 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoPT: Scaling Physics Simulation via Lifted Geometric Pre-Training
Feb 23, 2026Neural simulators promise efficient surrogates for physics simulation, but scaling them is bottlenecked by the prohibitive cost of generating high-fidelity training data. Pre-training on abundant off-the-shelf geometries offers a natural alternative, yet faces a fundamental gap: supervision on static geometry alone ignores dynamics and can lead to negative transfer on physics tasks. We present GeoPT, a unified pre-trained model for general physics simulation based on lifted geometric pre-training. The core idea is to augment geometry with synthetic dynamics, enabling dynamics-aware self-supervision without physics labels. Pre-trained on over one million samples, GeoPT consistently improves industrial-fidelity benchmarks spanning fluid mechanics for cars, aircraft, and ships, and solid mechanics in crash simulation, reducing labeled data requirements by 20-60% and accelerating convergence by 2$\times$. These results show that lifting with synthetic dynamics bridges the geometry-physics gap, unlocking a scalable path for neural simulation and potentially beyond. Code is available at https://github.com/Physics-Scaling/GeoPT.
Generative Modeling via Drifting
Feb 04, 2026Generative modeling can be formulated as learning a mapping f such that its pushforward distribution matches the data distribution. The pushforward behavior can be carried out iteratively at inference time, for example in diffusion and flow-based models. In this paper, we propose a new paradigm called Drifting Models, which evolve the pushforward distribution during training and naturally admit one-step inference. We introduce a drifting field that governs the sample movement and achieves equilibrium when the distributions match. This leads to a training objective that allows the neural network optimizer to evolve the distribution. In experiments, our one-step generator achieves state-of-the-art results on ImageNet at 256 x 256 resolution, with an FID of 1.54 in latent space and 1.61 in pixel space. We hope that our work opens up new opportunities for high-quality one-step generation.
One-step Latent-free Image Generation with Pixel Mean Flows
Jan 29, 2026Modern diffusion/flow-based models for image generation typically exhibit two core characteristics: (i) using multi-step sampling, and (ii) operating in a latent space. Recent advances have made encouraging progress on each aspect individually, paving the way toward one-step diffusion/flow without latents. In this work, we take a further step towards this goal and propose "pixel MeanFlow" (pMF). Our core guideline is to formulate the network output space and the loss space separately. The network target is designed to be on a presumed low-dimensional image manifold (i.e., x-prediction), while the loss is defined via MeanFlow in the velocity space. We introduce a simple transformation between the image manifold and the average velocity field. In experiments, pMF achieves strong results for one-step latent-free generation on ImageNet at 256x256 resolution (2.22 FID) and 512x512 resolution (2.48 FID), filling a key missing piece in this regime. We hope that our study will further advance the boundaries of diffusion/flow-based generative models.
Bidirectional Normalizing Flow: From Data to Noise and Back
Dec 11, 2025Normalizing Flows (NFs) have been established as a principled framework for generative modeling. Standard NFs consist of a forward process and a reverse process: the forward process maps data to noise, while the reverse process generates samples by inverting it. Typical NF forward transformations are constrained by explicit invertibility, ensuring that the reverse process can serve as their exact analytic inverse. Recent developments in TARFlow and its variants have revitalized NF methods by combining Transformers and autoregressive flows, but have also exposed causal decoding as a major bottleneck. In this work, we introduce Bidirectional Normalizing Flow ($\textbf{BiFlow}$), a framework that removes the need for an exact analytic inverse. BiFlow learns a reverse model that approximates the underlying noise-to-data inverse mapping, enabling more flexible loss functions and architectures. Experiments on ImageNet demonstrate that BiFlow, compared to its causal decoding counterpart, improves generation quality while accelerating sampling by up to two orders of magnitude. BiFlow yields state-of-the-art results among NF-based methods and competitive performance among single-evaluation ("1-NFE") methods. Following recent encouraging progress on NFs, we hope our work will draw further attention to this classical paradigm.
ARC Is a Vision Problem!
Nov 18, 2025The Abstraction and Reasoning Corpus (ARC) is designed to promote research on abstract reasoning, a fundamental aspect of human intelligence. Common approaches to ARC treat it as a language-oriented problem, addressed by large language models (LLMs) or recurrent reasoning models. However, although the puzzle-like tasks in ARC are inherently visual, existing research has rarely approached the problem from a vision-centric perspective. In this work, we formulate ARC within a vision paradigm, framing it as an image-to-image translation problem. To incorporate visual priors, we represent the inputs on a "canvas" that can be processed like natural images. It is then natural for us to apply standard vision architectures, such as a vanilla Vision Transformer (ViT), to perform image-to-image mapping. Our model is trained from scratch solely on ARC data and generalizes to unseen tasks through test-time training. Our framework, termed Vision ARC (VARC), achieves 60.4% accuracy on the ARC-1 benchmark, substantially outperforming existing methods that are also trained from scratch. Our results are competitive with those of leading LLMs and close the gap to average human performance.
Back to Basics: Let Denoising Generative Models Denoise
Nov 17, 2025Today's denoising diffusion models do not "denoise" in the classical sense, i.e., they do not directly predict clean images. Rather, the neural networks predict noise or a noised quantity. In this paper, we suggest that predicting clean data and predicting noised quantities are fundamentally different. According to the manifold assumption, natural data should lie on a low-dimensional manifold, whereas noised quantities do not. With this assumption, we advocate for models that directly predict clean data, which allows apparently under-capacity networks to operate effectively in very high-dimensional spaces. We show that simple, large-patch Transformers on pixels can be strong generative models: using no tokenizer, no pre-training, and no extra loss. Our approach is conceptually nothing more than "$\textbf{Just image Transformers}$", or $\textbf{JiT}$, as we call it. We report competitive results using JiT with large patch sizes of 16 and 32 on ImageNet at resolutions of 256 and 512, where predicting high-dimensional noised quantities can fail catastrophically. With our networks mapping back to the basics of the manifold, our research goes back to basics and pursues a self-contained paradigm for Transformer-based diffusion on raw natural data.
Diffuse and Disperse: Image Generation with Representation Regularization
Jun 10, 2025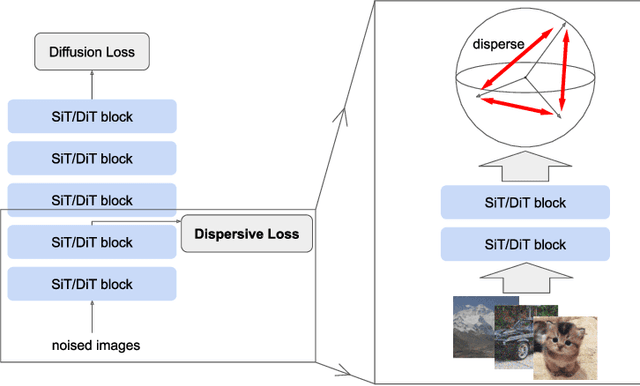

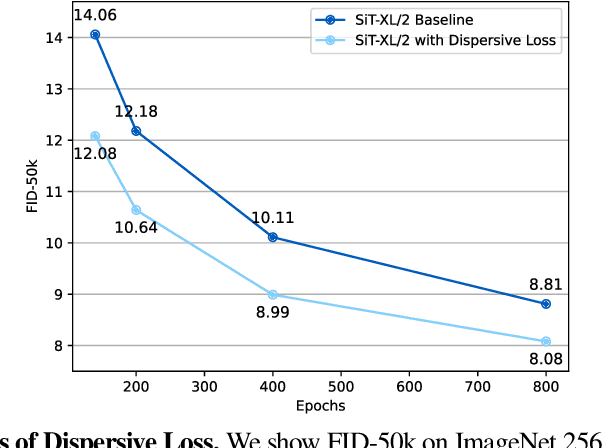
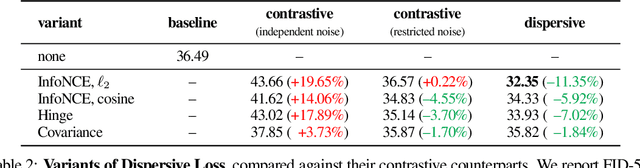
The development of diffusion-based generative models over the past decade has largely proceeded independently of progress in representation learning. These diffusion models typically rely on regression-based objectives and generally lack explicit regularization. In this work, we propose \textit{Dispersive Loss}, a simple plug-and-play regularizer that effectively improves diffusion-based generative models. Our loss function encourages internal representations to disperse in the hidden space, analogous to contrastive self-supervised learning, with the key distinction that it requires no positive sample pairs and therefore does not interfere with the sampling process used for regression. Compared to the recent method of representation alignment (REPA), our approach is self-contained and minimalist, requiring no pre-training, no additional parameters, and no external data. We evaluate Dispersive Loss on the ImageNet dataset across a range of models and report consistent improvements over widely used and strong baselines. We hope our work will help bridge the gap between generative modeling and representation learning.
Mean Flows for One-step Generative Modeling
May 19, 2025We propose a principled and effective framework for one-step generative modeling. We introduce the notion of average velocity to characterize flow fields, in contrast to instantaneous velocity modeled by Flow Matching methods. A well-defined identity between average and instantaneous velocities is derived and used to guide neural network training. Our method, termed the MeanFlow model, is self-contained and requires no pre-training, distillation, or curriculum learning. MeanFlow demonstrates strong empirical performance: it achieves an FID of 3.43 with a single function evaluation (1-NFE) on ImageNet 256x256 trained from scratch, significantly outperforming previous state-of-the-art one-step diffusion/flow models. Our study substantially narrows the gap between one-step diffusion/flow models and their multi-step predecessors, and we hope it will motivate future research to revisit the foundations of these powerful models.
Transformers without Normalization
Mar 13, 2025Normalization layers are ubiquitous in modern neural networks and have long been considered essential. This work demonstrates that Transformers without normalization can achieve the same or better performance using a remarkably simple technique. We introduce Dynamic Tanh (DyT), an element-wise operation $DyT($x$) = \tanh(\alpha $x$)$, as a drop-in replacement for normalization layers in Transformers. DyT is inspired by the observation that layer normalization in Transformers often produces tanh-like, $S$-shaped input-output mappings. By incorporating DyT, Transformers without normalization can match or exceed the performance of their normalized counterparts, mostly without hyperparameter tuning. We validate the effectiveness of Transformers with DyT across diverse settings, ranging from recognition to generation, supervised to self-supervised learning, and computer vision to language models. These findings challenge the conventional understanding that normalization layers are indispensable in modern neural networks, and offer new insights into their role in deep networks.
Denoising Hamiltonian Network for Physical Reasoning
Mar 10, 2025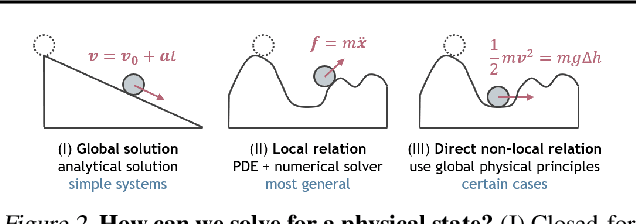
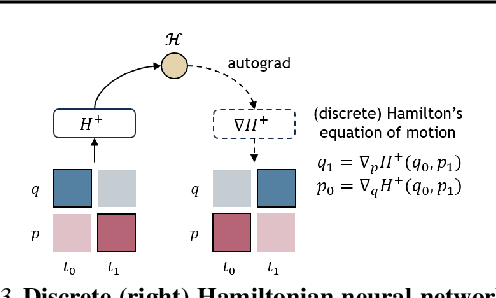
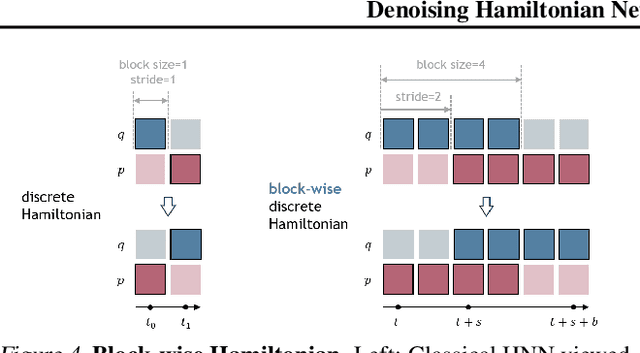
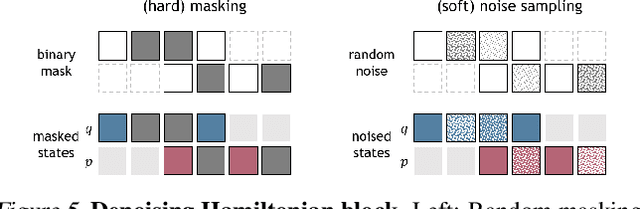
Machine learning frameworks for physical problems must capture and enforce physical constraints that preserve the structure of dynamical systems. Many existing approaches achieve this by integrating physical operators into neural networks. While these methods offer theoretical guarantees, they face two key limitations: (i) they primarily model local relations between adjacent time steps, overlooking longer-range or higher-level physical interactions, and (ii) they focus on forward simulation while neglecting broader physical reasoning tasks. We propose the Denoising Hamiltonian Network (DHN), a novel framework that generalizes Hamiltonian mechanics operators into more flexible neural operators. DHN captures non-local temporal relationships and mitigates numerical integration errors through a denoising mechanism. DHN also supports multi-system modeling with a global conditioning mechanism. We demonstrate its effectiveness and flexibility across three diverse physical reasoning tasks with distinct inputs and outputs.