 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong-Text-to-Image Generation via Compositional Prompt Decomposition
Apr 20, 2026While modern text-to-image (T2I) models excel at generating images from intricate prompts, they struggle to capture the key details when the inputs are descriptive paragraphs. This limitation stems from the prevalence of concise captions that shape their training distributions. Existing methods attempt to bridge this gap by either fine-tuning T2I models on long prompts, which generalizes poorly to longer lengths; or by projecting the oversize inputs into normal-prompt space and compromising fidelity. We propose Prompt Refraction for Intricate Scene Modeling (PRISM), a compositional approach that enables pre-trained T2I models to process long sequence inputs. PRISM uses a lightweight module to extract constituent representations from the long prompts. The T2I model makes independent noise predictions for each component, and their outputs are merged into a single denoising step using energy-based conjunction. We evaluate PRISM across a wide range of model architectures, showing comparable performances to models fine-tuned on the same training data. Furthermore, PRISM demonstrates superior generalization, outperforming baseline models by 7.4% on prompts over 500 tokens in a challenging public benchmark.
Dynamic Pyramid Network for Efficient Multimodal Large Language Model
Mar 26, 2025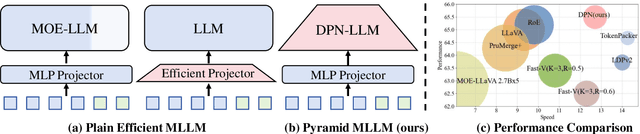

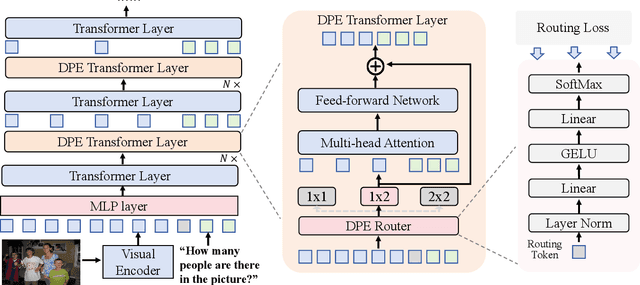

Multimodal large language models (MLLMs) have demonstrated impressive performance in various vision-language (VL) tasks, but their expensive computations still limit the real-world application. To address this issue, recent efforts aim to compress the visual features to save the computational costs of MLLMs. However, direct visual compression methods, e.g. efficient projectors, inevitably destroy the visual semantics in MLLM, especially in difficult samples. To overcome this shortcoming, we propose a novel dynamic pyramid network (DPN) for efficient MLLMs. Specifically, DPN formulates MLLM as a hierarchical structure where visual features are gradually compressed with increasing depth. In this case, even with a high compression ratio, fine-grained visual information can still be perceived in shallow layers. To maximize the benefit of DPN, we further propose an innovative Dynamic Pooling Experts (DPE) that can dynamically choose the optimal visual compression rate according to input features. With this design, harder samples will be assigned larger computations, thus preserving the model performance. To validate our approach, we conduct extensive experiments on two popular MLLMs and ten benchmarks. Experimental results show that DPN can save up to 56% average FLOPs on LLaVA while further achieving +0.74% performance gains. Besides, the generalization ability of DPN is also validated on the existing high-resolution MLLM called LLaVA-HR. Our source codes are anonymously released at https://github.com/aihao2000/DPN-LLaVA.
VisFactor: Benchmarking Fundamental Visual Cognition in Multimodal Large Language Models
Feb 23, 2025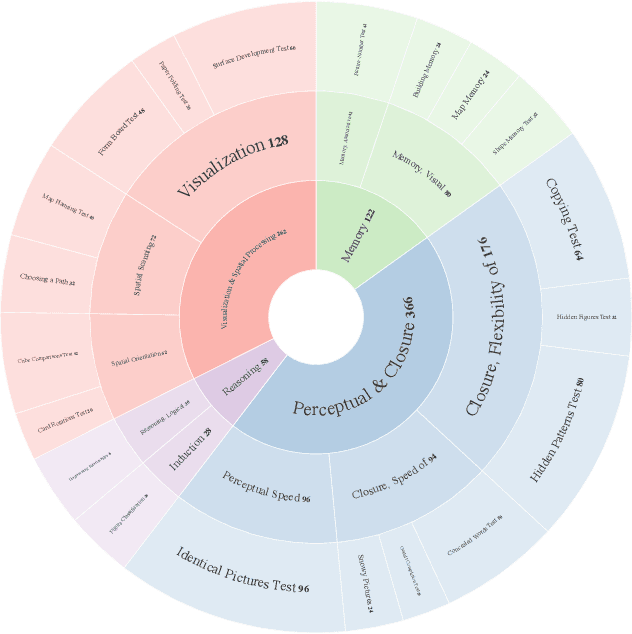
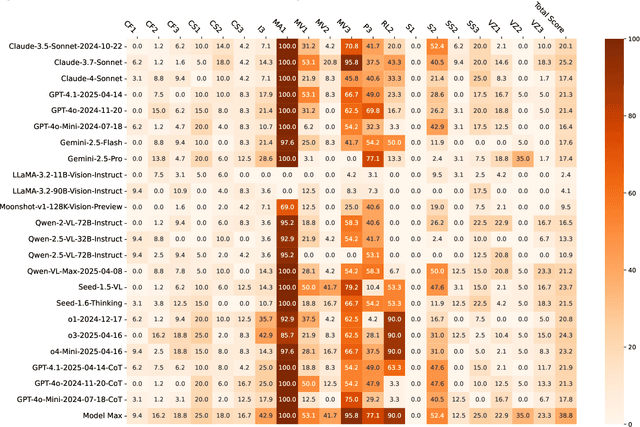
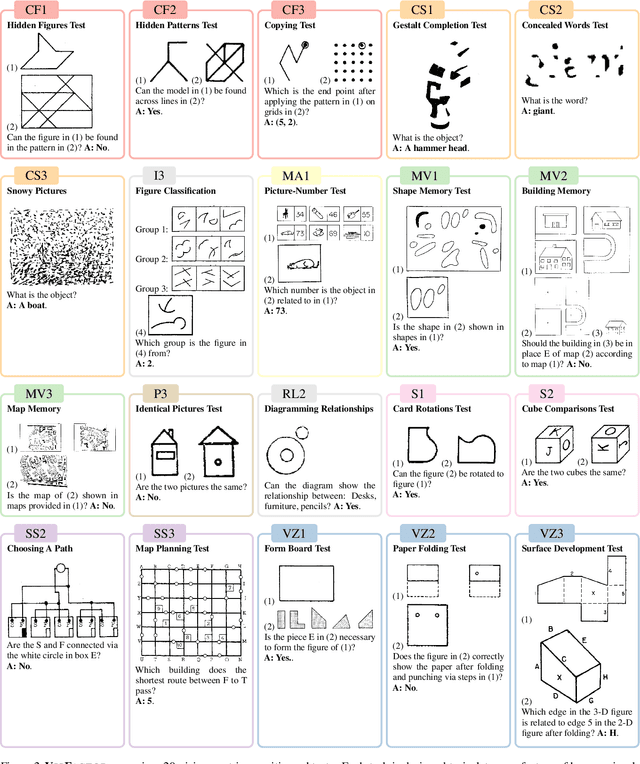

Multimodal Large Language Models (MLLMs) have demonstrated remarkable advancements in multimodal understanding; however, their fundamental visual cognitive abilities remain largely underexplored. To bridge this gap, we introduce VisFactor, a novel benchmark derived from the Factor-Referenced Cognitive Test (FRCT), a well-established psychometric assessment of human cognition. VisFactor digitalizes vision-related FRCT subtests to systematically evaluate MLLMs across essential visual cognitive tasks including spatial reasoning, perceptual speed, and pattern recognition. We present a comprehensive evaluation of state-of-the-art MLLMs, such as GPT-4o, Gemini-Pro, and Qwen-VL, using VisFactor under diverse prompting strategies like Chain-of-Thought and Multi-Agent Debate. Our findings reveal a concerning deficiency in current MLLMs' fundamental visual cognition, with performance frequently approaching random guessing and showing only marginal improvements even with advanced prompting techniques. These results underscore the critical need for focused research to enhance the core visual reasoning capabilities of MLLMs. To foster further investigation in this area, we release our VisFactor benchmark at https://github.com/CUHK-ARISE/VisFactor.
Optimizing Few-Step Sampler for Diffusion Probabilistic Model
Dec 14, 2024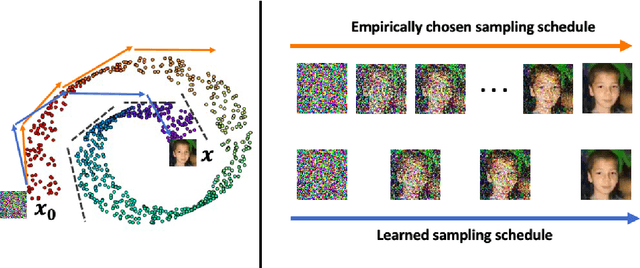

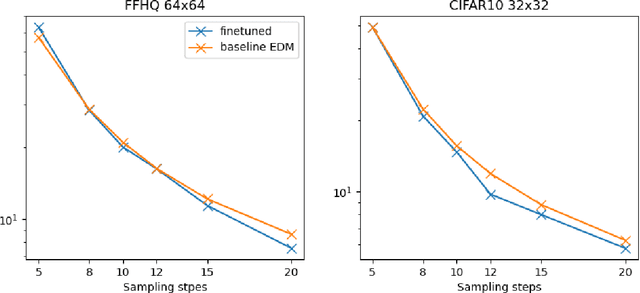
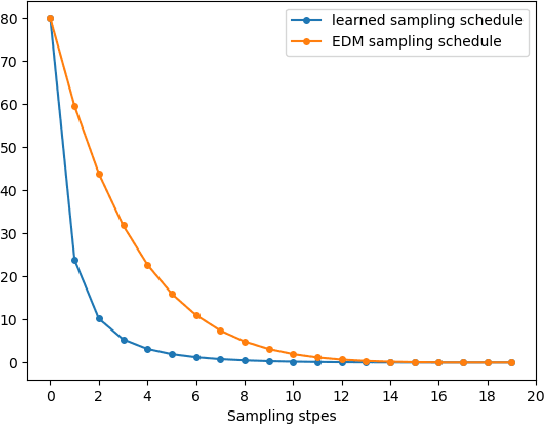
Diffusion Probabilistic Models (DPMs) have demonstrated exceptional capability of generating high-quality and diverse images, but their practical application is hindered by the intensive computational cost during inference. The DPM generation process requires solving a Probability-Flow Ordinary Differential Equation (PF-ODE), which involves discretizing the integration domain into intervals for numerical approximation. This corresponds to the sampling schedule of a diffusion ODE solver, and we notice the solution from a first-order solver can be expressed as a convex combination of model outputs at all scheduled time-steps. We derive an upper bound for the discretization error of the sampling schedule, which can be efficiently optimized with Monte-Carlo estimation. Building on these theoretical results, we purpose a two-phase alternating optimization algorithm. In Phase-1, the sampling schedule is optimized for the pre-trained DPM; in Phase-2, the DPM further tuned on the selected time-steps. Experiments on a pre-trained DPM for ImageNet64 dataset demonstrate the purposed method consistently improves the baseline across various number of sampling steps.
InstantIR: Blind Image Restoration with Instant Generative Reference
Oct 09, 2024



Handling test-time unknown degradation is the major challenge in Blind Image Restoration (BIR), necessitating high model generalization. An effective strategy is to incorporate prior knowledge, either from human input or generative model. In this paper, we introduce Instant-reference Image Restoration (InstantIR), a novel diffusion-based BIR method which dynamically adjusts generation condition during inference. We first extract a compact representation of the input via a pre-trained vision encoder. At each generation step, this representation is used to decode current diffusion latent and instantiate it in the generative prior. The degraded image is then encoded with this reference, providing robust generation condition. We observe the variance of generative references fluctuate with degradation intensity, which we further leverage as an indicator for developing a sampling algorithm adaptive to input quality. Extensive experiments demonstrate InstantIR achieves state-of-the-art performance and offering outstanding visual quality. Through modulating generative references with textual description, InstantIR can restore extreme degradation and additionally feature creative restoration.