 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Autoregressive Visual Generation and Understanding with Continuous Tokens
Mar 17, 2025We present UniFluid, a unified autoregressive framework for joint visual generation and understanding leveraging continuous visual tokens. Our unified autoregressive architecture processes multimodal image and text inputs, generating discrete tokens for text and continuous tokens for image. We find though there is an inherent trade-off between the image generation and understanding task, a carefully tuned training recipe enables them to improve each other. By selecting an appropriate loss balance weight, the unified model achieves results comparable to or exceeding those of single-task baselines on both tasks. Furthermore, we demonstrate that employing stronger pre-trained LLMs and random-order generation during training is important to achieve high-fidelity image generation within this unified framework. Built upon the Gemma model series, UniFluid exhibits competitive performance across both image generation and understanding, demonstrating strong transferability to various downstream tasks, including image editing for generation, as well as visual captioning and question answering for understanding.
Fractal Generative Models
Feb 25, 2025Modularization is a cornerstone of computer science, abstracting complex functions into atomic building blocks. In this paper, we introduce a new level of modularization by abstracting generative models into atomic generative modules. Analogous to fractals in mathematics, our method constructs a new type of generative model by recursively invoking atomic generative modules, resulting in self-similar fractal architectures that we call fractal generative models. As a running example, we instantiate our fractal framework using autoregressive models as the atomic generative modules and examine it on the challenging task of pixel-by-pixel image generation, demonstrating strong performance in both likelihood estimation and generation quality. We hope this work could open a new paradigm in generative modeling and provide a fertile ground for future research. Code is available at https://github.com/LTH14/fractalgen.
Fluid: Scaling Autoregressive Text-to-image Generative Models with Continuous Tokens
Oct 17, 2024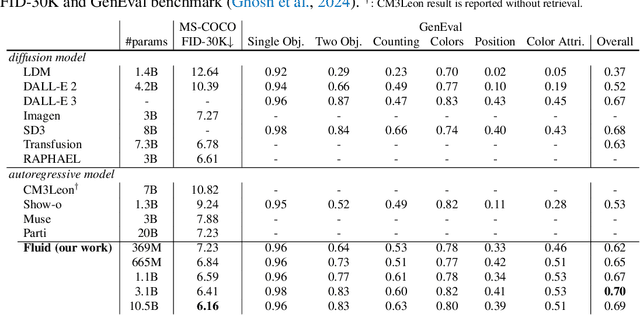
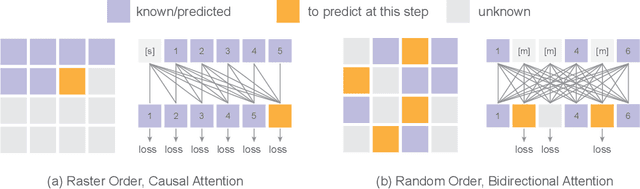
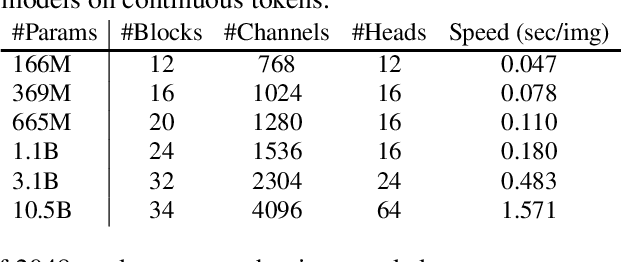
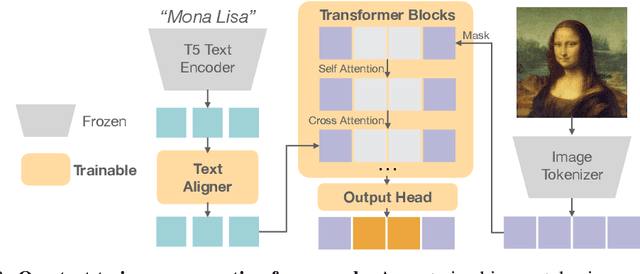
Scaling up autoregressive models in vision has not proven as beneficial as in large language models. In this work, we investigate this scaling problem in the context of text-to-image generation, focusing on two critical factors: whether models use discrete or continuous tokens, and whether tokens are generated in a random or fixed raster order using BERT- or GPT-like transformer architectures. Our empirical results show that, while all models scale effectively in terms of validation loss, their evaluation performance -- measured by FID, GenEval score, and visual quality -- follows different trends. Models based on continuous tokens achieve significantly better visual quality than those using discrete tokens. Furthermore, the generation order and attention mechanisms significantly affect the GenEval score: random-order models achieve notably better GenEval scores compared to raster-order models. Inspired by these findings, we train Fluid, a random-order autoregressive model on continuous tokens. Fluid 10.5B model achieves a new state-of-the-art zero-shot FID of 6.16 on MS-COCO 30K, and 0.69 overall score on the GenEval benchmark. We hope our findings and results will encourage future efforts to further bridge the scaling gap between vision and language models.
Learning Vision from Models Rivals Learning Vision from Data
Dec 28, 2023



We introduce SynCLR, a novel approach for learning visual representations exclusively from synthetic images and synthetic captions, without any real data. We synthesize a large dataset of image captions using LLMs, then use an off-the-shelf text-to-image model to generate multiple images corresponding to each synthetic caption. We perform visual representation learning on these synthetic images via contrastive learning, treating images sharing the same caption as positive pairs. The resulting representations transfer well to many downstream tasks, competing favorably with other general-purpose visual representation learners such as CLIP and DINO v2 in image classification tasks. Furthermore, in dense prediction tasks such as semantic segmentation, SynCLR outperforms previous self-supervised methods by a significant margin, e.g., improving over MAE and iBOT by 6.2 and 4.3 mIoU on ADE20k for ViT-B/16.
Scaling Laws of Synthetic Images for Model Training for Now
Dec 07, 2023



Recent significant advances in text-to-image models unlock the possibility of training vision systems using synthetic images, potentially overcoming the difficulty of collecting curated data at scale. It is unclear, however, how these models behave at scale, as more synthetic data is added to the training set. In this paper we study the scaling laws of synthetic images generated by state of the art text-to-image models, for the training of supervised models: image classifiers with label supervision, and CLIP with language supervision. We identify several factors, including text prompts, classifier-free guidance scale, and types of text-to-image models, that significantly affect scaling behavior. After tuning these factors, we observe that synthetic images demonstrate a scaling trend similar to, but slightly less effective than, real images in CLIP training, while they significantly underperform in scaling when training supervised image classifiers. Our analysis indicates that the main reason for this underperformance is the inability of off-the-shelf text-to-image models to generate certain concepts, a limitation that significantly impairs the training of image classifiers. Our findings also suggest that scaling synthetic data can be particularly effective in scenarios such as: (1) when there is a limited supply of real images for a supervised problem (e.g., fewer than 0.5 million images in ImageNet), (2) when the evaluation dataset diverges significantly from the training data, indicating the out-of-distribution scenario, or (3) when synthetic data is used in conjunction with real images, as demonstrated in the training of CLIP models.
StableRep: Synthetic Images from Text-to-Image Models Make Strong Visual Representation Learners
Jun 01, 2023We investigate the potential of learning visual representations using synthetic images generated by text-to-image models. This is a natural question in the light of the excellent performance of such models in generating high-quality images. We consider specifically the Stable Diffusion, one of the leading open source text-to-image models. We show that (1) when the generative model is configured with proper classifier-free guidance scale, training self-supervised methods on synthetic images can match or beat the real image counterpart; (2) by treating the multiple images generated from the same text prompt as positives for each other, we develop a multi-positive contrastive learning method, which we call StableRep. With solely synthetic images, the representations learned by StableRep surpass the performance of representations learned by SimCLR and CLIP using the same set of text prompts and corresponding real images, on large scale datasets. When we further add language supervision, StableRep trained with 20M synthetic images achieves better accuracy than CLIP trained with 50M real images.
Improving CLIP Training with Language Rewrites
May 31, 2023



Contrastive Language-Image Pre-training (CLIP) stands as one of the most effective and scalable methods for training transferable vision models using paired image and text data. CLIP models are trained using contrastive loss, which typically relies on data augmentations to prevent overfitting and shortcuts. However, in the CLIP training paradigm, data augmentations are exclusively applied to image inputs, while language inputs remain unchanged throughout the entire training process, limiting the exposure of diverse texts to the same image. In this paper, we introduce Language augmented CLIP (LaCLIP), a simple yet highly effective approach to enhance CLIP training through language rewrites. Leveraging the in-context learning capability of large language models, we rewrite the text descriptions associated with each image. These rewritten texts exhibit diversity in sentence structure and vocabulary while preserving the original key concepts and meanings. During training, LaCLIP randomly selects either the original texts or the rewritten versions as text augmentations for each image. Extensive experiments on CC3M, CC12M, RedCaps and LAION-400M datasets show that CLIP pre-training with language rewrites significantly improves the transfer performance without computation or memory overhead during training. Specifically for ImageNet zero-shot accuracy, LaCLIP outperforms CLIP by 8.2% on CC12M and 2.4% on LAION-400M. Code is available at https://github.com/LijieFan/LaCLIP.
Reparo: Loss-Resilient Generative Codec for Video Conferencing
May 23, 2023



Loss of packets in video conferencing often results in poor quality and video freezing. Attempting to retransmit the lost packets is usually not practical due to the requirement for real-time playback. Using Forward Error Correction (FEC) to recover the lost packets is challenging since it is difficult to determine the appropriate level of redundancy. In this paper, we propose a framework called Reparo for creating loss-resilient video conferencing using generative deep learning models. Our approach involves generating missing information when a frame or part of a frame is lost. This generation is conditioned on the data received so far, and the model's knowledge of how people look, dress, and interact in the visual world. Our experiments on publicly available video conferencing datasets show that Reparo outperforms state-of-the-art FEC-based video conferencing in terms of both video quality (measured by PSNR) and video freezes.
Visual Dependency Transformers: Dependency Tree Emerges from Reversed Attention
Apr 06, 2023Humans possess a versatile mechanism for extracting structured representations of our visual world. When looking at an image, we can decompose the scene into entities and their parts as well as obtain the dependencies between them. To mimic such capability, we propose Visual Dependency Transformers (DependencyViT) that can induce visual dependencies without any labels. We achieve that with a novel neural operator called \emph{reversed attention} that can naturally capture long-range visual dependencies between image patches. Specifically, we formulate it as a dependency graph where a child token in reversed attention is trained to attend to its parent tokens and send information following a normalized probability distribution rather than gathering information in conventional self-attention. With such a design, hierarchies naturally emerge from reversed attention layers, and a dependency tree is progressively induced from leaf nodes to the root node unsupervisedly. DependencyViT offers several appealing benefits. (i) Entities and their parts in an image are represented by different subtrees, enabling part partitioning from dependencies; (ii) Dynamic visual pooling is made possible. The leaf nodes which rarely send messages can be pruned without hindering the model performance, based on which we propose the lightweight DependencyViT-Lite to reduce the computational and memory footprints; (iii) DependencyViT works well on both self- and weakly-supervised pretraining paradigms on ImageNet, and demonstrates its effectiveness on 8 datasets and 5 tasks, such as unsupervised part and saliency segmentation, recognition, and detection.
Unsupervised Learning for Human Sensing Using Radio Signals
Jul 06, 2022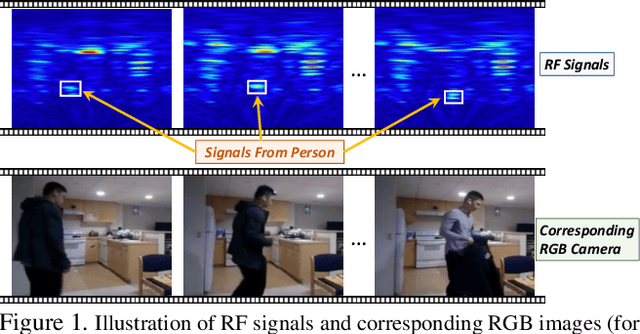
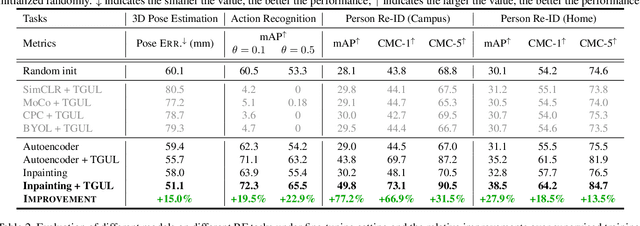
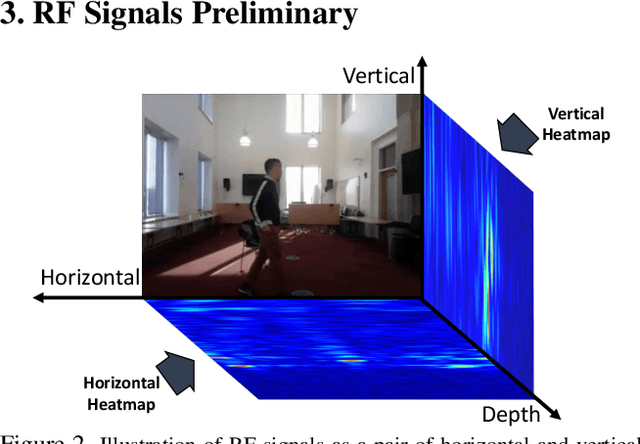
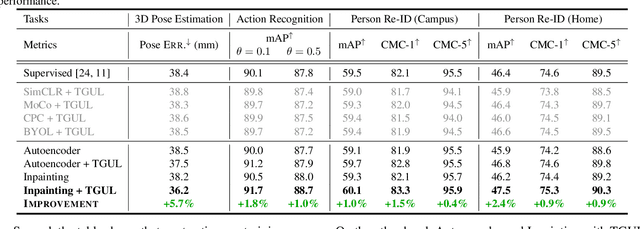
There is a growing literature demonstrating the feasibility of using Radio Frequency (RF) signals to enable key computer vision tasks in the presence of occlusions and poor lighting. It leverages that RF signals traverse walls and occlusions to deliver through-wall pose estimation, action recognition, scene captioning, and human re-identification. However, unlike RGB datasets which can be labeled by human workers, labeling RF signals is a daunting task because such signals are not human interpretable. Yet, it is fairly easy to collect unlabelled RF signals. It would be highly beneficial to use such unlabeled RF data to learn useful representations in an unsupervised manner. Thus, in this paper, we explore the feasibility of adapting RGB-based unsupervised representation learning to RF signals. We show that while contrastive learning has emerged as the main technique for unsupervised representation learning from images and videos, such methods produce poor performance when applied to sensing humans using RF signals. In contrast, predictive unsupervised learning methods learn high-quality representations that can be used for multiple downstream RF-based sensing tasks. Our empirical results show that this approach outperforms state-of-the-art RF-based human sensing on various tasks, opening the possibility of unsupervised representation learning from this novel modality.