 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoXaRt: Audio-Visual Object-Guided Sound Interaction for XR
Mar 11, 2026In Extended Reality (XR), complex acoustic environments often overwhelm users, compromising both scene awareness and social engagement due to entangled sound sources. We introduce MoXaRt, a real-time XR system that uses audio-visual cues to separate these sources and enable fine-grained sound interaction. MoXaRt's core is a cascaded architecture that performs coarse, audio-only separation in parallel with visual detection of sources (e.g., faces, instruments). These visual anchors then guide refinement networks to isolate individual sources, separating complex mixes of up to 5 concurrent sources (e.g., 2 voices + 3 instruments) with ~2 second processing latency. We validate MoXaRt through a technical evaluation on a new dataset of 30 one-minute recordings featuring concurrent speech and music, and a 22-participant user study. Empirical results indicate that our system significantly enhances speech intelligibility, yielding a 36.2% (p < 0.01) increase in listening comprehension within adversarial acoustic environments while substantially reducing cognitive load (p < 0.001), thereby paving the way for more perceptive and socially adept XR experiences.
FaceShield: Defending Facial Image against Deepfake Threats
Dec 13, 2024The rising use of deepfakes in criminal activities presents a significant issue, inciting widespread controversy. While numerous studies have tackled this problem, most primarily focus on deepfake detection. These reactive solutions are insufficient as a fundamental approach for crimes where authenticity verification is not critical. Existing proactive defenses also have limitations, as they are effective only for deepfake models based on specific Generative Adversarial Networks (GANs), making them less applicable in light of recent advancements in diffusion-based models. In this paper, we propose a proactive defense method named FaceShield, which introduces novel attack strategies targeting deepfakes generated by Diffusion Models (DMs) and facilitates attacks on various existing GAN-based deepfake models through facial feature extractor manipulations. Our approach consists of three main components: (i) manipulating the attention mechanism of DMs to exclude protected facial features during the denoising process, (ii) targeting prominent facial feature extraction models to enhance the robustness of our adversarial perturbation, and (iii) employing Gaussian blur and low-pass filtering techniques to improve imperceptibility while enhancing robustness against JPEG distortion. Experimental results on the CelebA-HQ and VGGFace2-HQ datasets demonstrate that our method achieves state-of-the-art performance against the latest deepfake models based on DMs, while also exhibiting applicability to GANs and showcasing greater imperceptibility of noise along with enhanced robustness.
MTVG : Multi-text Video Generation with Text-to-Video Models
Dec 07, 2023Recently, video generation has attracted massive attention and yielded noticeable outcomes. Concerning the characteristics of video, multi-text conditioning incorporating sequential events is necessary for next-step video generation. In this work, we propose a novel multi-text video generation~(MTVG) by directly utilizing a pre-trained diffusion-based text-to-video~(T2V) generation model without additional fine-tuning. To generate consecutive video segments, visual consistency generated by distinct prompts is necessary with diverse variations, such as motion and content-related transitions. Our proposed MTVG includes Dynamic Noise and Last Frame Aware Inversion which reinitialize the noise latent to preserve visual coherence between videos of different prompts and prevent repetitive motion or contents. Furthermore, we present Structure Guiding Sampling to maintain the global appearance across the frames in a single video clip, where we leverage iterative latent updates across the preceding frame. Additionally, our Prompt Generator allows for arbitrary format of text conditions consisting of diverse events. As a result, our extensive experiments, including diverse transitions of descriptions, demonstrate that our proposed methods show superior generated outputs in terms of semantically coherent and temporally seamless video.Video examples are available in our project page: https://kuai-lab.github.io/mtvg-page.
Soundini: Sound-Guided Diffusion for Natural Video Editing
Apr 13, 2023



We propose a method for adding sound-guided visual effects to specific regions of videos with a zero-shot setting. Animating the appearance of the visual effect is challenging because each frame of the edited video should have visual changes while maintaining temporal consistency. Moreover, existing video editing solutions focus on temporal consistency across frames, ignoring the visual style variations over time, e.g., thunderstorm, wave, fire crackling. To overcome this limitation, we utilize temporal sound features for the dynamic style. Specifically, we guide denoising diffusion probabilistic models with an audio latent representation in the audio-visual latent space. To the best of our knowledge, our work is the first to explore sound-guided natural video editing from various sound sources with sound-specialized properties, such as intensity, timbre, and volume. Additionally, we design optical flow-based guidance to generate temporally consistent video frames, capturing the pixel-wise relationship between adjacent frames. Experimental results show that our method outperforms existing video editing techniques, producing more realistic visual effects that reflect the properties of sound. Please visit our page: https://kuai-lab.github.io/soundini-gallery/.
An Attention-based Method for Action Unit Detection at the 3rd ABAW Competition
Mar 23, 2022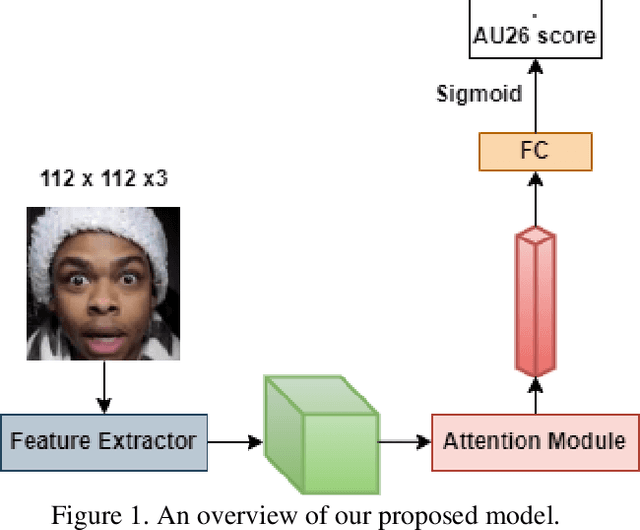
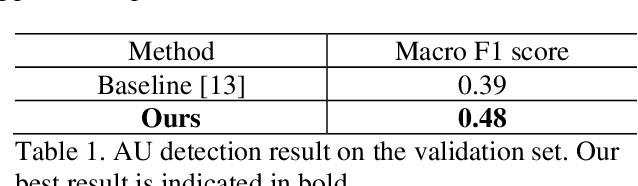
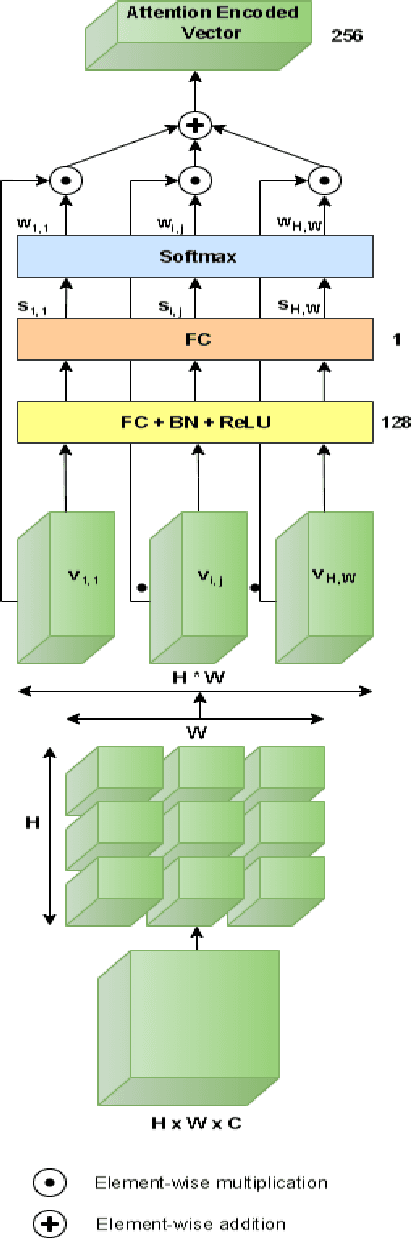
Facial Action Coding System is an approach for modeling the complexity of human emotional expression. Automatic action unit (AU) detection is a crucial research area in human-computer interaction. This paper describes our submission to the third Affective Behavior Analysis in-the-wild (ABAW) competition 2022. We proposed a method for detecting facial action units in the video. At the first stage, a lightweight CNN-based feature extractor is employed to extract the feature map from each video frame. Then, an attention module is applied to refine the attention map. The attention encoded vector is derived using a weighted sum of the feature map and the attention scores later. Finally, the sigmoid function is used at the output layer to make the prediction suitable for multi-label AUs detection. We achieved a macro F1 score of 0.48 on the ABAW challenge validation set compared to 0.39 from the baseline model.