 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Better Dental AI: A Multimodal Benchmark and Instruction Dataset for Panoramic X-ray Analysis
Sep 11, 2025



Recent advances in large vision-language models (LVLMs) have demonstrated strong performance on general-purpose medical tasks. However, their effectiveness in specialized domains such as dentistry remains underexplored. In particular, panoramic X-rays, a widely used imaging modality in oral radiology, pose interpretative challenges due to dense anatomical structures and subtle pathological cues, which are not captured by existing medical benchmarks or instruction datasets. To this end, we introduce MMOral, the first large-scale multimodal instruction dataset and benchmark tailored for panoramic X-ray interpretation. MMOral consists of 20,563 annotated images paired with 1.3 million instruction-following instances across diverse task types, including attribute extraction, report generation, visual question answering, and image-grounded dialogue. In addition, we present MMOral-Bench, a comprehensive evaluation suite covering five key diagnostic dimensions in dentistry. We evaluate 64 LVLMs on MMOral-Bench and find that even the best-performing model, i.e., GPT-4o, only achieves 41.45% accuracy, revealing significant limitations of current models in this domain. To promote the progress of this specific domain, we also propose OralGPT, which conducts supervised fine-tuning (SFT) upon Qwen2.5-VL-7B with our meticulously curated MMOral instruction dataset. Remarkably, a single epoch of SFT yields substantial performance enhancements for LVLMs, e.g., OralGPT demonstrates a 24.73% improvement. Both MMOral and OralGPT hold significant potential as a critical foundation for intelligent dentistry and enable more clinically impactful multimodal AI systems in the dental field. The dataset, model, benchmark, and evaluation suite are available at https://github.com/isbrycee/OralGPT.
DeRIS: Decoupling Perception and Cognition for Enhanced Referring Image Segmentation through Loopback Synergy
Jul 02, 2025Referring Image Segmentation (RIS) is a challenging task that aims to segment objects in an image based on natural language expressions. While prior studies have predominantly concentrated on improving vision-language interactions and achieving fine-grained localization, a systematic analysis of the fundamental bottlenecks in existing RIS frameworks remains underexplored. To bridge this gap, we propose DeRIS, a novel framework that decomposes RIS into two key components: perception and cognition. This modular decomposition facilitates a systematic analysis of the primary bottlenecks impeding RIS performance. Our findings reveal that the predominant limitation lies not in perceptual deficiencies, but in the insufficient multi-modal cognitive capacity of current models. To mitigate this, we propose a Loopback Synergy mechanism, which enhances the synergy between the perception and cognition modules, thereby enabling precise segmentation while simultaneously improving robust image-text comprehension. Additionally, we analyze and introduce a simple non-referent sample conversion data augmentation to address the long-tail distribution issue related to target existence judgement in general scenarios. Notably, DeRIS demonstrates inherent adaptability to both non- and multi-referents scenarios without requiring specialized architectural modifications, enhancing its general applicability. The codes and models are available at https://github.com/Dmmm1997/DeRIS.
MATHGLANCE: Multimodal Large Language Models Do Not Know Where to Look in Mathematical Diagrams
Mar 26, 2025Diagrams serve as a fundamental form of visual language, representing complex concepts and their inter-relationships through structured symbols, shapes, and spatial arrangements. Unlike natural images, their inherently symbolic and abstract nature poses significant challenges for Multimodal Large Language Models (MLLMs). However, current benchmarks conflate perceptual and reasoning tasks, making it difficult to assess whether MLLMs genuinely understand mathematical diagrams beyond superficial pattern recognition. To address this gap, we introduce MATHGLANCE, a benchmark specifically designed to isolate and evaluate mathematical perception in MLLMs. MATHGLANCE comprises 1.2K images and 1.6K carefully curated questions spanning four perception tasks: shape classification, object counting, relationship identification, and object grounding, covering diverse domains including plane geometry, solid geometry, and graphical representations. Our evaluation of MLLMs reveals that their ability to understand diagrams is notably limited, particularly in fine-grained grounding tasks. In response, we construct GeoPeP, a perception-oriented dataset of 200K structured geometry image-text pairs explicitly annotated with geometric primitives and precise spatial relationships. Training MLLM on GeoPeP leads to significant gains in perceptual accuracy, which in turn substantially improves mathematical reasoning. Our benchmark and dataset establish critical standards for evaluating and advancing multimodal mathematical understanding, providing valuable resources and insights to foster future MLLM research.
Visual Position Prompt for MLLM based Visual Grounding
Mar 19, 2025Although Multimodal Large Language Models (MLLMs) excel at various image-related tasks, they encounter challenges in precisely aligning coordinates with spatial information within images, particularly in position-aware tasks such as visual grounding. This limitation arises from two key factors. First, MLLMs lack explicit spatial references, making it difficult to associate textual descriptions with precise image locations. Second, their feature extraction processes prioritize global context over fine-grained spatial details, leading to weak localization capability. To address this issue, we introduce VPP-LLaVA, an MLLM equipped with Visual Position Prompt (VPP) to improve its grounding capability. VPP-LLaVA integrates two complementary mechanisms. The global VPP overlays learnable, axis-like embeddings onto the input image to provide structured spatial cues. The local VPP focuses on fine-grained localization by incorporating position-aware queries, which suggests probable object locations. We also introduce a VPP-SFT dataset with 0.6M samples, consolidating high-quality visual grounding data into a compact format for efficient model training. Training on this dataset with VPP enhances the model's performance, achieving state-of-the-art results on standard grounding benchmarks despite using fewer training samples compared to other MLLMs like MiniGPT-v2, which rely on much larger datasets ($\sim$21M samples). The code and VPP-SFT dataset will be available at https://github.com/WayneTomas/VPP-LLaVA upon acceptance.
Open Eyes, Then Reason: Fine-grained Visual Mathematical Understanding in MLLMs
Jan 11, 2025



Current multimodal large language models (MLLMs) often underperform on mathematical problem-solving tasks that require fine-grained visual understanding. The limitation is largely attributable to inadequate perception of geometric primitives during image-level contrastive pre-training (e.g., CLIP). While recent efforts to improve math MLLMs have focused on scaling up mathematical visual instruction datasets and employing stronger LLM backbones, they often overlook persistent errors in visual recognition. In this paper, we systematically evaluate the visual grounding capabilities of state-of-the-art MLLMs and reveal a significant negative correlation between visual grounding accuracy and problem-solving performance, underscoring the critical role of fine-grained visual understanding. Notably, advanced models like GPT-4o exhibit a 70% error rate when identifying geometric entities, highlighting that this remains a key bottleneck in visual mathematical reasoning. To address this, we propose a novel approach, SVE-Math (Selective Vision-Enhanced Mathematical MLLM), featuring a geometric-grounded vision encoder and a feature router that dynamically adjusts the contribution of hierarchical visual feature maps. Our model recognizes accurate visual primitives and generates precise visual prompts tailored to the language model's reasoning needs. In experiments, SVE-Math-Qwen2.5-7B outperforms other 7B models by 15% on MathVerse and is compatible with GPT-4V on MathVista. Despite being trained on smaller datasets, SVE-Math-7B achieves competitive performance on GeoQA, rivaling models trained on significantly larger datasets. Our findings emphasize the importance of incorporating fine-grained visual understanding into MLLMs and provide a promising direction for future research.
Descriptive Caption Enhancement with Visual Specialists for Multimodal Perception
Dec 18, 2024



Training Large Multimodality Models (LMMs) relies on descriptive image caption that connects image and language. Existing methods either distill the caption from the LMM models or construct the captions from the internet images or by human. We propose to leverage off-the-shelf visual specialists, which were trained from annotated images initially not for image captioning, for enhancing the image caption. Our approach, named DCE, explores object low-level and fine-grained attributes (e.g., depth, emotion and fine-grained categories) and object relations (e.g., relative location and human-object-interaction (HOI)), and combine the attributes into the descriptive caption. Experiments demonstrate that such visual specialists are able to improve the performance for visual understanding tasks as well as reasoning that benefits from more accurate visual understanding. We will release the source code and the pipeline so that other visual specialists are easily combined into the pipeline. The complete source code of DCE pipeline and datasets will be available at \url{https://github.com/syp2ysy/DCE}.
Continual SFT Matches Multimodal RLHF with Negative Supervision
Nov 22, 2024
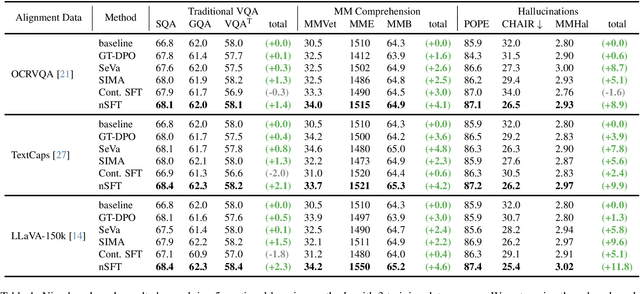
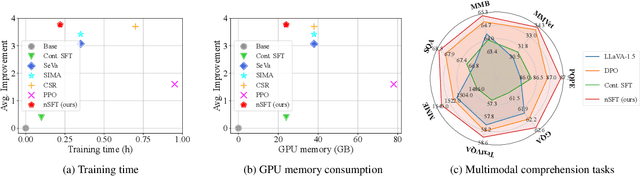
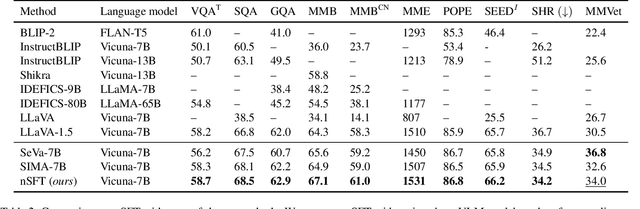
Multimodal RLHF usually happens after supervised finetuning (SFT) stage to continually improve vision-language models' (VLMs) comprehension. Conventional wisdom holds its superiority over continual SFT during this preference alignment stage. In this paper, we observe that the inherent value of multimodal RLHF lies in its negative supervision, the logit of the rejected responses. We thus propose a novel negative supervised finetuning (nSFT) approach that fully excavates these information resided. Our nSFT disentangles this negative supervision in RLHF paradigm, and continually aligns VLMs with a simple SFT loss. This is more memory efficient than multimodal RLHF where 2 (e.g., DPO) or 4 (e.g., PPO) large VLMs are strictly required. The effectiveness of nSFT is rigorously proved by comparing it with various multimodal RLHF approaches, across different dataset sources, base VLMs and evaluation metrics. Besides, fruitful of ablations are provided to support our hypothesis. We hope this paper will stimulate further research to properly align large vision language models.
Improving Multi-modal Large Language Model through Boosting Vision Capabilities
Oct 17, 2024



We focus on improving the visual understanding capability for boosting the vision-language models. We propose \textbf{Arcana}, a multiModal language model, which introduces two crucial techniques. First, we present Multimodal LoRA (MM-LoRA), a module designed to enhance the decoder. Unlike traditional language-driven decoders, MM-LoRA consists of two parallel LoRAs -- one for vision and one for language -- each with its own parameters. This disentangled parameters design allows for more specialized learning in each modality and better integration of multimodal information. Second, we introduce the Query Ladder adapter (QLadder) to improve the visual encoder. QLadder employs a learnable ``\textit{ladder}'' structure to deeply aggregates the intermediate representations from the frozen pretrained visual encoder (e.g., CLIP image encoder). This enables the model to learn new and informative visual features, as well as remaining the powerful capabilities of the pretrained visual encoder. These techniques collectively enhance Arcana's visual perception power, enabling it to leverage improved visual information for more accurate and contextually relevant outputs across various multimodal scenarios. Extensive experiments and ablation studies demonstrate the effectiveness and generalization capability of our Arcana. The code and re-annotated data are available at \url{https://arcana-project-page.github.io}.
CSGO: Content-Style Composition in Text-to-Image Generation
Sep 04, 2024

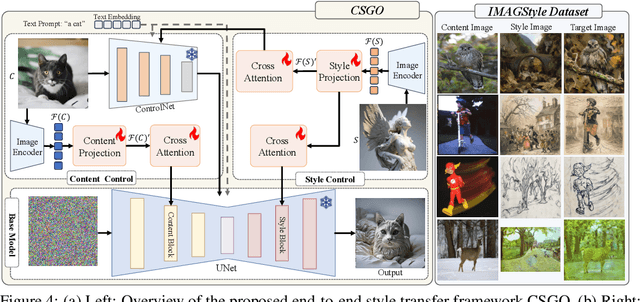
The diffusion model has shown exceptional capabilities in controlled image generation, which has further fueled interest in image style transfer. Existing works mainly focus on training free-based methods (e.g., image inversion) due to the scarcity of specific data. In this study, we present a data construction pipeline for content-style-stylized image triplets that generates and automatically cleanses stylized data triplets. Based on this pipeline, we construct a dataset IMAGStyle, the first large-scale style transfer dataset containing 210k image triplets, available for the community to explore and research. Equipped with IMAGStyle, we propose CSGO, a style transfer model based on end-to-end training, which explicitly decouples content and style features employing independent feature injection. The unified CSGO implements image-driven style transfer, text-driven stylized synthesis, and text editing-driven stylized synthesis. Extensive experiments demonstrate the effectiveness of our approach in enhancing style control capabilities in image generation. Additional visualization and access to the source code can be located on the project page: \url{https://csgo-gen.github.io/}.
VRP-SAM: SAM with Visual Reference Prompt
Feb 27, 2024



In this paper, we propose a novel Visual Reference Prompt (VRP) encoder that empowers the Segment Anything Model (SAM) to utilize annotated reference images as prompts for segmentation, creating the VRP-SAM model. In essence, VRP-SAM can utilize annotated reference images to comprehend specific objects and perform segmentation of specific objects in target image. It is note that the VRP encoder can support a variety of annotation formats for reference images, including \textbf{point}, \textbf{box}, \textbf{scribble}, and \textbf{mask}. VRP-SAM achieves a breakthrough within the SAM framework by extending its versatility and applicability while preserving SAM's inherent strengths, thus enhancing user-friendliness. To enhance the generalization ability of VRP-SAM, the VRP encoder adopts a meta-learning strategy. To validate the effectiveness of VRP-SAM, we conducted extensive empirical studies on the Pascal and COCO datasets. Remarkably, VRP-SAM achieved state-of-the-art performance in visual reference segmentation with minimal learnable parameters. Furthermore, VRP-SAM demonstrates strong generalization capabilities, allowing it to perform segmentation of unseen objects and enabling cross-domain segmentation.