 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFocused Skill Discovery: Learning to Control Specific State Variables while Minimizing Side Effects
Oct 06, 2025


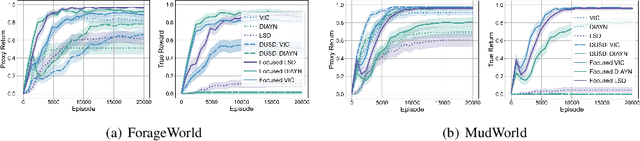
Skills are essential for unlocking higher levels of problem solving. A common approach to discovering these skills is to learn ones that reliably reach different states, thus empowering the agent to control its environment. However, existing skill discovery algorithms often overlook the natural state variables present in many reinforcement learning problems, meaning that the discovered skills lack control of specific state variables. This can significantly hamper exploration efficiency, make skills more challenging to learn with, and lead to negative side effects in downstream tasks when the goal is under-specified. We introduce a general method that enables these skill discovery algorithms to learn focused skills -- skills that target and control specific state variables. Our approach improves state space coverage by a factor of three, unlocks new learning capabilities, and automatically avoids negative side effects in downstream tasks.
Fractal Generative Models
Feb 25, 2025Modularization is a cornerstone of computer science, abstracting complex functions into atomic building blocks. In this paper, we introduce a new level of modularization by abstracting generative models into atomic generative modules. Analogous to fractals in mathematics, our method constructs a new type of generative model by recursively invoking atomic generative modules, resulting in self-similar fractal architectures that we call fractal generative models. As a running example, we instantiate our fractal framework using autoregressive models as the atomic generative modules and examine it on the challenging task of pixel-by-pixel image generation, demonstrating strong performance in both likelihood estimation and generation quality. We hope this work could open a new paradigm in generative modeling and provide a fertile ground for future research. Code is available at https://github.com/LTH14/fractalgen.
DafnyBench: A Benchmark for Formal Software Verification
Jun 12, 2024



We introduce DafnyBench, the largest benchmark of its kind for training and evaluating machine learning systems for formal software verification. We test the ability of LLMs such as GPT-4 and Claude 3 to auto-generate enough hints for the Dafny formal verification engine to successfully verify over 750 programs with about 53,000 lines of code. The best model and prompting scheme achieved 68% success rate, and we quantify how this rate improves when retrying with error message feedback and how it deteriorates with the amount of required code and hints. We hope that DafnyBench will enable rapid improvements from this baseline as LLMs and verification techniques grow in quality.
Black-Box Access is Insufficient for Rigorous AI Audits
Jan 25, 2024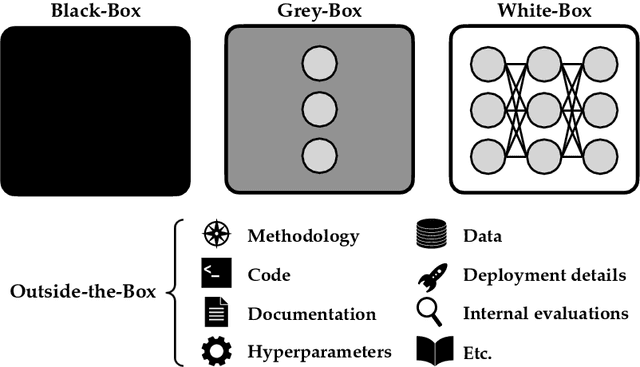
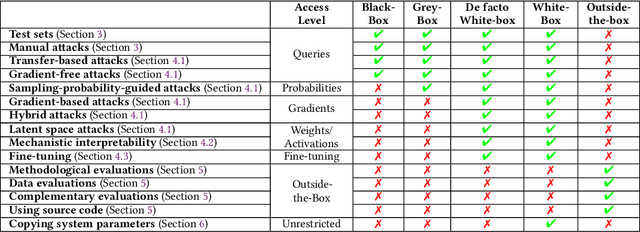
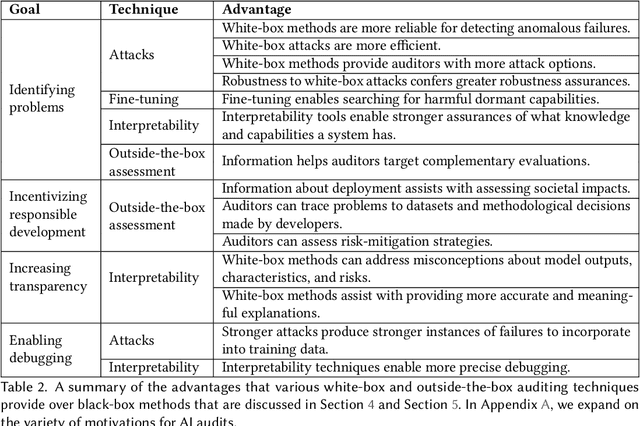
External audits of AI systems are increasingly recognized as a key mechanism for AI governance. The effectiveness of an audit, however, depends on the degree of system access granted to auditors. Recent audits of state-of-the-art AI systems have primarily relied on black-box access, in which auditors can only query the system and observe its outputs. However, white-box access to the system's inner workings (e.g., weights, activations, gradients) allows an auditor to perform stronger attacks, more thoroughly interpret models, and conduct fine-tuning. Meanwhile, outside-the-box access to its training and deployment information (e.g., methodology, code, documentation, hyperparameters, data, deployment details, findings from internal evaluations) allows for auditors to scrutinize the development process and design more targeted evaluations. In this paper, we examine the limitations of black-box audits and the advantages of white- and outside-the-box audits. We also discuss technical, physical, and legal safeguards for performing these audits with minimal security risks. Given that different forms of access can lead to very different levels of evaluation, we conclude that (1) transparency regarding the access and methods used by auditors is necessary to properly interpret audit results, and (2) white- and outside-the-box access allow for substantially more scrutiny than black-box access alone.
Universal Neurons in GPT2 Language Models
Jan 22, 2024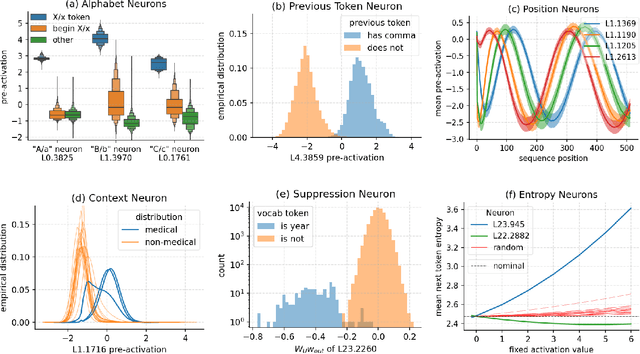
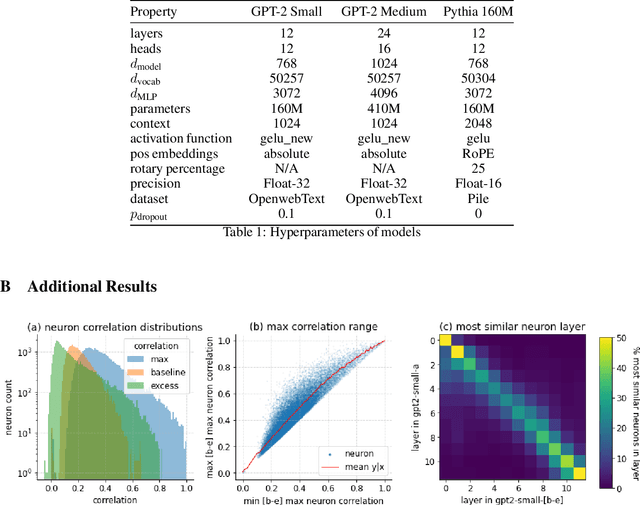
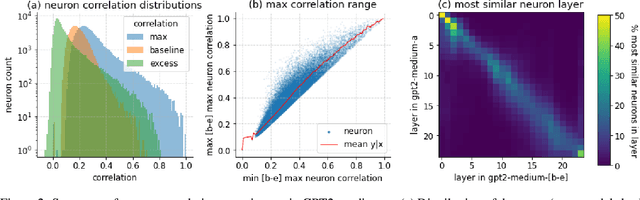
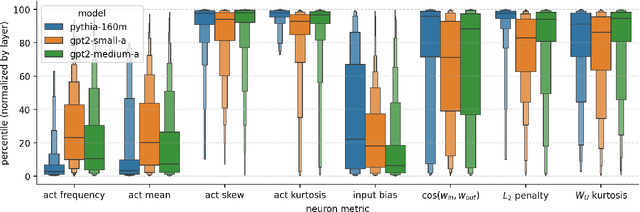
A basic question within the emerging field of mechanistic interpretability is the degree to which neural networks learn the same underlying mechanisms. In other words, are neural mechanisms universal across different models? In this work, we study the universality of individual neurons across GPT2 models trained from different initial random seeds, motivated by the hypothesis that universal neurons are likely to be interpretable. In particular, we compute pairwise correlations of neuron activations over 100 million tokens for every neuron pair across five different seeds and find that 1-5\% of neurons are universal, that is, pairs of neurons which consistently activate on the same inputs. We then study these universal neurons in detail, finding that they usually have clear interpretations and taxonomize them into a small number of neuron families. We conclude by studying patterns in neuron weights to establish several universal functional roles of neurons in simple circuits: deactivating attention heads, changing the entropy of the next token distribution, and predicting the next token to (not) be within a particular set.