 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArticulation in Motion: Prior-free Part Mobility Analysis for Articulated Objects By Dynamic-Static Disentanglement
Mar 03, 2026Articulated objects are ubiquitous in daily life. Our goal is to achieve a high-quality reconstruction, segmentation of independent moving parts, and analysis of articulation. Recent methods analyse two different articulation states and perform per-point part segmentation, optimising per-part articulation using cross-state correspondences, given a priori knowledge of the number of parts. Such assumptions greatly limit their applications and performance. Their robustness is reduced when objects cannot be clearly visible in both states. To address these issues, in this paper, we present a new framework, Articulation in Motion (AiM). We infer part-level decomposition, articulation kinematics, and reconstruct an interactive 3D digital replica from a user-object interaction video and a start-state scan. We propose a dual-Gaussian scene representation that is learned from an initial 3DGS scan of the object and a video that shows the movement of separate parts. It uses motion cues to segment the object into parts and assign articulation joints. Subsequently, a robust, sequential RANSAC is employed to achieve part mobility analysis without any part-level structural priors, which clusters moving primitives into rigid parts and estimates kinematics while automatically determining the number of parts. The proposed approach separates the object into parts, each represented as a 3D Gaussian set, enabling high-quality rendering. Our approach yields higher quality part segmentation than previous methods, without prior knowledge. Extensive experimental analysis on both simple and complex objects validates the effectiveness and strong generalisation ability of our approach. Project page: https://haoai-1997.github.io/AiM/.
Structure-Aware Feature Rectification with Region Adjacency Graphs for Training-Free Open-Vocabulary Semantic Segmentation
Dec 08, 2025

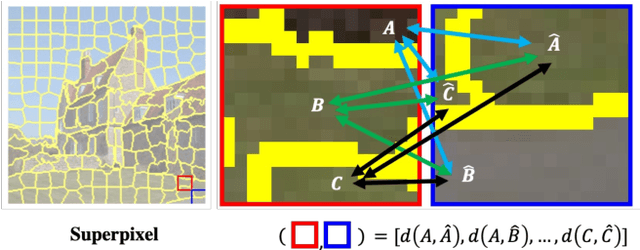

Benefiting from the inductive biases learned from large-scale datasets, open-vocabulary semantic segmentation (OVSS) leverages the power of vision-language models, such as CLIP, to achieve remarkable progress without requiring task-specific training. However, due to CLIP's pre-training nature on image-text pairs, it tends to focus on global semantic alignment, resulting in suboptimal performance when associating fine-grained visual regions with text. This leads to noisy and inconsistent predictions, particularly in local areas. We attribute this to a dispersed bias stemming from its contrastive training paradigm, which is difficult to alleviate using CLIP features alone. To address this, we propose a structure-aware feature rectification approach that incorporates instance-specific priors derived directly from the image. Specifically, we construct a region adjacency graph (RAG) based on low-level features (e.g., colour and texture) to capture local structural relationships and use it to refine CLIP features by enhancing local discrimination. Extensive experiments show that our method effectively suppresses segmentation noise, improves region-level consistency, and achieves strong performance on multiple open-vocabulary segmentation benchmarks.
Dynamic Pyramid Network for Efficient Multimodal Large Language Model
Mar 26, 2025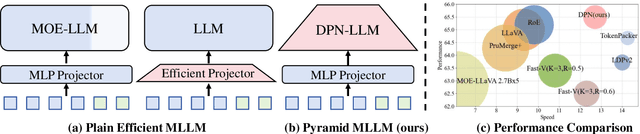

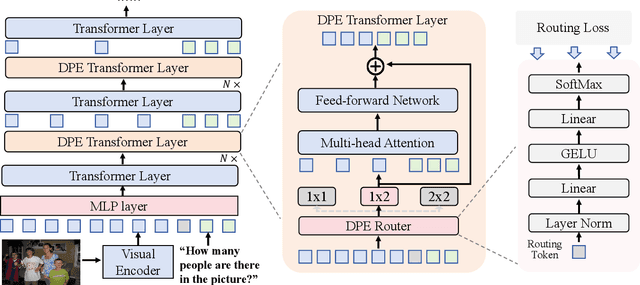

Multimodal large language models (MLLMs) have demonstrated impressive performance in various vision-language (VL) tasks, but their expensive computations still limit the real-world application. To address this issue, recent efforts aim to compress the visual features to save the computational costs of MLLMs. However, direct visual compression methods, e.g. efficient projectors, inevitably destroy the visual semantics in MLLM, especially in difficult samples. To overcome this shortcoming, we propose a novel dynamic pyramid network (DPN) for efficient MLLMs. Specifically, DPN formulates MLLM as a hierarchical structure where visual features are gradually compressed with increasing depth. In this case, even with a high compression ratio, fine-grained visual information can still be perceived in shallow layers. To maximize the benefit of DPN, we further propose an innovative Dynamic Pooling Experts (DPE) that can dynamically choose the optimal visual compression rate according to input features. With this design, harder samples will be assigned larger computations, thus preserving the model performance. To validate our approach, we conduct extensive experiments on two popular MLLMs and ten benchmarks. Experimental results show that DPN can save up to 56% average FLOPs on LLaVA while further achieving +0.74% performance gains. Besides, the generalization ability of DPN is also validated on the existing high-resolution MLLM called LLaVA-HR. Our source codes are anonymously released at https://github.com/aihao2000/DPN-LLaVA.
Graph Neural Networks-based Parameter Design towards Large-Scale Superconducting Quantum Circuits for Crosstalk Mitigation
Nov 25, 2024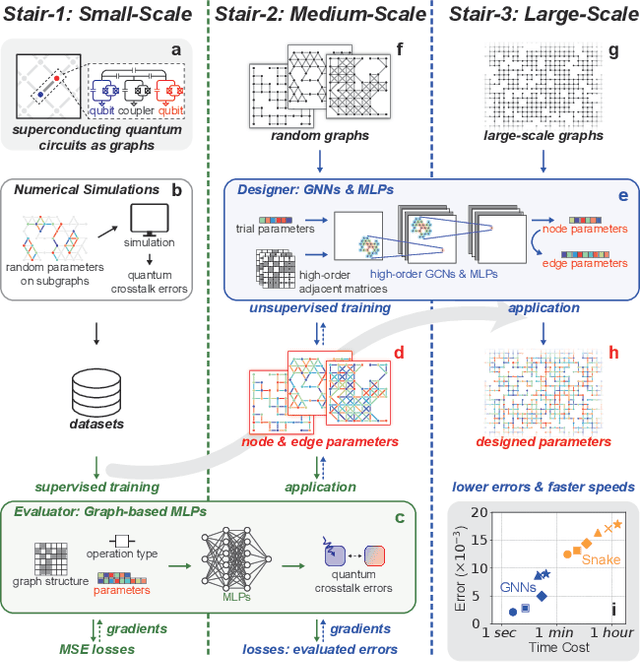
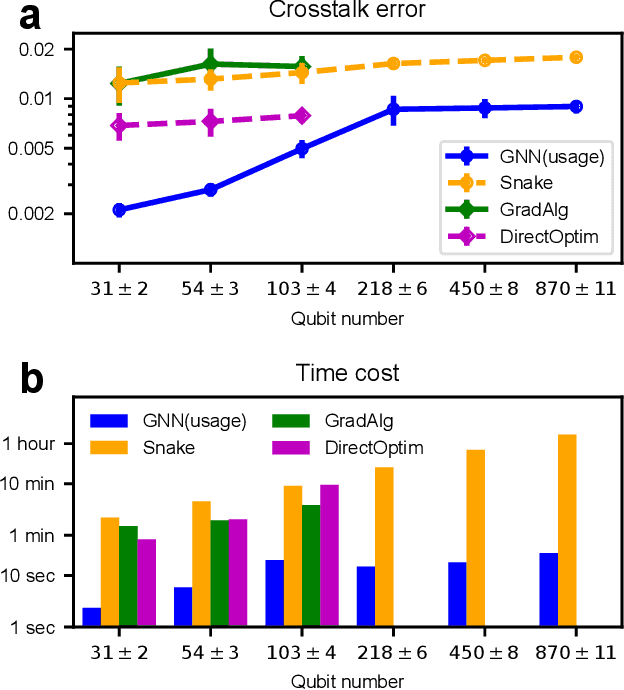
To demonstrate supremacy of quantum computing, increasingly large-scale superconducting quantum computing chips are being designed and fabricated, sparking the demand for electronic design automation in pursuit of better efficiency and effectiveness. However, the complexity of simulating quantum systems poses a significant challenge to computer-aided design of quantum chips. Harnessing the scalability of graph neural networks (GNNs), we here propose a parameter designing algorithm for large-scale superconducting quantum circuits. The algorithm depends on the so-called 'three-stair scaling' mechanism, which comprises two neural-network models: an evaluator supervisedly trained on small-scale circuits for applying to medium-scale circuits, and a designer unsupervisedly trained on medium-scale circuits for applying to large-scale ones. We demonstrate our algorithm in mitigating quantum crosstalk errors, which are commonly present and closely related to the graph structures and parameter assignments of superconducting quantum circuits. Parameters for both single- and two-qubit gates are considered simultaneously. Numerical results indicate that the well-trained designer achieves notable advantages not only in efficiency but also in effectiveness, especially for large-scale circuits. For example, in superconducting quantum circuits consisting of around 870 qubits, the trained designer requires only 27 seconds to complete the frequency designing task which necessitates 90 minutes for the traditional Snake algorithm. More importantly, the crosstalk errors using our algorithm are only 51% of those produced by the Snake algorithm. Overall, this study initially demonstrates the advantages of applying graph neural networks to design parameters in quantum processors, and provides insights for systems where large-scale numerical simulations are challenging in electronic design automation.
InstantIR: Blind Image Restoration with Instant Generative Reference
Oct 09, 2024



Handling test-time unknown degradation is the major challenge in Blind Image Restoration (BIR), necessitating high model generalization. An effective strategy is to incorporate prior knowledge, either from human input or generative model. In this paper, we introduce Instant-reference Image Restoration (InstantIR), a novel diffusion-based BIR method which dynamically adjusts generation condition during inference. We first extract a compact representation of the input via a pre-trained vision encoder. At each generation step, this representation is used to decode current diffusion latent and instantiate it in the generative prior. The degraded image is then encoded with this reference, providing robust generation condition. We observe the variance of generative references fluctuate with degradation intensity, which we further leverage as an indicator for developing a sampling algorithm adaptive to input quality. Extensive experiments demonstrate InstantIR achieves state-of-the-art performance and offering outstanding visual quality. Through modulating generative references with textual description, InstantIR can restore extreme degradation and additionally feature creative restoration.
CUBE360: Learning Cubic Field Representation for Monocular 360 Depth Estimation for Virtual Reality
Oct 08, 2024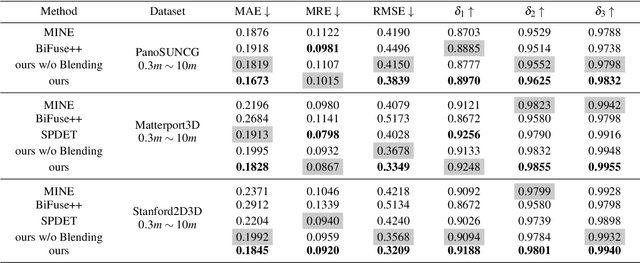
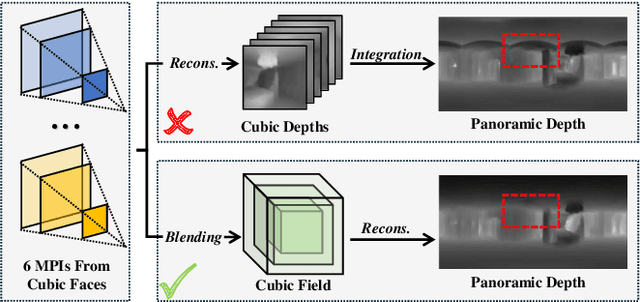

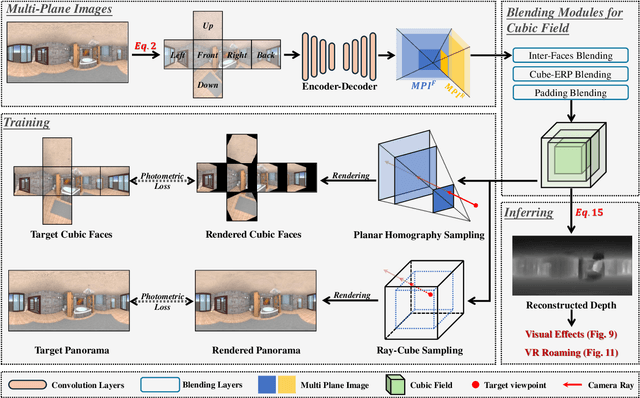
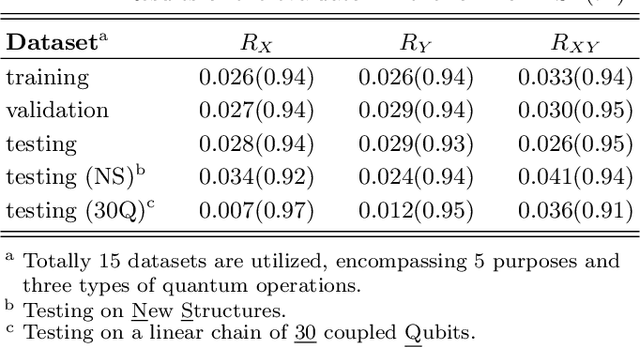
Panoramic images provide comprehensive scene information and are suitable for VR applications. Obtaining corresponding depth maps is essential for achieving immersive and interactive experiences. However, panoramic depth estimation presents significant challenges due to the severe distortion caused by equirectangular projection (ERP) and the limited availability of panoramic RGB-D datasets. Inspired by the recent success of neural rendering, we propose a novel method, named $\mathbf{CUBE360}$, that learns a cubic field composed of multiple MPIs from a single panoramic image for $\mathbf{continuous}$ depth estimation at any view direction. Our CUBE360 employs cubemap projection to transform an ERP image into six faces and extract the MPIs for each, thereby reducing the memory consumption required for MPI processing of high-resolution data. Additionally, this approach avoids the computational complexity of handling the uneven pixel distribution inherent to equirectangular projectio. An attention-based blending module is then employed to learn correlations among the MPIs of cubic faces, constructing a cubic field representation with color and density information at various depth levels. Furthermore, a novel sampling strategy is introduced for rendering novel views from the cubic field at both cubic and planar scales. The entire pipeline is trained using photometric loss calculated from rendered views within a self-supervised learning approach, enabling training on 360 videos without depth annotations. Experiments on both synthetic and real-world datasets demonstrate the superior performance of CUBE360 compared to prior SSL methods. We also highlight its effectiveness in downstream applications, such as VR roaming and visual effects, underscoring CUBE360's potential to enhance immersive experiences.
CSGO: Content-Style Composition in Text-to-Image Generation
Sep 04, 2024

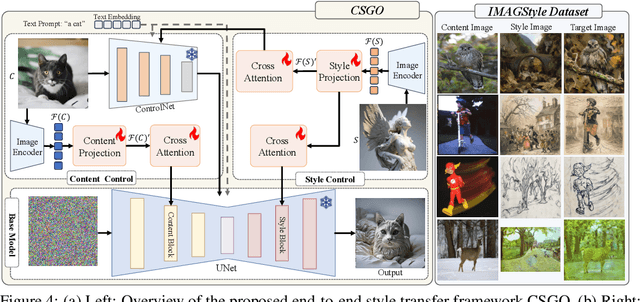
The diffusion model has shown exceptional capabilities in controlled image generation, which has further fueled interest in image style transfer. Existing works mainly focus on training free-based methods (e.g., image inversion) due to the scarcity of specific data. In this study, we present a data construction pipeline for content-style-stylized image triplets that generates and automatically cleanses stylized data triplets. Based on this pipeline, we construct a dataset IMAGStyle, the first large-scale style transfer dataset containing 210k image triplets, available for the community to explore and research. Equipped with IMAGStyle, we propose CSGO, a style transfer model based on end-to-end training, which explicitly decouples content and style features employing independent feature injection. The unified CSGO implements image-driven style transfer, text-driven stylized synthesis, and text editing-driven stylized synthesis. Extensive experiments demonstrate the effectiveness of our approach in enhancing style control capabilities in image generation. Additional visualization and access to the source code can be located on the project page: \url{https://csgo-gen.github.io/}.
Elite360M: Efficient 360 Multi-task Learning via Bi-projection Fusion and Cross-task Collaboration
Aug 18, 2024360 cameras capture the entire surrounding environment with a large FoV, exhibiting comprehensive visual information to directly infer the 3D structures, e.g., depth and surface normal, and semantic information simultaneously. Existing works predominantly specialize in a single task, leaving multi-task learning of 3D geometry and semantics largely unexplored. Achieving such an objective is, however, challenging due to: 1) inherent spherical distortion of planar equirectangular projection (ERP) and insufficient global perception induced by 360 image's ultra-wide FoV; 2) non-trivial progress in effectively merging geometry and semantics among different tasks to achieve mutual benefits. In this paper, we propose a novel end-to-end multi-task learning framework, named Elite360M, capable of inferring 3D structures via depth and surface normal estimation, and semantics via semantic segmentation simultaneously. Our key idea is to build a representation with strong global perception and less distortion while exploring the inter- and cross-task relationships between geometry and semantics. We incorporate the distortion-free and spatially continuous icosahedron projection (ICOSAP) points and combine them with ERP to enhance global perception. With a negligible cost, a Bi-projection Bi-attention Fusion module is thus designed to capture the semantic- and distance-aware dependencies between each pixel of the region-aware ERP feature and the ICOSAP point feature set. Moreover, we propose a novel Cross-task Collaboration module to explicitly extract task-specific geometric and semantic information from the learned representation to achieve preliminary predictions. It then integrates the spatial contextual information among tasks to realize cross-task fusion. Extensive experiments demonstrate the effectiveness and efficacy of Elite360M.
InstantStyle-Plus: Style Transfer with Content-Preserving in Text-to-Image Generation
Jun 30, 2024



Style transfer is an inventive process designed to create an image that maintains the essence of the original while embracing the visual style of another. Although diffusion models have demonstrated impressive generative power in personalized subject-driven or style-driven applications, existing state-of-the-art methods still encounter difficulties in achieving a seamless balance between content preservation and style enhancement. For example, amplifying the style's influence can often undermine the structural integrity of the content. To address these challenges, we deconstruct the style transfer task into three core elements: 1) Style, focusing on the image's aesthetic characteristics; 2) Spatial Structure, concerning the geometric arrangement and composition of visual elements; and 3) Semantic Content, which captures the conceptual meaning of the image. Guided by these principles, we introduce InstantStyle-Plus, an approach that prioritizes the integrity of the original content while seamlessly integrating the target style. Specifically, our method accomplishes style injection through an efficient, lightweight process, utilizing the cutting-edge InstantStyle framework. To reinforce the content preservation, we initiate the process with an inverted content latent noise and a versatile plug-and-play tile ControlNet for preserving the original image's intrinsic layout. We also incorporate a global semantic adapter to enhance the semantic content's fidelity. To safeguard against the dilution of style information, a style extractor is employed as discriminator for providing supplementary style guidance. Codes will be available at https://github.com/instantX-research/InstantStyle-Plus.
Elite360D: Towards Efficient 360 Depth Estimation via Semantic- and Distance-Aware Bi-Projection Fusion
Mar 25, 2024



360 depth estimation has recently received great attention for 3D reconstruction owing to its omnidirectional field of view (FoV). Recent approaches are predominantly focused on cross-projection fusion with geometry-based re-projection: they fuse 360 images with equirectangular projection (ERP) and another projection type, e.g., cubemap projection to estimate depth with the ERP format. However, these methods suffer from 1) limited local receptive fields, making it hardly possible to capture large FoV scenes, and 2) prohibitive computational cost, caused by the complex cross-projection fusion module design. In this paper, we propose Elite360D, a novel framework that inputs the ERP image and icosahedron projection (ICOSAP) point set, which is undistorted and spatially continuous. Elite360D is superior in its capacity in learning a representation from a local-with-global perspective. With a flexible ERP image encoder, it includes an ICOSAP point encoder, and a Bi-projection Bi-attention Fusion (B2F) module (totally ~1M parameters). Specifically, the ERP image encoder can take various perspective image-trained backbones (e.g., ResNet, Transformer) to extract local features. The point encoder extracts the global features from the ICOSAP. Then, the B2F module captures the semantic- and distance-aware dependencies between each pixel of the ERP feature and the entire ICOSAP feature set. Without specific backbone design and obvious computational cost increase, Elite360D outperforms the prior arts on several benchmark datasets.