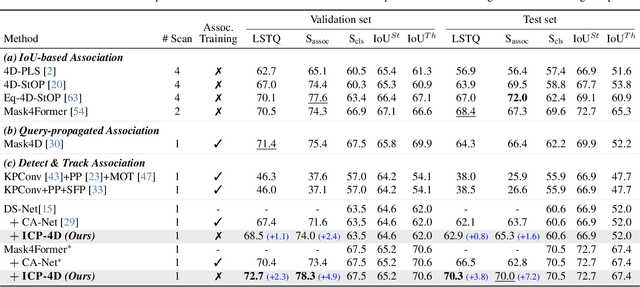
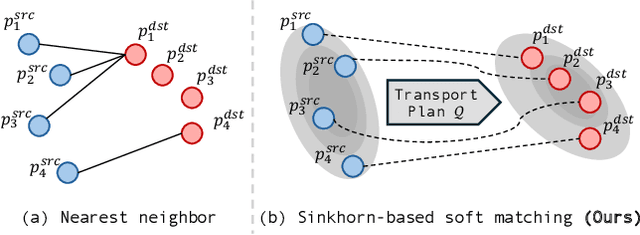
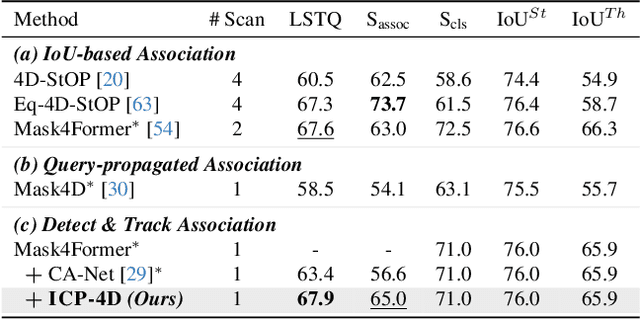
Dominant paradigms for 4D LiDAR panoptic segmentation are usually required to train deep neural networks with large superimposed point clouds or design dedicated modules for instance association. However, these approaches perform redundant point processing and consequently become computationally expensive, yet still overlook the rich geometric priors inherently provided by raw point clouds. To this end, we introduce ICP-4D, a simple yet effective training-free framework that unifies spatial and temporal reasoning through geometric relations among instance-level point sets. Specifically, we apply the Iterative Closest Point (ICP) algorithm to directly associate temporally consistent instances by aligning the source and target point sets through the estimated transformation. To stabilize association under noisy instance predictions, we introduce a Sinkhorn-based soft matching. This exploits the underlying instance distribution to obtain accurate point-wise correspondences, resulting in robust geometric alignment. Furthermore, our carefully designed pipeline, which considers three instance types-static, dynamic, and missing-offers computational efficiency and occlusion-aware matching. Our extensive experiments across both SemanticKITTI and panoptic nuScenes demonstrate that our method consistently outperforms state-of-the-art approaches, even without additional training or extra point cloud inputs.
Decoupled Generative Modeling for Human-Object Interaction Synthesis
Dec 22, 2025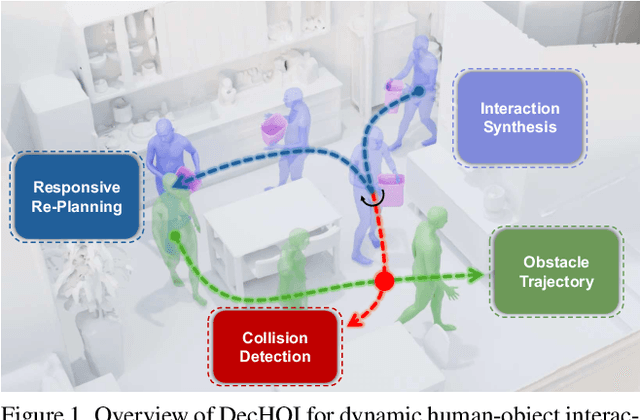
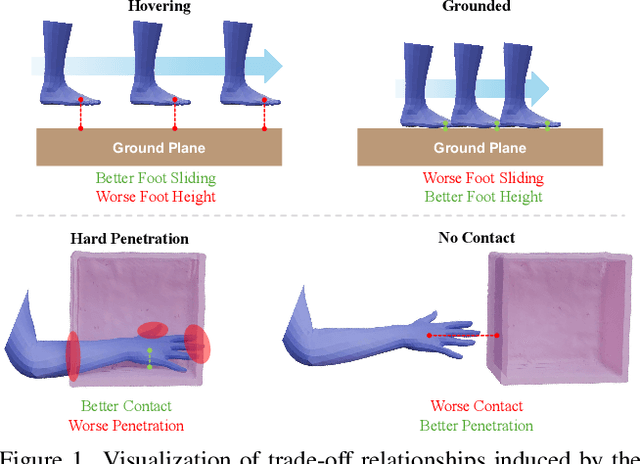
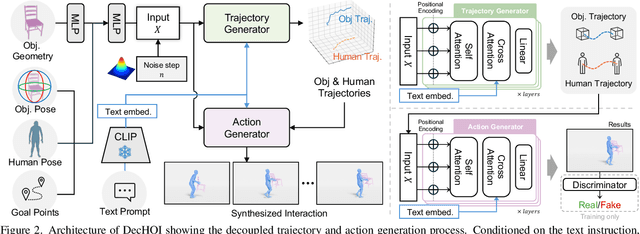
Synthesizing realistic human-object interaction (HOI) is essential for 3D computer vision and robotics, underpinning animation and embodied control. Existing approaches often require manually specified intermediate waypoints and place all optimization objectives on a single network, which increases complexity, reduces flexibility, and leads to errors such as unsynchronized human and object motion or penetration. To address these issues, we propose Decoupled Generative Modeling for Human-Object Interaction Synthesis (DecHOI), which separates path planning and action synthesis. A trajectory generator first produces human and object trajectories without prescribed waypoints, and an action generator conditions on these paths to synthesize detailed motions. To further improve contact realism, we employ adversarial training with a discriminator that focuses on the dynamics of distal joints. The framework also models a moving counterpart and supports responsive, long-sequence planning in dynamic scenes, while preserving plan consistency. Across two benchmarks, FullBodyManipulation and 3D-FUTURE, DecHOI surpasses prior methods on most quantitative metrics and qualitative evaluations, and perceptual studies likewise prefer our results.
AgriChrono: A Multi-modal Dataset Capturing Crop Growth and Lighting Variability with a Field Robot
Aug 26, 2025Existing datasets for precision agriculture have primarily been collected in static or controlled environments such as indoor labs or greenhouses, often with limited sensor diversity and restricted temporal span. These conditions fail to reflect the dynamic nature of real farmland, including illumination changes, crop growth variation, and natural disturbances. As a result, models trained on such data often lack robustness and generalization when applied to real-world field scenarios. In this paper, we present AgriChrono, a novel robotic data collection platform and multi-modal dataset designed to capture the dynamic conditions of real-world agricultural environments. Our platform integrates multiple sensors and enables remote, time-synchronized acquisition of RGB, Depth, LiDAR, and IMU data, supporting efficient and repeatable long-term data collection across varying illumination and crop growth stages. We benchmark a range of state-of-the-art 3D reconstruction models on the AgriChrono dataset, highlighting the difficulty of reconstruction in real-world field environments and demonstrating its value as a research asset for advancing model generalization under dynamic conditions. The code and dataset are publicly available at: https://github.com/StructuresComp/agri-chrono