 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne-step Latent-free Image Generation with Pixel Mean Flows
Jan 29, 2026Modern diffusion/flow-based models for image generation typically exhibit two core characteristics: (i) using multi-step sampling, and (ii) operating in a latent space. Recent advances have made encouraging progress on each aspect individually, paving the way toward one-step diffusion/flow without latents. In this work, we take a further step towards this goal and propose "pixel MeanFlow" (pMF). Our core guideline is to formulate the network output space and the loss space separately. The network target is designed to be on a presumed low-dimensional image manifold (i.e., x-prediction), while the loss is defined via MeanFlow in the velocity space. We introduce a simple transformation between the image manifold and the average velocity field. In experiments, pMF achieves strong results for one-step latent-free generation on ImageNet at 256x256 resolution (2.22 FID) and 512x512 resolution (2.48 FID), filling a key missing piece in this regime. We hope that our study will further advance the boundaries of diffusion/flow-based generative models.
Bidirectional Normalizing Flow: From Data to Noise and Back
Dec 11, 2025Normalizing Flows (NFs) have been established as a principled framework for generative modeling. Standard NFs consist of a forward process and a reverse process: the forward process maps data to noise, while the reverse process generates samples by inverting it. Typical NF forward transformations are constrained by explicit invertibility, ensuring that the reverse process can serve as their exact analytic inverse. Recent developments in TARFlow and its variants have revitalized NF methods by combining Transformers and autoregressive flows, but have also exposed causal decoding as a major bottleneck. In this work, we introduce Bidirectional Normalizing Flow ($\textbf{BiFlow}$), a framework that removes the need for an exact analytic inverse. BiFlow learns a reverse model that approximates the underlying noise-to-data inverse mapping, enabling more flexible loss functions and architectures. Experiments on ImageNet demonstrate that BiFlow, compared to its causal decoding counterpart, improves generation quality while accelerating sampling by up to two orders of magnitude. BiFlow yields state-of-the-art results among NF-based methods and competitive performance among single-evaluation ("1-NFE") methods. Following recent encouraging progress on NFs, we hope our work will draw further attention to this classical paradigm.
Learning Primitive Embodied World Models: Towards Scalable Robotic Learning
Aug 28, 2025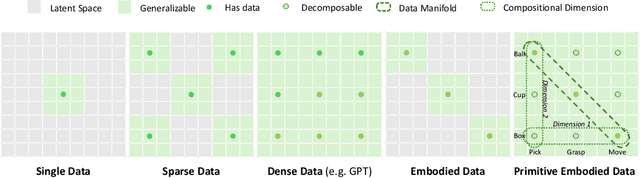



While video-generation-based embodied world models have gained increasing attention, their reliance on large-scale embodied interaction data remains a key bottleneck. The scarcity, difficulty of collection, and high dimensionality of embodied data fundamentally limit the alignment granularity between language and actions and exacerbate the challenge of long-horizon video generation--hindering generative models from achieving a "GPT moment" in the embodied domain. There is a naive observation: the diversity of embodied data far exceeds the relatively small space of possible primitive motions. Based on this insight, we propose a novel paradigm for world modeling--Primitive Embodied World Models (PEWM). By restricting video generation to fixed short horizons, our approach 1) enables fine-grained alignment between linguistic concepts and visual representations of robotic actions, 2) reduces learning complexity, 3) improves data efficiency in embodied data collection, and 4) decreases inference latency. By equipping with a modular Vision-Language Model (VLM) planner and a Start-Goal heatmap Guidance mechanism (SGG), PEWM further enables flexible closed-loop control and supports compositional generalization of primitive-level policies over extended, complex tasks. Our framework leverages the spatiotemporal vision priors in video models and the semantic awareness of VLMs to bridge the gap between fine-grained physical interaction and high-level reasoning, paving the way toward scalable, interpretable, and general-purpose embodied intelligence.
TesserAct: Learning 4D Embodied World Models
Apr 29, 2025



This paper presents an effective approach for learning novel 4D embodied world models, which predict the dynamic evolution of 3D scenes over time in response to an embodied agent's actions, providing both spatial and temporal consistency. We propose to learn a 4D world model by training on RGB-DN (RGB, Depth, and Normal) videos. This not only surpasses traditional 2D models by incorporating detailed shape, configuration, and temporal changes into their predictions, but also allows us to effectively learn accurate inverse dynamic models for an embodied agent. Specifically, we first extend existing robotic manipulation video datasets with depth and normal information leveraging off-the-shelf models. Next, we fine-tune a video generation model on this annotated dataset, which jointly predicts RGB-DN (RGB, Depth, and Normal) for each frame. We then present an algorithm to directly convert generated RGB, Depth, and Normal videos into a high-quality 4D scene of the world. Our method ensures temporal and spatial coherence in 4D scene predictions from embodied scenarios, enables novel view synthesis for embodied environments, and facilitates policy learning that significantly outperforms those derived from prior video-based world models.
Impact of Static Friction on Sim2Real in Robotic Reinforcement Learning
Mar 03, 2025



In robotic reinforcement learning, the Sim2Real gap remains a critical challenge. However, the impact of Static friction on Sim2Real has been underexplored. Conventional domain randomization methods typically exclude Static friction from their parameter space. In our robotic reinforcement learning task, such conventional domain randomization approaches resulted in significantly underperforming real-world models. To address this Sim2Real challenge, we employed Actuator Net as an alternative to conventional domain randomization. While this method enabled successful transfer to flat-ground locomotion, it failed on complex terrains like stairs. To further investigate physical parameters affecting Sim2Real in robotic joints, we developed a control-theoretic joint model and performed systematic parameter identification. Our analysis revealed unexpectedly high friction-torque ratios in our robotic joints. To mitigate its impact, we implemented Static friction-aware domain randomization for Sim2Real. Recognizing the increased training difficulty introduced by friction modeling, we proposed a simple and novel solution to reduce learning complexity. To validate this approach, we conducted comprehensive Sim2Sim and Sim2Real experiments comparing three methods: conventional domain randomization (without Static friction), Actuator Net, and our Static friction-aware domain randomization. All experiments utilized the Rapid Motor Adaptation (RMA) algorithm. Results demonstrated that our method achieved superior adaptive capabilities and overall performance.
Is Noise Conditioning Necessary for Denoising Generative Models?
Feb 18, 2025



It is widely believed that noise conditioning is indispensable for denoising diffusion models to work successfully. This work challenges this belief. Motivated by research on blind image denoising, we investigate a variety of denoising-based generative models in the absence of noise conditioning. To our surprise, most models exhibit graceful degradation, and in some cases, they even perform better without noise conditioning. We provide a theoretical analysis of the error caused by removing noise conditioning and demonstrate that our analysis aligns with empirical observations. We further introduce a noise-unconditional model that achieves a competitive FID of 2.23 on CIFAR-10, significantly narrowing the gap to leading noise-conditional models. We hope our findings will inspire the community to revisit the foundations and formulations of denoising generative models.
Enhancing Nursing and Elderly Care with Large Language Models: An AI-Driven Framework
Dec 13, 2024



This paper explores the application of large language models (LLMs) in nursing and elderly care, focusing on AI-driven patient monitoring and interaction. We introduce a novel Chinese nursing dataset and implement incremental pre-training (IPT) and supervised fine-tuning (SFT) techniques to enhance LLM performance in specialized tasks. Using LangChain, we develop a dynamic nursing assistant capable of real-time care and personalized interventions. Experimental results demonstrate significant improvements, paving the way for AI-driven solutions to meet the growing demands of healthcare in aging populations.
Grasp Diffusion Network: Learning Grasp Generators from Partial Point Clouds with Diffusion Models in SO(3)xR3
Dec 11, 2024



Grasping objects successfully from a single-view camera is crucial in many robot manipulation tasks. An approach to solve this problem is to leverage simulation to create large datasets of pairs of objects and grasp poses, and then learn a conditional generative model that can be prompted quickly during deployment. However, the grasp pose data is highly multimodal since there are several ways to grasp an object. Hence, in this work, we learn a grasp generative model with diffusion models to sample candidate grasp poses given a partial point cloud of an object. A novel aspect of our method is to consider diffusion in the manifold space of rotations and to propose a collision-avoidance cost guidance to improve the grasp success rate during inference. To accelerate grasp sampling we use recent techniques from the diffusion literature to achieve faster inference times. We show in simulation and real-world experiments that our approach can grasp several objects from raw depth images with $90\%$ success rate and benchmark it against several baselines.
Synergistic Development of Perovskite Memristors and Algorithms for Robust Analog Computing
Dec 03, 2024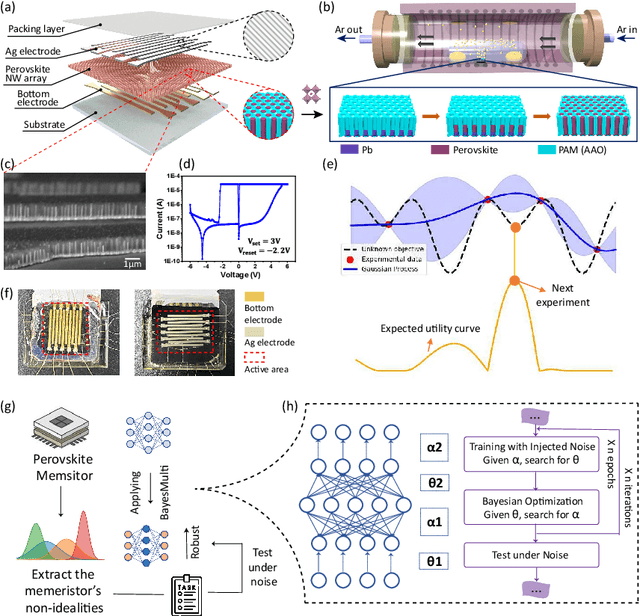

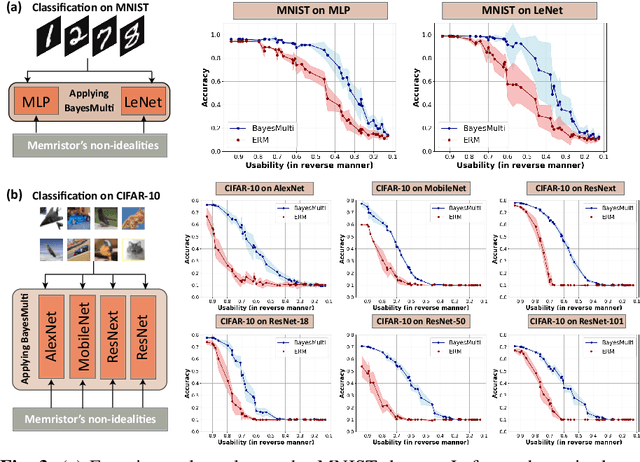
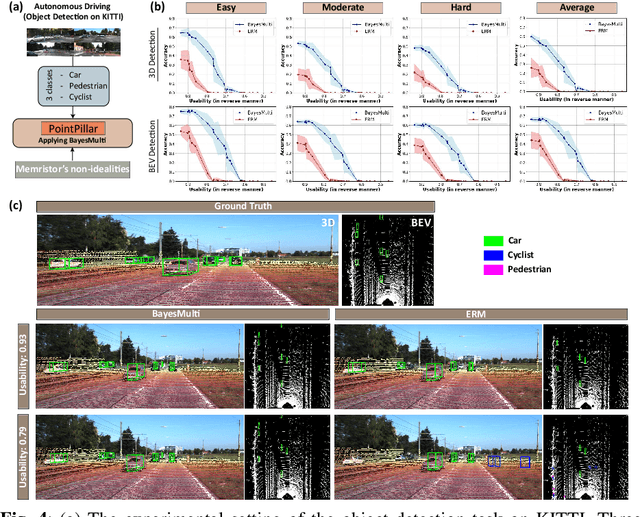
Analog computing using non-volatile memristors has emerged as a promising solution for energy-efficient deep learning. New materials, like perovskites-based memristors are recently attractive due to their cost-effectiveness, energy efficiency and flexibility. Yet, challenges in material diversity and immature fabrications require extensive experimentation for device development. Moreover, significant non-idealities in these memristors often impede them for computing. Here, we propose a synergistic methodology to concurrently optimize perovskite memristor fabrication and develop robust analog DNNs that effectively address the inherent non-idealities of these memristors. Employing Bayesian optimization (BO) with a focus on usability, we efficiently identify optimal materials and fabrication conditions for perovskite memristors. Meanwhile, we developed "BayesMulti", a DNN training strategy utilizing BO-guided noise injection to improve the resistance of analog DNNs to memristor imperfections. Our approach theoretically ensures that within a certain range of parameter perturbations due to memristor non-idealities, the prediction outcomes remain consistent. Our integrated approach enables use of analog computing in much deeper and wider networks, which significantly outperforms existing methods in diverse tasks like image classification, autonomous driving, species identification, and large vision-language models, achieving up to 100-fold improvements. We further validate our methodology on a 10$\times$10 optimized perovskite memristor crossbar, demonstrating high accuracy in a classification task and low energy consumption. This study offers a versatile solution for efficient optimization of various analog computing systems, encompassing both devices and algorithms.
Generalizing Motion Planners with Mixture of Experts for Autonomous Driving
Oct 21, 2024



Large real-world driving datasets have sparked significant research into various aspects of data-driven motion planners for autonomous driving. These include data augmentation, model architecture, reward design, training strategies, and planner pipelines. These planners promise better generalizations on complicated and few-shot cases than previous methods. However, experiment results show that many of these approaches produce limited generalization abilities in planning performance due to overly complex designs or training paradigms. In this paper, we review and benchmark previous methods focusing on generalizations. The experimental results indicate that as models are appropriately scaled, many design elements become redundant. We introduce StateTransformer-2 (STR2), a scalable, decoder-only motion planner that uses a Vision Transformer (ViT) encoder and a mixture-of-experts (MoE) causal Transformer architecture. The MoE backbone addresses modality collapse and reward balancing by expert routing during training. Extensive experiments on the NuPlan dataset show that our method generalizes better than previous approaches across different test sets and closed-loop simulations. Furthermore, we assess its scalability on billions of real-world urban driving scenarios, demonstrating consistent accuracy improvements as both data and model size grow.