 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Primitive Embodied World Models: Towards Scalable Robotic Learning
Aug 28, 2025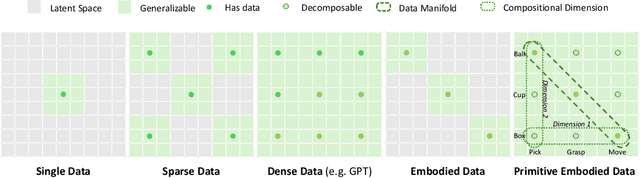



While video-generation-based embodied world models have gained increasing attention, their reliance on large-scale embodied interaction data remains a key bottleneck. The scarcity, difficulty of collection, and high dimensionality of embodied data fundamentally limit the alignment granularity between language and actions and exacerbate the challenge of long-horizon video generation--hindering generative models from achieving a "GPT moment" in the embodied domain. There is a naive observation: the diversity of embodied data far exceeds the relatively small space of possible primitive motions. Based on this insight, we propose a novel paradigm for world modeling--Primitive Embodied World Models (PEWM). By restricting video generation to fixed short horizons, our approach 1) enables fine-grained alignment between linguistic concepts and visual representations of robotic actions, 2) reduces learning complexity, 3) improves data efficiency in embodied data collection, and 4) decreases inference latency. By equipping with a modular Vision-Language Model (VLM) planner and a Start-Goal heatmap Guidance mechanism (SGG), PEWM further enables flexible closed-loop control and supports compositional generalization of primitive-level policies over extended, complex tasks. Our framework leverages the spatiotemporal vision priors in video models and the semantic awareness of VLMs to bridge the gap between fine-grained physical interaction and high-level reasoning, paving the way toward scalable, interpretable, and general-purpose embodied intelligence.
InfoBound: A Provable Information-Bounds Inspired Framework for Both OoD Generalization and OoD Detection
Apr 13, 2025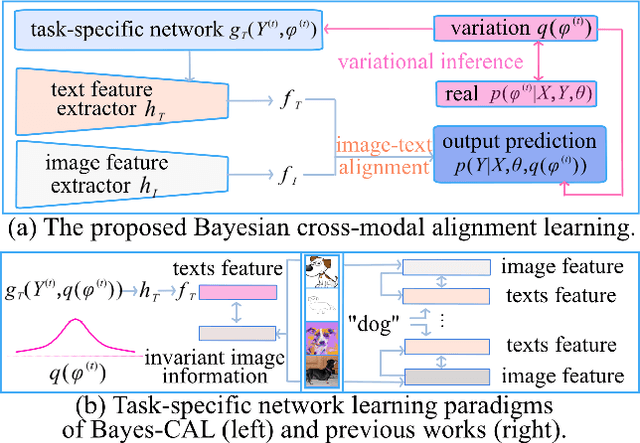
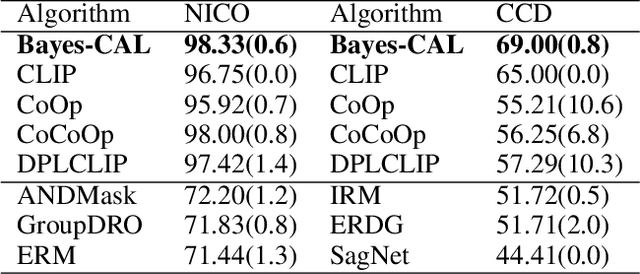
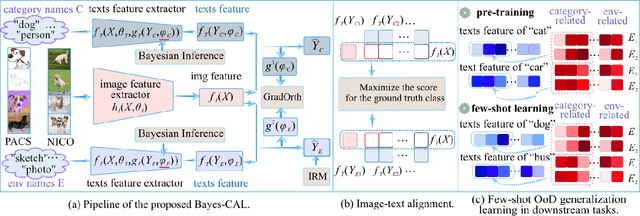
In real-world scenarios, distribution shifts give rise to the importance of two problems: out-of-distribution (OoD) generalization, which focuses on models' generalization ability against covariate shifts (i.e., the changes of environments), and OoD detection, which aims to be aware of semantic shifts (i.e., test-time unseen classes). Real-world testing environments often involve a combination of both covariate and semantic shifts. While numerous methods have been proposed to address these critical issues, only a few works tackled them simultaneously. Moreover, prior works often improve one problem but sacrifice the other. To overcome these limitations, we delve into boosting OoD detection and OoD generalization from the perspective of information theory, which can be easily applied to existing models and different tasks. Building upon the theoretical bounds for mutual information and conditional entropy, we provide a unified approach, composed of Mutual Information Minimization (MI-Min) and Conditional Entropy Maximizing (CE-Max). Extensive experiments and comprehensive evaluations on multi-label image classification and object detection have demonstrated the superiority of our method. It successfully mitigates trade-offs between the two challenges compared to competitive baselines.
Decision SpikeFormer: Spike-Driven Transformer for Decision Making
Apr 04, 2025


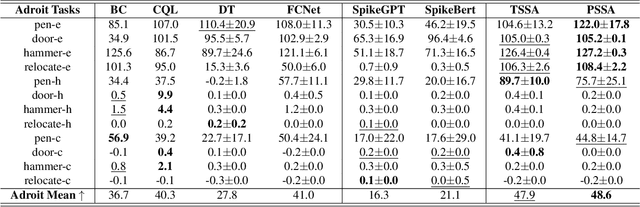
Offline reinforcement learning (RL) enables policy training solely on pre-collected data, avoiding direct environment interaction - a crucial benefit for energy-constrained embodied AI applications. Although Artificial Neural Networks (ANN)-based methods perform well in offline RL, their high computational and energy demands motivate exploration of more efficient alternatives. Spiking Neural Networks (SNNs) show promise for such tasks, given their low power consumption. In this work, we introduce DSFormer, the first spike-driven transformer model designed to tackle offline RL via sequence modeling. Unlike existing SNN transformers focused on spatial dimensions for vision tasks, we develop Temporal Spiking Self-Attention (TSSA) and Positional Spiking Self-Attention (PSSA) in DSFormer to capture the temporal and positional dependencies essential for sequence modeling in RL. Additionally, we propose Progressive Threshold-dependent Batch Normalization (PTBN), which combines the benefits of LayerNorm and BatchNorm to preserve temporal dependencies while maintaining the spiking nature of SNNs. Comprehensive results in the D4RL benchmark show DSFormer's superiority over both SNN and ANN counterparts, achieving 78.4% energy savings, highlighting DSFormer's advantages not only in energy efficiency but also in competitive performance. Code and models are public at https://wei-nijuan.github.io/DecisionSpikeFormer.
Visual Position Prompt for MLLM based Visual Grounding
Mar 19, 2025Although Multimodal Large Language Models (MLLMs) excel at various image-related tasks, they encounter challenges in precisely aligning coordinates with spatial information within images, particularly in position-aware tasks such as visual grounding. This limitation arises from two key factors. First, MLLMs lack explicit spatial references, making it difficult to associate textual descriptions with precise image locations. Second, their feature extraction processes prioritize global context over fine-grained spatial details, leading to weak localization capability. To address this issue, we introduce VPP-LLaVA, an MLLM equipped with Visual Position Prompt (VPP) to improve its grounding capability. VPP-LLaVA integrates two complementary mechanisms. The global VPP overlays learnable, axis-like embeddings onto the input image to provide structured spatial cues. The local VPP focuses on fine-grained localization by incorporating position-aware queries, which suggests probable object locations. We also introduce a VPP-SFT dataset with 0.6M samples, consolidating high-quality visual grounding data into a compact format for efficient model training. Training on this dataset with VPP enhances the model's performance, achieving state-of-the-art results on standard grounding benchmarks despite using fewer training samples compared to other MLLMs like MiniGPT-v2, which rely on much larger datasets ($\sim$21M samples). The code and VPP-SFT dataset will be available at https://github.com/WayneTomas/VPP-LLaVA upon acceptance.
OODD: Test-time Out-of-Distribution Detection with Dynamic Dictionary
Mar 13, 2025



Out-of-distribution (OOD) detection remains challenging for deep learning models, particularly when test-time OOD samples differ significantly from training outliers. We propose OODD, a novel test-time OOD detection method that dynamically maintains and updates an OOD dictionary without fine-tuning. Our approach leverages a priority queue-based dictionary that accumulates representative OOD features during testing, combined with an informative inlier sampling strategy for in-distribution (ID) samples. To ensure stable performance during early testing, we propose a dual OOD stabilization mechanism that leverages strategically generated outliers derived from ID data. To our best knowledge, extensive experiments on the OpenOOD benchmark demonstrate that OODD significantly outperforms existing methods, achieving a 26.0% improvement in FPR95 on CIFAR-100 Far OOD detection compared to the state-of-the-art approach. Furthermore, we present an optimized variant of the KNN-based OOD detection framework that achieves a 3x speedup while maintaining detection performance.
Less is More: Masking Elements in Image Condition Features Avoids Content Leakages in Style Transfer Diffusion Models
Feb 11, 2025Given a style-reference image as the additional image condition, text-to-image diffusion models have demonstrated impressive capabilities in generating images that possess the content of text prompts while adopting the visual style of the reference image. However, current state-of-the-art methods often struggle to disentangle content and style from style-reference images, leading to issues such as content leakages. To address this issue, we propose a masking-based method that efficiently decouples content from style without the need of tuning any model parameters. By simply masking specific elements in the style reference's image features, we uncover a critical yet under-explored principle: guiding with appropriately-selected fewer conditions (e.g., dropping several image feature elements) can efficiently avoid unwanted content flowing into the diffusion models, enhancing the style transfer performances of text-to-image diffusion models. In this paper, we validate this finding both theoretically and experimentally. Extensive experiments across various styles demonstrate the effectiveness of our masking-based method and support our theoretical results.
Enhancing Nursing and Elderly Care with Large Language Models: An AI-Driven Framework
Dec 13, 2024



This paper explores the application of large language models (LLMs) in nursing and elderly care, focusing on AI-driven patient monitoring and interaction. We introduce a novel Chinese nursing dataset and implement incremental pre-training (IPT) and supervised fine-tuning (SFT) techniques to enhance LLM performance in specialized tasks. Using LangChain, we develop a dynamic nursing assistant capable of real-time care and personalized interventions. Experimental results demonstrate significant improvements, paving the way for AI-driven solutions to meet the growing demands of healthcare in aging populations.
Synergistic Development of Perovskite Memristors and Algorithms for Robust Analog Computing
Dec 03, 2024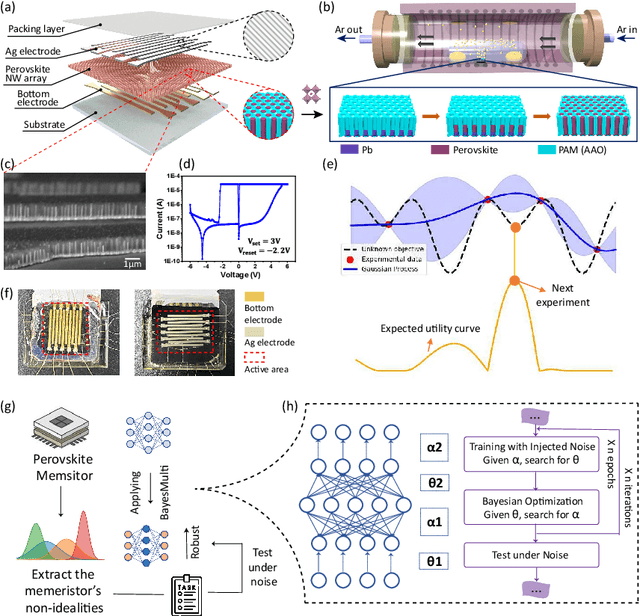

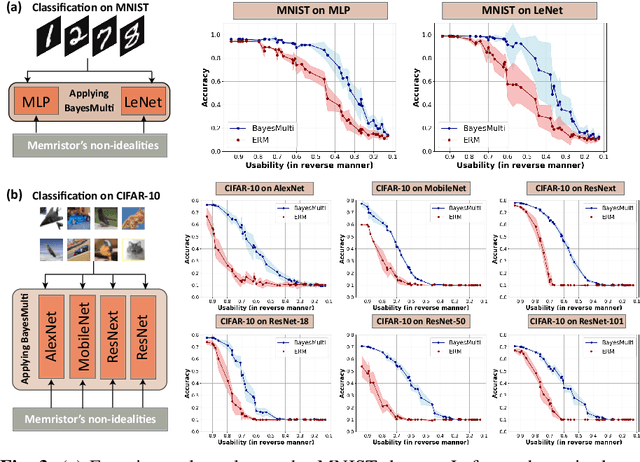
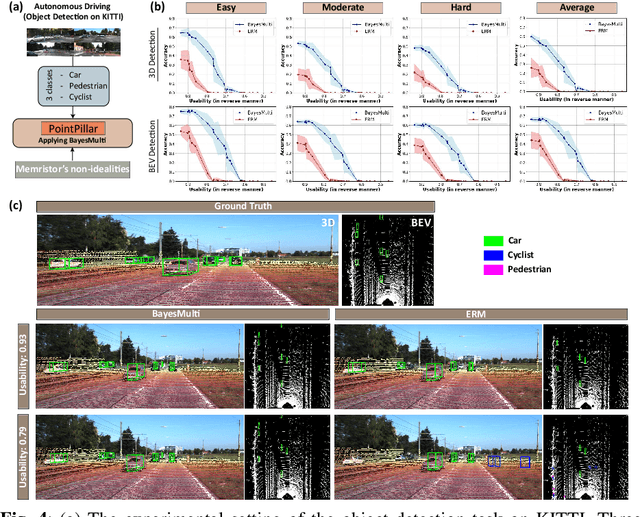
Analog computing using non-volatile memristors has emerged as a promising solution for energy-efficient deep learning. New materials, like perovskites-based memristors are recently attractive due to their cost-effectiveness, energy efficiency and flexibility. Yet, challenges in material diversity and immature fabrications require extensive experimentation for device development. Moreover, significant non-idealities in these memristors often impede them for computing. Here, we propose a synergistic methodology to concurrently optimize perovskite memristor fabrication and develop robust analog DNNs that effectively address the inherent non-idealities of these memristors. Employing Bayesian optimization (BO) with a focus on usability, we efficiently identify optimal materials and fabrication conditions for perovskite memristors. Meanwhile, we developed "BayesMulti", a DNN training strategy utilizing BO-guided noise injection to improve the resistance of analog DNNs to memristor imperfections. Our approach theoretically ensures that within a certain range of parameter perturbations due to memristor non-idealities, the prediction outcomes remain consistent. Our integrated approach enables use of analog computing in much deeper and wider networks, which significantly outperforms existing methods in diverse tasks like image classification, autonomous driving, species identification, and large vision-language models, achieving up to 100-fold improvements. We further validate our methodology on a 10$\times$10 optimized perovskite memristor crossbar, demonstrating high accuracy in a classification task and low energy consumption. This study offers a versatile solution for efficient optimization of various analog computing systems, encompassing both devices and algorithms.
MiniConGTS: A Near Ultimate Minimalist Contrastive Grid Tagging Scheme for Aspect Sentiment Triplet Extraction
Jun 17, 2024



Aspect Sentiment Triplet Extraction (ASTE) aims to co-extract the sentiment triplets in a given corpus. Existing approaches within the pretraining-finetuning paradigm tend to either meticulously craft complex tagging schemes and classification heads, or incorporate external semantic augmentation to enhance performance. In this study, we, for the first time, re-evaluate the redundancy in tagging schemes and the internal enhancement in pretrained representations. We propose a method to improve and utilize pretrained representations by integrating a minimalist tagging scheme and a novel token-level contrastive learning strategy. The proposed approach demonstrates comparable or superior performance compared to state-of-the-art techniques while featuring a more compact design and reduced computational overhead. Additionally, we are the first to formally evaluate GPT-4's performance in few-shot learning and Chain-of-Thought scenarios for this task. The results demonstrate that the pretraining-finetuning paradigm remains highly effective even in the era of large language models.
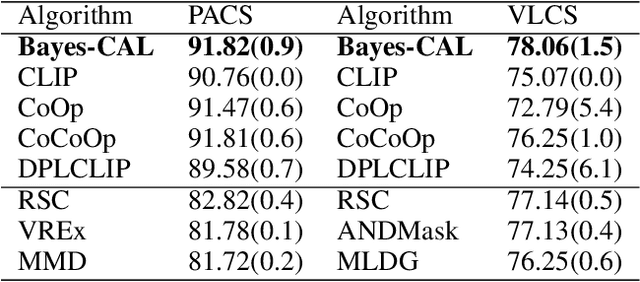
CRoFT: Robust Fine-Tuning with Concurrent Optimization for OOD Generalization and Open-Set OOD Detection
May 26, 2024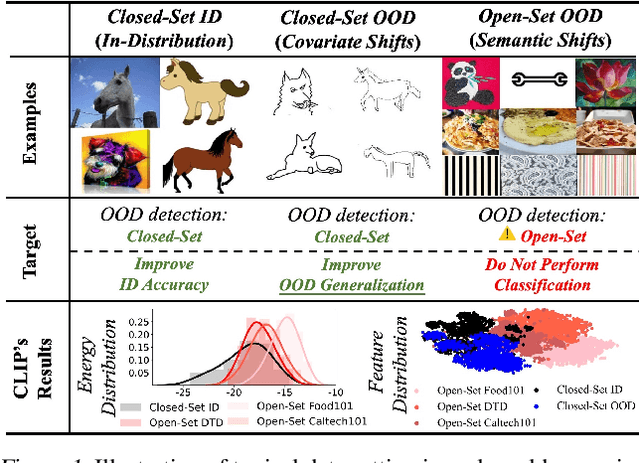



Recent vision-language pre-trained models (VL-PTMs) have shown remarkable success in open-vocabulary tasks. However, downstream use cases often involve further fine-tuning of VL-PTMs, which may distort their general knowledge and impair their ability to handle distribution shifts. In real-world scenarios, machine learning systems inevitably encounter both covariate shifts (e.g., changes in image styles) and semantic shifts (e.g., test-time unseen classes). This highlights the importance of enhancing out-of-distribution (OOD) generalization on covariate shifts and simultaneously detecting semantic-shifted unseen classes. Thus a critical but underexplored question arises: How to improve VL-PTMs' generalization ability to closed-set OOD data, while effectively detecting open-set unseen classes during fine-tuning? In this paper, we propose a novel objective function of OOD detection that also serves to improve OOD generalization. We show that minimizing the gradient magnitude of energy scores on training data leads to domain-consistent Hessians of classification loss, a strong indicator for OOD generalization revealed by theoretical analysis. Based on this finding, we have developed a unified fine-tuning framework that allows for concurrent optimization of both tasks. Extensive experiments have demonstrated the superiority of our method. The code is available at https://github.com/LinLLLL/CRoFT.