 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPT-4o System Card
Oct 25, 2024GPT-4o is an autoregressive omni model that accepts as input any combination of text, audio, image, and video, and generates any combination of text, audio, and image outputs. It's trained end-to-end across text, vision, and audio, meaning all inputs and outputs are processed by the same neural network. GPT-4o can respond to audio inputs in as little as 232 milliseconds, with an average of 320 milliseconds, which is similar to human response time in conversation. It matches GPT-4 Turbo performance on text in English and code, with significant improvement on text in non-English languages, while also being much faster and 50\% cheaper in the API. GPT-4o is especially better at vision and audio understanding compared to existing models. In line with our commitment to building AI safely and consistent with our voluntary commitments to the White House, we are sharing the GPT-4o System Card, which includes our Preparedness Framework evaluations. In this System Card, we provide a detailed look at GPT-4o's capabilities, limitations, and safety evaluations across multiple categories, focusing on speech-to-speech while also evaluating text and image capabilities, and measures we've implemented to ensure the model is safe and aligned. We also include third-party assessments on dangerous capabilities, as well as discussion of potential societal impacts of GPT-4o's text and vision capabilities.
Improve Supervised Representation Learning with Masked Image Modeling
Dec 01, 2023
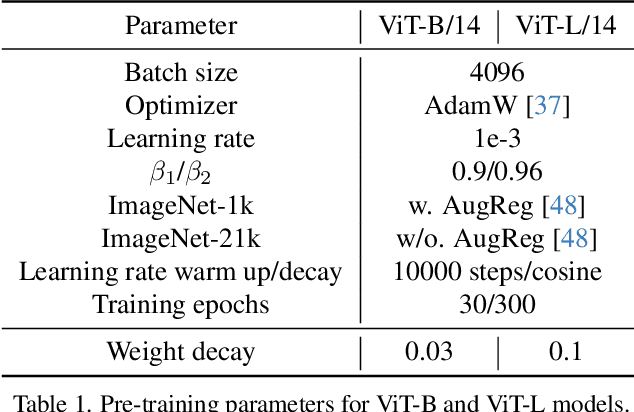
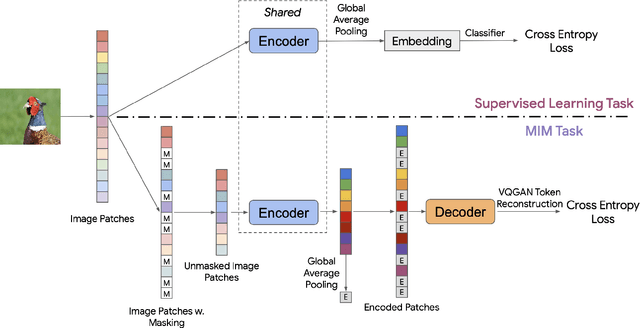
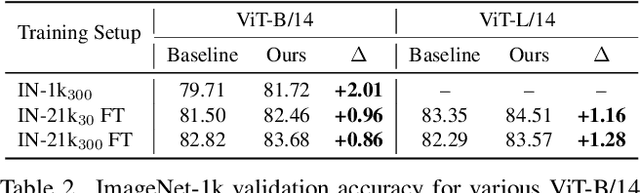
Training visual embeddings with labeled data supervision has been the de facto setup for representation learning in computer vision. Inspired by recent success of adopting masked image modeling (MIM) in self-supervised representation learning, we propose a simple yet effective setup that can easily integrate MIM into existing supervised training paradigms. In our design, in addition to the original classification task applied to a vision transformer image encoder, we add a shallow transformer-based decoder on top of the encoder and introduce an MIM task which tries to reconstruct image tokens based on masked image inputs. We show with minimal change in architecture and no overhead in inference that this setup is able to improve the quality of the learned representations for downstream tasks such as classification, image retrieval, and semantic segmentation. We conduct a comprehensive study and evaluation of our setup on public benchmarks. On ImageNet-1k, our ViT-B/14 model achieves 81.72% validation accuracy, 2.01% higher than the baseline model. On K-Nearest-Neighbor image retrieval evaluation with ImageNet-1k, the same model outperforms the baseline by 1.32%. We also show that this setup can be easily scaled to larger models and datasets. Code and checkpoints will be released.
Leveraging Unpaired Data for Vision-Language Generative Models via Cycle Consistency
Oct 05, 2023
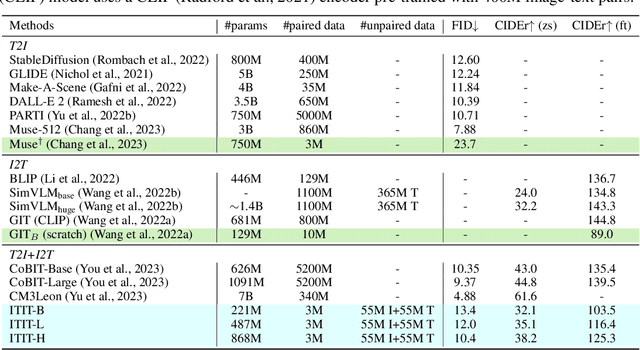
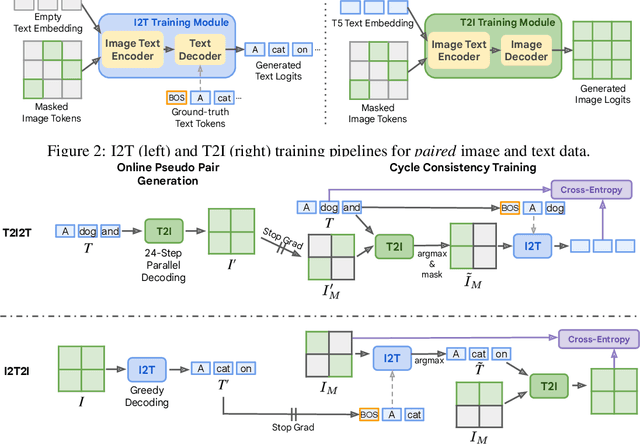
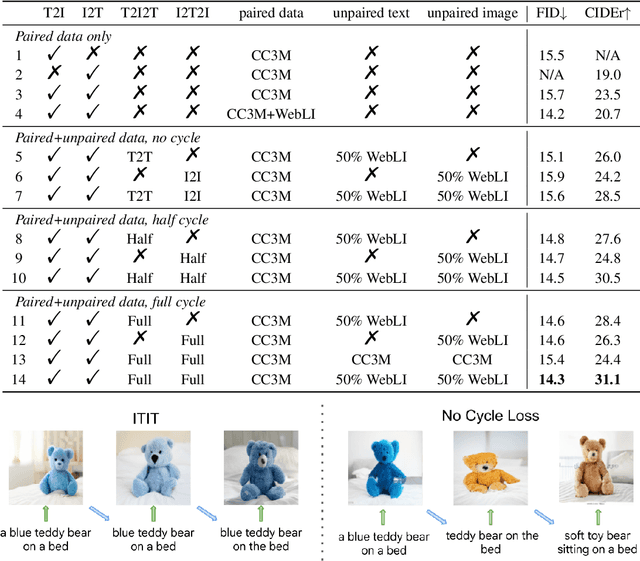
Current vision-language generative models rely on expansive corpora of paired image-text data to attain optimal performance and generalization capabilities. However, automatically collecting such data (e.g. via large-scale web scraping) leads to low quality and poor image-text correlation, while human annotation is more accurate but requires significant manual effort and expense. We introduce $\textbf{ITIT}$ ($\textbf{I}$n$\textbf{T}$egrating $\textbf{I}$mage $\textbf{T}$ext): an innovative training paradigm grounded in the concept of cycle consistency which allows vision-language training on unpaired image and text data. ITIT is comprised of a joint image-text encoder with disjoint image and text decoders that enable bidirectional image-to-text and text-to-image generation in a single framework. During training, ITIT leverages a small set of paired image-text data to ensure its output matches the input reasonably well in both directions. Simultaneously, the model is also trained on much larger datasets containing only images or texts. This is achieved by enforcing cycle consistency between the original unpaired samples and the cycle-generated counterparts. For instance, it generates a caption for a given input image and then uses the caption to create an output image, and enforces similarity between the input and output images. Our experiments show that ITIT with unpaired datasets exhibits similar scaling behavior as using high-quality paired data. We demonstrate image generation and captioning performance on par with state-of-the-art text-to-image and image-to-text models with orders of magnitude fewer (only 3M) paired image-text data.
StyleDrop: Text-to-Image Generation in Any Style
Jun 01, 2023
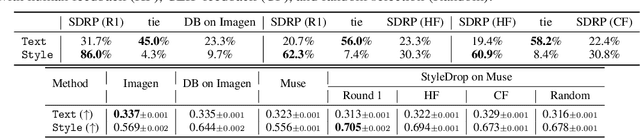


Pre-trained large text-to-image models synthesize impressive images with an appropriate use of text prompts. However, ambiguities inherent in natural language and out-of-distribution effects make it hard to synthesize image styles, that leverage a specific design pattern, texture or material. In this paper, we introduce StyleDrop, a method that enables the synthesis of images that faithfully follow a specific style using a text-to-image model. The proposed method is extremely versatile and captures nuances and details of a user-provided style, such as color schemes, shading, design patterns, and local and global effects. It efficiently learns a new style by fine-tuning very few trainable parameters (less than $1\%$ of total model parameters) and improving the quality via iterative training with either human or automated feedback. Better yet, StyleDrop is able to deliver impressive results even when the user supplies only a single image that specifies the desired style. An extensive study shows that, for the task of style tuning text-to-image models, StyleDrop implemented on Muse convincingly outperforms other methods, including DreamBooth and textual inversion on Imagen or Stable Diffusion. More results are available at our project website: https://styledrop.github.io
StableRep: Synthetic Images from Text-to-Image Models Make Strong Visual Representation Learners
Jun 01, 2023We investigate the potential of learning visual representations using synthetic images generated by text-to-image models. This is a natural question in the light of the excellent performance of such models in generating high-quality images. We consider specifically the Stable Diffusion, one of the leading open source text-to-image models. We show that (1) when the generative model is configured with proper classifier-free guidance scale, training self-supervised methods on synthetic images can match or beat the real image counterpart; (2) by treating the multiple images generated from the same text prompt as positives for each other, we develop a multi-positive contrastive learning method, which we call StableRep. With solely synthetic images, the representations learned by StableRep surpass the performance of representations learned by SimCLR and CLIP using the same set of text prompts and corresponding real images, on large scale datasets. When we further add language supervision, StableRep trained with 20M synthetic images achieves better accuracy than CLIP trained with 50M real images.
Learning Disentangled Prompts for Compositional Image Synthesis
Jun 01, 2023



We study domain-adaptive image synthesis, the problem of teaching pretrained image generative models a new style or concept from as few as one image to synthesize novel images, to better understand the compositional image synthesis. We present a framework that leverages a pretrained class-conditional generation model and visual prompt tuning. Specifically, we propose a novel source class distilled visual prompt that learns disentangled prompts of semantic (e.g., class) and domain (e.g., style) from a few images. Learned domain prompt is then used to synthesize images of any classes in the style of target domain. We conduct studies on various target domains with the number of images ranging from one to a few to many, and show qualitative results which show the compositional generalization of our method. Moreover, we show that our method can help improve zero-shot domain adaptation classification accuracy.
Score-Based Diffusion Models as Principled Priors for Inverse Imaging
Apr 23, 2023



It is important in computational imaging to understand the uncertainty of images reconstructed from imperfect measurements. We propose turning score-based diffusion models into principled priors (``score-based priors'') for analyzing a posterior of images given measurements. Previously, probabilistic priors were limited to handcrafted regularizers and simple distributions. In this work, we empirically validate the theoretically-proven probability function of a score-based diffusion model. We show how to sample from resulting posteriors by using this probability function for variational inference. Our results, including experiments on denoising, deblurring, and interferometric imaging, suggest that score-based priors enable principled inference with a sophisticated, data-driven image prior.
Soundini: Sound-Guided Diffusion for Natural Video Editing
Apr 13, 2023



We propose a method for adding sound-guided visual effects to specific regions of videos with a zero-shot setting. Animating the appearance of the visual effect is challenging because each frame of the edited video should have visual changes while maintaining temporal consistency. Moreover, existing video editing solutions focus on temporal consistency across frames, ignoring the visual style variations over time, e.g., thunderstorm, wave, fire crackling. To overcome this limitation, we utilize temporal sound features for the dynamic style. Specifically, we guide denoising diffusion probabilistic models with an audio latent representation in the audio-visual latent space. To the best of our knowledge, our work is the first to explore sound-guided natural video editing from various sound sources with sound-specialized properties, such as intensity, timbre, and volume. Additionally, we design optical flow-based guidance to generate temporally consistent video frames, capturing the pixel-wise relationship between adjacent frames. Experimental results show that our method outperforms existing video editing techniques, producing more realistic visual effects that reflect the properties of sound. Please visit our page: https://kuai-lab.github.io/soundini-gallery/.
StraIT: Non-autoregressive Generation with Stratified Image Transformer
Mar 01, 2023We propose Stratified Image Transformer(StraIT), a pure non-autoregressive(NAR) generative model that demonstrates superiority in high-quality image synthesis over existing autoregressive(AR) and diffusion models(DMs). In contrast to the under-exploitation of visual characteristics in existing vision tokenizer, we leverage the hierarchical nature of images to encode visual tokens into stratified levels with emergent properties. Through the proposed image stratification that obtains an interlinked token pair, we alleviate the modeling difficulty and lift the generative power of NAR models. Our experiments demonstrate that StraIT significantly improves NAR generation and out-performs existing DMs and AR methods while being order-of-magnitude faster, achieving FID scores of 3.96 at 256*256 resolution on ImageNet without leveraging any guidance in sampling or auxiliary image classifiers. When equipped with classifier-free guidance, our method achieves an FID of 3.36 and IS of 259.3. In addition, we illustrate the decoupled modeling process of StraIT generation, showing its compelling properties on applications including domain transfer.
VQ3D: Learning a 3D-Aware Generative Model on ImageNet
Feb 14, 2023


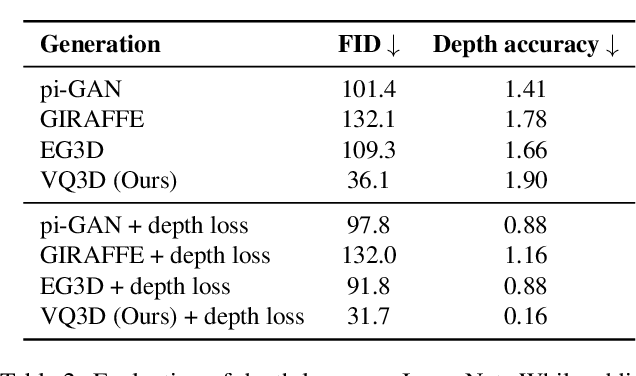
Recent work has shown the possibility of training generative models of 3D content from 2D image collections on small datasets corresponding to a single object class, such as human faces, animal faces, or cars. However, these models struggle on larger, more complex datasets. To model diverse and unconstrained image collections such as ImageNet, we present VQ3D, which introduces a NeRF-based decoder into a two-stage vector-quantized autoencoder. Our Stage 1 allows for the reconstruction of an input image and the ability to change the camera position around the image, and our Stage 2 allows for the generation of new 3D scenes. VQ3D is capable of generating and reconstructing 3D-aware images from the 1000-class ImageNet dataset of 1.2 million training images. We achieve an ImageNet generation FID score of 16.8, compared to 69.8 for the next best baseline method.